Index
Partie 1
- Présentation de Flask : une revue rapide des documents de Flask (Flask Docs), où vous trouverez toutes les informations dont vous avez besoin pour ce tutoriel;
- Connexion à InterSystems IRIS : un guide détaillé étape par étape sur l'utilisation de SQLAlchemy pour se connecter à une instance d'IRIS;
Partie 2
- Discussion sur cette forme de mise en œuvre : pourquoi nous devrions l'utiliser et les situations où elle est applicable.
- L'application OpenExchange : si vous n'êtes pas intéressé par le développement de cet exemple, vous pouvez passer directement à cette section et apprendre à l'utiliser comme modèle pour votre application flask-iris.
- Bonus : quelques erreurs commises lors du développement et comment je les ai résolues.
Présentation de Flask
Flask est un outil web écrit en Python et conçu pour vous faciliter la vie lors de la création d'une application web. Il utilise Werkzeug pour gérer l'interface Web Server Gateway Interface (WSGI) - la spécification standard de Python pour la communication avec les serveurs web. Il utilise également Jinja pour gérer les modèles HTML, et le Click CLI toolkit pour créer et gérer le code d'interface de ligne de commande.
Installation
La première étape est facultative. Cependant, c'est une bonne idée de configurer un environnement virtuel avant de commencer des projets. Vous pouvez le faire sur le terminal en modifiant le répertoire vers le dossier que vous voulez utiliser comme racine et en tapant la commande mentionnée ci-dessous.
> python -m venv .venv
Si vous optez pour un environnement virtuel, activez-le avec la commande suivante (sous Windows) avant d'installer les prérequis :
> .venv\Scripts\activate
Enfin, installez les paquets avec pip (paquetage d'installation Python).
> pip install Flask
> pip install Flask-SQLAlchemy
> pip install sqlalchemy-iris
Quickstart
Nous suivrons la structure présentée dans ce Tutoriel, en adaptant les connexions à l'IRIS. Cela minimisera vos problèmes lors de l'amélioration de votre application puisque vous pourrez consulter la Documentation de Flask sans conflits. Cependant, comme Flask est très flexible, il ne vous oblige pas à suivre des modèles, et vous pouvez considérer les étapes suivantes comme de simples suggestions.
L'approche présentée ici consiste à utiliser les applications comme des paquets et à définir une fabrique d'applications pour couvrir les grands projets. Cependant, vous pouvez toujours construire l'application Flask avec cinq lignes de code seulement, comme on le voit ci-dessous.
from flask import Flask
app = Flask(__name__)
@app.route('/')defhello():return'Hello, world!'
Une application modèle
Cette section présente les étapes à suivre pour créer l'application flask-iris. Ce tutoriel peut être suivi si vous n'avez jamais utilisé de framework web auparavant. Cependant, si vous voulez vraiment comprendre la théorie de ce type de flux de travail, lisez mon article précédent sur Exemples de travail avec IRIS à partir de Django, en prenant particulièrement en compte l'image au début de l'article. Vous constaterez avec satisfaction que les différents frameworks web ont une logique très similaire. Cependant, dans Flask, nous pouvons définir les URL et les vues ensemble en tant que groupes, appelés plans originaux (blueprints).
TLes conditions requises concernent Flask, Flask-SQLAlchemy et sqlalchemy-iris. Intuitivement, le pont entre l'application web et votre instance IRIS est construit !
Le paquet
Tout d'abord, créez ou sélectionnez le dossier que vous souhaitez utiliser comme racine. Appelons-le flaskr-iris. Nous avons besoin que Python comprenne ce dossier comme un paquet, nous devons donc créer un fichier __init_.py. C'est là que nous placerons notre fabrique d'applications.
Étape 1 - Création de la fabrique d'applications
La fabrique d'applications n'est rien de plus qu'une fonction. A l'intérieur de celle-ci, nous devons définir une instance Flask() (l'application), définir ses configurations, la connecter à la base de données, et enregistrer les blueprints si nous choisissons de les utiliser. Nous allons explorer plus en détail les blueprints plus tard, donc pour l'instant vous n'avez pas besoin de vous en préoccuper.
