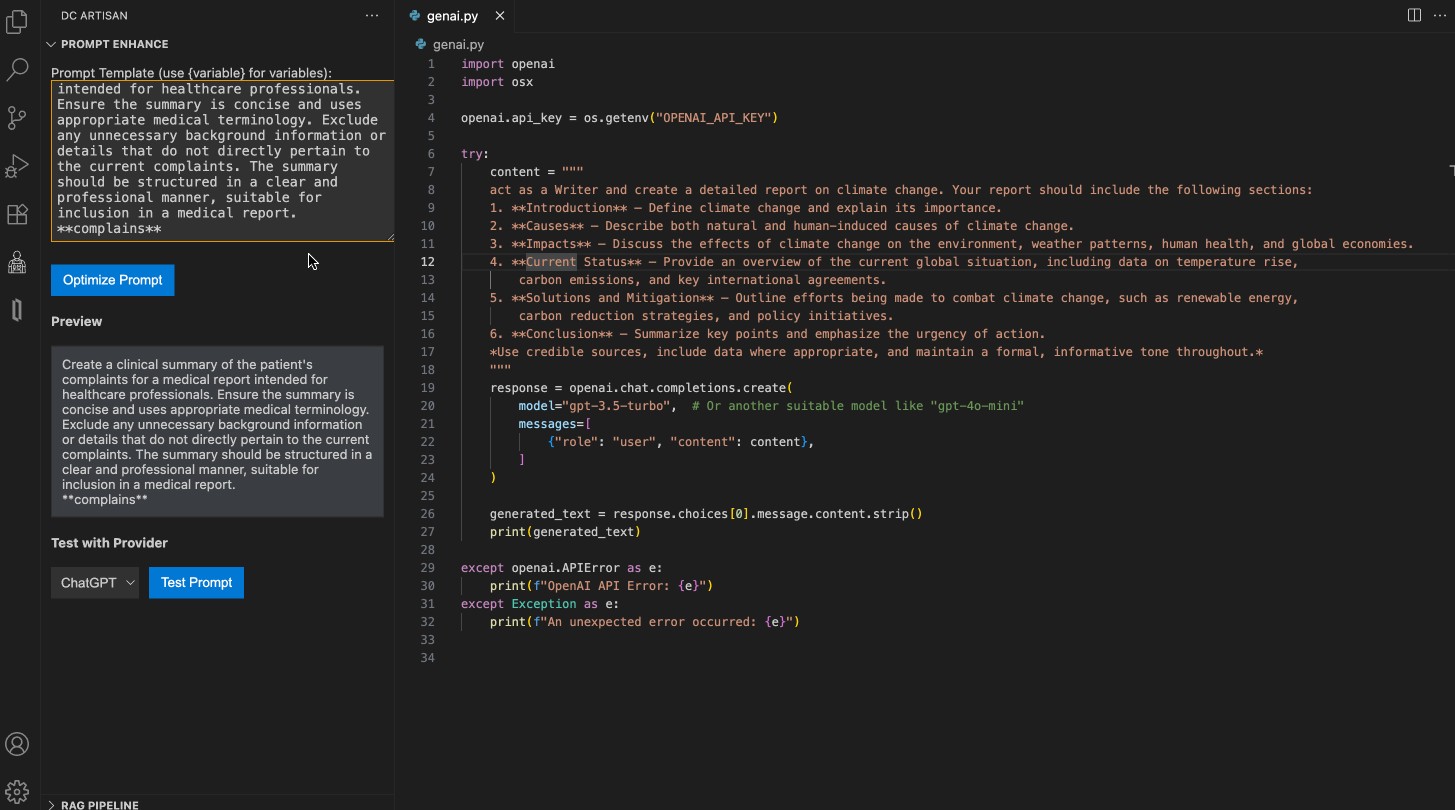
Introduction
Pour atteindre des performances optimisées en matière d'IA, une explicabilité robuste, une adaptabilité et une efficacité dans les solutions de santé, InterSystems IRIS sert de fondation centrale pour un projet au sein du cadre multi-agent x-rAI. Cet article offre une analyse approfondie de la manière dont InterSystems IRIS permet le développement d'une plateforme d'analyse de données de santé en temps réel, permettant des analyses avancées et des informations exploitables. La solution exploite les points forts d'InterSystems IRIS, notamment le SQL dynamique, les capacités natives de recherche vectorielle, la mise en cache distribuée (ECP) et l'interopérabilité FHIR. Cette approche innovante s'aligne directement sur les thèmes du concours « Utilisation du SQL dynamique et SQL intégré », « GenAI, recherche vectorielle » et « FHIR, DME », démontrant une application pratique d'InterSystems IRIS dans un contexte critique de santé.
Architecture du système
L'Agent Santé dans x-rAI repose sur une architecture modulaire intégrant plusieurs composants :
Couche d'ingestion des données : Récupère les données de santé en temps réel à partir de dispositifs portables via l'API Terra.
Couche de stockage des données : Utilise InterSystems IRIS pour stocker et gérer les données de santé structurées.
Moteur analytique : Exploite les capacités de recherche vectorielle d'InterSystems IRIS pour l'analyse de similarité et la génération d'informations.
Couche de mise en cache : Implémente la mise en cache distribuée via le protocole Enterprise Cache Protocol (ECP) d'InterSystems IRIS pour améliorer l'évolutivité.
Couche d'interopérabilité : Utilise les normes FHIR pour s'intégrer aux systèmes externes de santé comme les DME.
Voici un diagramme d'architecture à haut niveau :
text
[Dispositifs portables] --> [API Terra] --> [Ingestion des données] --> [InterSystems IRIS] --> [Moteur analytique]
------[Couche de mise en cache]------
----[Intégration FHIR]-----
Mise en œuvre technique
- Intégration des données en temps réel avec SQL dynamique
L'Agent Santé ingère des métriques de santé en temps réel (par exemple, fréquence cardiaque, pas effectués, heures de sommeil) depuis des dispositifs portables via l'API Terra. Ces données sont stockées dans InterSystems IRIS à l'aide du SQL dynamique pour une flexibilité dans la génération des requêtes.
Implémentation du SQL dynamique
Le SQL dynamique permet au système de construire adaptativement des requêtes basées sur les structures des données entrantes.
text
def index_health_data_to_iris(data):
conn = iris_connect()
if conn is None:
raise ConnectionError("Échec de la connexion à InterSystems IRIS.")
try:
with conn.cursor() as cursor:
query = """
INSERT INTO HealthData (user_id, heart_rate, steps, sleep_hours)
VALUES (?, ?, ?, ?)
"""
cursor.execute(query, (
data['user_id'],
data['heart_rate'],
data['steps'],
data['sleep_hours']
))
conn.commit()
print("Données indexées avec succès dans IRIS.")
except Exception as e:
print(f"Erreur lors de l'indexation des données : {e}")
finally:
conn.close()
Avantages du SQL dynamique
Permet une construction flexible des requêtes basée sur les schémas des données entrantes.
Réduit la charge de développement en évitant les requêtes codées en dur.
Facilite l'intégration transparente de nouvelles métriques sans modifier le schéma de la base.
- Analytique avancée avec recherche vectorielle
Le type natif vector et les fonctions de similarité d'InterSystems IRIS ont été utilisés pour effectuer une recherche vectorielle sur les données de santé. Cela permet au système d’identifier les dossiers historiques similaires aux métriques actuelles d’un utilisateur.
Flux de travail pour la recherche vectorielle
Convertir les métriques de santé (par exemple, fréquence cardiaque, pas effectués, heures de sommeil) en une représentation vectorielle.
Stocker ces vecteurs dans une colonne dédiée dans la table HealthData.
Effectuer des recherches basées sur la similarité à l'aide de VECTOR_SIMILARITY().