Cette fonction doit être appelée create_app(). Commencez par importer Flask et créez une instance avec l'argument \N_nom\N_ (consultez la documentation pour plus de détails). Ensuite, mappez la propriété config avec une clé secrète et l'URI de la base de données. Utilisez le format "dialect://username:password@host:port/NAMESPACE", en suivant les recommandations de SQLAlchemy. Dans ce cas, le dialecte devrait être 'iris', créé par CaretDev. Le nom d'utilisateur et le mot de passe sont ceux que vous utilisez pour vous connecter à l'instance InterSystems IRIS indiquée par l'hôte et le port, et l'espace de noms parle de lui-même.
from flask import Flask
defcreate_app():
app - Flask(__name__, instance_relative_config=True)
app.config.from_mapping(
SECRET_KEY = "dev",
SQLALCHEMY_DATABSE_URI = "iris://_SYSTEM:sys@loclhost:1972/SAMPLE"
)
Les prochaines lignes de notre fabrique auront besoin de la base de données, alors réservons ce fichier pour un instant pendant que nous parlons de données et de modèles.
Étape 2 - Gestion des données
Nous utiliserons SQLAlchemy pour importer et gérer les données puisque nous pouvons utiliser Flask-SQLAlchemy et SQLAlchemy-IRIS pour résoudre les problèmes de connexion. Tout d'abord, il faut créer le fichier database.py dans lequel nous importerons la version Flask de SQLAlchemy et l'instancierons. Cette étape ne nécessite pas de fichier séparé. Cependant, elle peut être très utile plus tard pour développer d'autres méthodes pour gérer la base de données.
from flask_sqlalchemy import SQLAlchemy
db = SQLAlchemy()
Ensuite, il faut définir les modèles qui indiqueront à Python comment interpréter chaque enregistrement dans un tableau. Créez le fichier models.py, importez l'instance de SQLAlchemy et les fonctionnalités dont vous avez besoin pour traiter les données. En suivant l'exemple donné dans la documentation officielle de Flask, nous pouvons créer un blog nécessitant un modèle pour les utilisateurs et un autre pour les messages. Cette implémentation couvre un nombre substantiel de cas et vous donne une bonne longueur d'avance.
Nous allons utiliser le Mapping Objet-Relationnel (ORM) comme suggéré dans SQLAlchemy 2.0, en définissant des colonnes mappées et une relation de type Un-à-plusieurs (One-to-many). Vous pouvez vérifier comment modéliser d'autres types de relations dans le Guide de SQLAlchemy.
from .database import db
from sqlalchemy.orm import Mapped, mapped_column
from typing import List, Optional
import datetime
classUser(db.Model):
id: Mapped[int] = mapped_column(db.Integer, primary_key=True)
username: Mapped[str] = mapped_column(db.String(1000), unique=True, nullable=False)
password: Mapped[str] = mapped_column(db.String(1000), nullable=False)
posts: Mapped[List["Post"]] = db.relationship(back_populates="user")
classPost(db.Model):
id: Mapped[int] = mapped_column(db.Integer, primary_key=True)
author_id: Mapped[int] = mapped_column(db.Integer, db.ForeignKey('user.id'), nullable=False)
user: Mapped["User"] = db.relationship(back_populates="posts")
created: Mapped[datetime.datetime] = mapped_column(db.DateTime, nullable=False, server_default=db.text('CURRENT_TIMESTAMP'))
title: Mapped[str] = mapped_column(db.String(1000), nullable=False)
body: Mapped[Optional[str]] = mapped_column(db.String(1000000))
Le format général à utiliser pour définir les colonnes dans la dernière version de SQLAlchemy est le suivant :
columnName: Mapped[type] = mapped_column(db.Type, arguments)
En ce qui concerne les relations, du côté des "nombreux", vous devrez également définir la clé étrangère.
Obs.: les noms des classes seront convertis de "CamelCase" en "snake_case" lors de la création des tableaux SQL.
Enfin, nous pouvons retourner à la fabrique sur _init_.py_ et faire les connexions. Importez la base de données et les modèles, assignez cette application à l'instance db, et créez toutes les tableaux à l'intérieur de la méthode create_app().
from flask import Flask
from sqlalchemy.exc import DatabaseError
defcreate_app():
app = Flask(__name__)
app.config.from_mapping(
SECRET_KEY="dev",
SQLALCHEMY_DATABASE_URI = "iris://_SYSTEM:sys@localhost:1972/SAMPLE"
)
from .database import db
from .models import User, Post
db.init_app(app)
try:
with app.app_context():
db.create_all()
except DatabaseError as err:
if'already exists'in err._sql_message():
print("Databases already exist.")
else:
print(err)
Ensuite, nous passerons à la création des vues.
Étape 3 - Les vues
Étape 3.1 - Les blueprints : l'authentification
Un objet Blueprint a été conçu pour organiser vos vues en groupes et les enregistrer dans l'application. Nous allons créer un Blueprint pour les vues qui traitent de l'authentification et un autre pour l'affichage, l'édition et la suppression, de sorte que cette partie du tutoriel couvrira la gestion CRUD et la gestion des sessions.
En commençant par le Blueprint d'authentification, créez le fichier auth.py et importez les utilitaires de Flask et Werkzeug, la base de données et le modèle Utilisateur. Ensuite, instanciez l'objet Blueprint, en spécifiant son nom et le préfixe de l'URL.
from flask import (
Blueprint, request, g, redirect, url_for, flash, render_template, session
)
from werkzeug.security import generate_password_hash, check_password_hash
from .database import db
from .models import User
import functools
bp = Blueprint('auth', __name__, url_prefix='/auth')
Ensuite, nous pouvons utiliser des décorateurs pour définir des chemins pour l'enregistrement, la connexion et la déconnexion avec toutes les méthodes nécessaires. Dans notre exemple, nous utiliserons GET et POST et commencerons par l'enregistrement.
Le décorateur est accessible comme une méthode de notre Blueprint et possède un argument pour l'URL et un autre pour les méthodes qu'il accepte. À la ligne suivante, créez la fonction indiquant à l'application ce qu'elle doit faire lorsqu'elle reçoit une requête avec les paramètres correspondants. Dans l'exemple suivant, nous aurons accès à la fonction en GETtant ou POSTant l'URL http://host:port/auth/register.
@bp.route('/register', methods=('GET', 'POST'))defregister():if request.method=='POST':
pass
Si l'application reçoit un POST renvoyant à '/register', cela signifie qu'un utilisateur souhaite créer un compte. L'accès au nom d'utilisateur et au mot de passe choisis avec l'objet de contenu de la demande est géré par Flask. Ensuite, créez une instance du modèle Utilisateur, en stockant ses propriétés en tant que valeurs reçues. Vous pouvez également utiliser les méthodes werkzeug.security pour protéger le contenu sensible. Ensuite, utilisez la propriété de session de notre base de données, fournie par SQLAlchemy, pour ajouter un nouvel utilisateur au tableau et le valider. À ce stade, les informations ont déjà été envoyées au tableau correspondant dans l'instance IRIS mentionnée à la dernière étape. Enfin, redirigez l'utilisateur vers la page de connexion, que nous créerons à l'étape suivante. N'oubliez pas de traiter les erreurs telles que la réception d'entrées vides, l'intégrité de l'index et la connexion à la base de données. Vous pouvez utiliser flash() pour afficher les détails du problème à l'utilisateur. Nous pouvons également utiliser la même fonction register() pour rendre le modèle de la page d'enregistrement si GET est utilisé dans la requête.