Requête SQL pour la recherche vectorielle
text
SELECT TOP 3 user_id, heart_rate, steps, sleep_hours,
VECTOR_SIMILARITY(vec_data, ?) AS similarity
FROM HealthData
ORDER BY similarity DESC;
Intégration Python
text
def iris_vector_search(query_vector):
conn = iris_connect()
if conn is None:
raise ConnectionError("Échec de la connexion à InterSystems IRIS.")
try:
with conn.cursor() as cursor:
query_vector_str = ",".join(map(str, query_vector))
sql = """
SELECT TOP 3 user_id, heart_rate, steps, sleep_hours,
VECTOR_SIMILARITY(vec_data, ?) AS similarity
FROM HealthData
ORDER BY similarity DESC;
"""
cursor.execute(sql, (query_vector_str,))
results = cursor.fetchall()
return results
except Exception as e:
print(f"Erreur lors de la recherche vectorielle : {e}")
return []
finally:
conn.close()
Avantages de la recherche vectorielle
Permet des recommandations personnalisées grâce à l’identification des tendances historiques.
Améliore l’explicabilité en reliant les métriques actuelles à des cas passés similaires.
Optimisé pour des analyses rapides grâce aux opérations SIMD (Single Instruction Multiple Data).
- Mise en cache distribuée pour l’évolutivité
Pour gérer efficacement le volume croissant des données, l’Agent Santé utilise le protocole Enterprise Cache Protocol (ECP) d’InterSystems IRIS. Ce mécanisme réduit la latence et améliore l’évolutivité.
Caractéristiques clés
Mise en cache locale sur les serveurs applicatifs pour minimiser les requêtes vers la base centrale.
Synchronisation automatique garantissant la cohérence entre tous les nœuds du cache.
Évolutivité horizontale permettant l’ajout dynamique de serveurs applicatifs.
Avantages du caching
Réduction des temps de réponse grâce à la mise en cache locale.
Amélioration de l’évolutivité grâce à la répartition des charges entre plusieurs nœuds.
Réduction des coûts d’infrastructure grâce à une moindre sollicitation du serveur central.
- Intégration FHIR pour l’interopérabilité
Le support d’InterSystems IRIS pour FHIR (Fast Healthcare Interoperability Resources) garantit une intégration fluide avec les systèmes externes comme les DME.
Flux FHIR
Les données issues des dispositifs portables sont transformées en ressources compatibles FHIR (par exemple Observation, Patient).
Ces ressources sont stockées dans InterSystems IRIS et accessibles via des API RESTful.
Les systèmes externes peuvent interroger ou mettre à jour ces ressources via des points d’accès standard FHIR.
Avantages
Assure la conformité avec les normes d’interopérabilité en santé.
Facilite un échange sécurisé des données entre systèmes.
Permet une intégration avec les flux et applications existants dans le domaine médical.
IA explicable grâce aux informations en temps réel
En combinant les capacités analytiques d’InterSystems IRIS avec le cadre multi-agent x-rAI, l’Agent Santé génère des informations exploitables et explicables. Par exemple :
« L’utilisateur 123 avait des métriques similaires (Fréquence cardiaque : 70 bpm ; Pas : 9 800 ; Sommeil : 7 h). Sur la base des tendances historiques, il est recommandé de maintenir vos niveaux actuels d’activité. »
Cette transparence renforce la confiance dans les applications IA dédiées à la santé en offrant un raisonnement clair derrière chaque recommandation.
Conclusion
L’intégration d’InterSystems IRIS dans l’Agent Santé du cadre x-rAI illustre son potentiel comme plateforme robuste pour construire des systèmes IA intelligents et explicables dans le domaine médical. En exploitant le SQL dynamique, la recherche vectorielle, la mise en cache distribuée et l’interopérabilité FHIR, ce projet fournit des informations exploitables et transparentes—ouvrant ainsi la voie à des applications IA plus fiables dans des domaines critiques comme celui de la santé.
.jpg)



.png)
.png)
.png)
.png)
.png)


.png)
.jpg)
.png)
.png)
.png)
.png)
.png)
.png)

.png)