@bp.route('/register', methods=('GET', 'POST'))defregister():if request.method=='POST':
username = request.form['username']
password = request.form['password']
error = Noneifnot username:
error = "Username is required."elifnot password:
error = "Password is required."if error isNone:
try:
user = User(
username=username,
password=generate_password_hash(password)
)
db.session.add(user)
db.session.commit()
except Exception as err:
error = str(err)
else:
return redirect(url_for("auth.login"))
flash(error)
return render_template('auth/register.html')
Ensuite, nous répétons la même logique pour la page de connexion. Lorsque nous traitons un POST, nous recevons d'abord un nom d'utilisateur et un mot de passe, puis nous vérifions s'ils existent dans notre tableau IRIS. Cette fois, nous n'utiliserons pas la propriété session (bien que nous aurions pu le faire). Nous utiliserons plutôt la méthode one_or_404(). Nous devons le faire parce que le nom d'utilisateur doit être unique, comme nous l'avons défini dans notre modèle. Ainsi, si la requête ne renvoie pas précisément une ligne suite à notre demande, nous pouvons la considérer comme non trouvée. À l'intérieur de cette fonction, enchaîner des commandes SQL pour trouver le résultat requis, en utilisant les modèles comme des tableaux et leurs propriétés comme des colonnes. Enfin, on efface la session de Flask, on ajoute l'utilisateur si la connexion a été effective et on le redirige vers la page d'accueil. S'il s'agit d'un GET, envoyer l'utilisateur à la page de connexion.
@bp.route('/login', methods=('GET', 'POST'))deflogin():if request.method=="POST":
username = request.form['username']
password = request.form['password']
error = Nonetry:
user = db.one_or_404(db.select(User).where(User.username==username))
ifnot check_password_hash(user.password, password):
error = "Incorrect password"except Exception as err:
error = f"User {username} not found."if error isNone:
session.clear()
session['user_id'] = user.id
return redirect(url_for('index'))
flash(error)
return render_template('auth/login.html')
Pour se déconnecter, il suffit d'effacer la session et de rediriger vers la page d'accueil.
@bp.route('/logout')deflogout():
session.clear()
return redirect(url_for('index'))
Pour les fonctions suivantes, nous allons traiter l'utilisateur qui se connecte sur différentes requêtes, qui ne sont pas nécessairement liées à l'authentification. L'objet 'g' de Flask est unique pour chaque demande, ce qui signifie que vous pouvez l'utiliser pour définir l'utilisateur actuel à partir de la base de données lorsque vous traitez des accès éventuellement interdits.
Heureusement, le Blueprint possède la propriété before_app_request. Elle peut être utilisée comme décorateur suivi d'une fonction pour déterminer ce qu'il convient de faire lors de la réception d'une requête avant de la traiter. Pour charger l'utilisateur connecté, nous devons à nouveau nous connecter, mais cette fois, nous obtiendrons des informations à partir de la session autres que la requête.
@bp.before_app_requestdefload_logged_in_user():
user_id = session.get('user_id')
if user_id isNone:
g.user = Noneelse:
g.user = db.one_or_404(
db.select(User).where(User.id==user_id)
)
Enfin, pour notre dernière fonction d'authentification, il est possible de créer quelque chose qui traitera les vues qui doivent être interdites si l'utilisateur ne s'est pas connecté. Si vous ne voulez pas afficher un simple code 403, redirigez l'utilisateur vers la page de connexion.
deflogin_required(view): @functools.wraps(view)defwrapped_view(**kwargs):if session.get('user_id') isNone:
return redirect(url_for('auth.login'))
return view(**kwargs)
return wrapped_view
Étape 3.2 - Les blueprints: blog (CRUD)
Là encore, commencez par créer le fichier (appelons-le blog.py) et y importer tout ce qui est nécessaire. Cela peut sembler beaucoup de travail, mais chacune de ces importations prendra tout son sens au fur et à mesure que nous avancerons. Créez également une autre instance de Blueprint.
from flask import (
Blueprint, flash, g, redirect, render_template, request, url_for, session
)
from werkzeug.exceptions import abort
from .auth import login_required
from .database import db
from .models import Post, User
from sqlalchemy import desc
bp = Blueprint('blog', __name__)
Tout d'abord, il faut commencer par créer l'URL par défaut, qui pointe vers la page d'accueil. Ici, nous afficherons les messages stockés dans IRIS, de sorte que la propriété de session de la base de données (qui est une instance SQLAlchemy() de Flask-SQLAlchemy) puisse être utilisée. Il y a plusieurs façons d'exécuter une requête avec le module SQLAlchemy. J'ai choisi d'utiliser la fonction scalars() avec la requête SQL comme argument, enchaînée avec la fonction all(). Vous avez peut-être vu un comportement similaire dans d'autres langages et plugins comme fetchall(). La prochaine étape sera de rendre le modèle de la page d'accueil, en passant la variable où nous avons stocké tous les messages comme argument afin de pouvoir y accéder dans les fichiers HTML. Regardez notre READ (cRud) ci-dessous :
@bp.route('/')defindex():
posts = db.session.scalars(
db.select(Post).order_by(desc(Post.created))
).all()
return render_template('blog/index.html', posts=posts)
Ensuite, la fonction de création (Crud) d'un nouveau message sera très similaire à l'enregistrement d'un utilisateur. Nous obtenons l'entrée de l'utilisateur à partir de la requête, définissons ses valeurs en fonction des propriétés du modèle de message Post, utilisons l'objet session de la base de données pour faire un ajout (équivalent à l'instruction SQL d'insertion) et validons. Ici, nous allons accéder à l'utilisateur actuel à partir de la requête avec l'objet g. Nous utiliserons également un second décorateur, référençant la fonction login_required(), pour rediriger l'utilisateur vers la page de connexion s'il ne s'est pas encore connecté.
@bp.route('/create', methods=('GET', 'POST'))@login_requireddefcreate():if request.method == 'POST':
title = request.form['title']
body = request.form['body']
error = Noneifnot title:
error = 'Title is required.'if error isnotNone:
flash(error)
else:
post = Post(
title=title,
body=body,
author_id=g.user.id
)
db.session.add(post)
db.session.commit()
return redirect(url_for('blog.index'))
return render_template('blog/create.html')
Pour effectuer une mise à jour (crUd), nous utiliserons une approche très similaire. Cependant, au lieu de créer une nouvelle instance de Post, nous la renverrons à partir d'une requête, puisqu'elle existe déjà dans la base de données. Nous pouvons utiliser l'URL pour recevoir un identifiant pour le message (Post). Une fois de plus, le login est nécessaire ici.
@bp.route('//update', methods=('GET', 'POST'))@login_requireddefupdate(id):
post = get_post(id)
if request.method == 'POST':
title = request.form['title']
body = request.form['body']
error = Noneifnot title:
error = 'Title is required.'if error isnotNone:
flash(error)
else:
post.title = title
post.body = body
db.session.commit()
return redirect(url_for('blog.index'))
return render_template('blog/update.html', post=post)
Puisque pour la suppression il nous faudra également accéder au message (Post) par l'ID, nous pouvons créer une fonction get_post(id) et l'utiliser sur les deux vues. De la même manière que pour les autres requêtes que nous avons faites jusqu'à présent, nous pouvons enchaîner les commandes SQL pour l'écrire. Puisque notre modèle pour l'utilisateur a une relation, nous pouvons sélectionner le message Post et le joindre à Utilisateur (User). De cette manière, nous pourrons accéder aux informations de l'utilisateur par le biais de l'objet résultat. Nous pouvons également utiliser abort() pour envoyer des réponses 404 (non trouvé) et 403 (interdit).
defget_post(id, check_author=True):
post = db.one_or_404(
db.select(Post).join(User).where(Post.id == id)
)
if post isNone:
abort(404, f"Post id {id} doesn't exist.")
if check_author and post.author_id != session['user_id']:
abort(403)
return post
Enfin, vous pouvez effectuer la suppression en utilisant simplement une fonction de suppression de la session de la base de données.
@bp.route('//delete', methods=('POST',))@login_requireddefdelete(id):
post = get_post(id)
db.session.delete(post)
db.session.commit()
return redirect(url_for('blog.index'))
Étape 3.3 - Enregistrer vos blueprints
Enfin, nous pouvons achever notre fabrique d'applications en enregistrant les blueprints et en renvoyant l'application, comme indiqué ci-dessous.
from flask import Flask
from sqlalchemy.exc import DatabaseError
defcreate_app():
app = Flask(__name__)
app.config.from_mapping(
SECRET_KEY="dev",
SQLALCHEMY_DATABASE_URI = "iris://_SYSTEM:sys@localhost:1972/SAMPLE"
)
from .database import db
from .models import User, Post
db.init_app(app)
try:
with app.app_context():
db.create_all()
except DatabaseError as err:
if'already exists'in err._sql_message():
print("Databases already exist.")
else:
print(err)
from . import auth
app.register_blueprint(auth.bp)
from . import blog
app.register_blueprint(blog.bp)
app.add_url_rule('/', endpoint='index')
return app
Étape 4 - Les modèles
Vous devez avoir remarqué que chaque vue se termine par un retour redirect(), qui envoie l'utilisateur vers une autre vue ou renvoie render_template(), ce qui est explicite. Ces fonctions reçoivent des modèles HTML comme arguments, ainsi que tout autre objet que vous pourriez vouloir utiliser à l'intérieur. Cela signifie qu'à ce stade du tutoriel, vous apprendrez à accéder à votre base de données IRIS à partir d'un fichier HTML, ce qui vous permettra de gérer les données avec CSS et JavaScript, et d'évoluer vers d'autres outils de développement web.
Le chemin par défaut de votre application Flask intégrée dans un paquetage pour rechercher des modèles se trouve dans le dossier app/templates. À l'intérieur de ce dossier, il est d'usage d'ajouter un fichier base.html. Le modèle de ces fichiers est le Jinja's. Cela signifie que vous pouvez utiliser {% ... %} pour ajouter des instructions telles que des blocs, des "ifs" (si) et des "fors" (pour), en les terminant toujours (avec {% endblock %}, par exemple). Vous pouvez également utiliser {{ ... }} pour des expressions telles que l'accès aux objets que vous avez passés dans la fonction de rendu du modèle. Enfin, vous pouvez utiliser {# ... #} pour les commentaires.
Outre les arguments passés dans les vues, vous pouvez accéder à des contextes tels que l'objet g, qui est unique pour chaque requête, et get_flashed_messages() pour afficher les arguments passés dans flash(). Étant donné que nous avons déjà vu dans les étapes précédentes comment effectuer des requêtes et passer le résultat dans le contexte de la requête, l'exemple suivant pour un fichier de base vous montrera comment accéder aux données d'IRIS en utilisant l'objet g. En plus de cela, l'exemple montrera également comment accéder aux données d'IRIS en utilisant l'objet g. En outre, il montre également comment afficher les messages flashés.
<!DOCTYPE html><title>{% block title %}{% endblock %} - Flaskr</title><linkrel="stylesheet"href="{{ url_for('static', filename='style.css') }}"><nav><h1>Flaskr</h1><ul>
{% if g.user %}
<li><span>{{ g.user['username'] }}</span><li><ahref="{{ url_for('auth.logout') }}">Log Out</a>
{% else %}
<li><ahref="{{ url_for('auth.register') }}">Register</a><li><ahref="{{ url_for('auth.login') }}">Log In</a>
{% endif %}
</ul></nav><sectionclass="content"><header>
{% block header %}{% endblock %}
</header>
{% for message in get_flashed_messages() %}
<divclass="flash">{{ message }}</div>
{% endfor %}
{% block content %}{% endblock %}
</section>
La base étant maintenant définie, vous pouvez enfin créer d'autres pages en agrandissant ce fichier et en personnalisant les blocs. Explorez l'exemple suivant pour la page Create Posts.
{% extends 'base.html' %}
{% block header %}
<h1>{% block title %}New Post{% endblock %}</h1>
{% endblock %}
{% block content %}
<formmethod="post"><labelfor="title">Title</label><inputname="title"id="title"value="{{ request.form['title'] }}"required><labelfor="body">Body</label><textareaname="body"id="body">{{ request.form['body'] }}</textarea><inputtype="submit"value="Save"></form>
{% endblock %}
Le paramètre "name" (nom) de l'entrée sera la clé du dictionnaire request.form, accessible dans les vues. Les pages d'authentification (login et register) ont une syntaxe assez similaire puisqu'elles ne nécessitent qu'un seul formulaire. Cependant, vous pouvez les consulter sur mon dépôt GitHub si vous le souhaitez.
Maintenant, regardons la page d'accueil, appelée index.html.
{% extends 'base.html' %}
{% block header %}
<h1>{% block title %}Posts{% endblock %}</h1>
{% if g.user %}
<aclass="action"href="{{ url_for('blog.create') }}">New</a>
{% endif %}
{% endblock %}
{% block content %}
{% for post in posts %}
<articleclass="post"><header><div><h1>{{ post['title'] }}</h1><divclass="about">by {{ post.user.username }} on {{ post['created'].strftime('%Y-%m-%d') }}</div></div>
{% if g.user['id'] == post['author_id'] %}
<aclass="action"href="{{ url_for('blog.update', id=post['id'] )}}">Edit</a>
{% endif%}
</header><pclass="body">{{ post['body'] }}</p></article>
{% if not loop.last %}
<hr>
{% endif %}
{% endfor %}
{% endblock %}
Voici quelques éléments qui valent la peine d'être examinés de plus près. Le lien pour créer un nouveau message n'apparaît que lorsque g.user confirme le vrai, ce qui signifie qu'un utilisateur s'est connecté. Il y a également une instruction "for" (pour), itérant à travers l'objet posts renvoyé par une requête sur la vue pour l'URL vide "" et transmis à ce fichier en tant qu'argument de render_template(). Pour chaque message, nous pouvons accéder au nom d'utilisateur lié à chaque utilisateur avec une syntaxe simple (post.user.username), grâce à la db.relationship ajoutée dans le modèle utilisateur User. Une autre façon d'accéder aux données est d'utiliser les messages comme des dictionnaires et d'afficher leurs propriétés avec une syntaxe d'index (comme post['title']). Portez une attention particulière à la façon dont le lien de mise à jour d'un article prend son ID comme argument et n'apparaît que si son utilisateur correspond à celui qui est actuellement connecté.
Enfin, nous avons la page de mise à jour, qui renvoie simultanément à la vue de suppression. Elle est analogue à la page Créer des messages, mais elle possède une logique particulière pour définir les valeurs par défaut à partir de la base de données. Je laisserai une illustration ci-dessous au cas où vous décideriez de l'explorer.
{% extends 'base.html' %}
{% block header %}
<h1>{% block title %}Edit "{{ post['title'] }}"{% endblock %}</h1>
{% endblock %}
{% block content %}
<formmethod="post"><labelfor="title">Title</label><inputname="title"id="title"value="{{ request.form['title'] or post['title'] }}"required><labelfor="body">Body</label><textareaname="body"id="body">{{ request.form['body'] or post['body'] }}</textarea><inputtype="submit"value="Save"></form><hr><formaction="{{ url_for('blog.delete', id=post['id']) }}"method="post"><inputtype="submit"class="danger"value="Delete"onclick="return confirm('Are you sure?');"></form>
{% endblock %}
Partie 5 - Ajout de fichiers statiques
Nous disposons à présent d'une interface interactive qui reçoit des informations depuis l'utilisateur jusqu'à la base de données et vice-versa, ainsi que d'objets IRIS accessibles en Python à l'aide de SQLAlchemy et de modèles créés avec la syntaxe des classes. Dans la dernière étape, nous avons également réussi à transformer ces objets en contenu d'éléments HTML, ce qui signifie que vous pouvez facilement les personnaliser et interagir avec eux à l'aide de CSS et de JavaScript.
Si l'on revient à la base HTML, on remarque la ligne contenant un lien renvoyant à l'élément stylesheet, juste au début :
Le premier argument de la fonction url_for() à l'intérieur de l'expression href est le dossier à l'intérieur de la racine où vous pouvez trouver les statiques. Le second, bien sûr, est le nom du fichier. A partir de maintenant, le concept est à vous ! Créez le fichier style.css et modifiez-le à votre guise.
C'est fait !
Avec tous les fichiers que nous avons créés, le dossier racine devrait ressembler à l'image ci-dessous :
.png)
Maintenant, rendez-vous dans le répertoire racine du terminal et tapez
flask --app flaskr-iris run --debug
Suivez ensuite le lien http://127.0.0.1:5000 pour voir comment tout fonctionne.
Conclusion
Dans cet article, nous avons vu comment Flask rend l'apport d'informations depuis une instance IRIS vers une application web possible et facile, en la transformant en un CRUD entièrement personnalisable, avec la possibilité de se connecter à d'autres bases de données et à d'autres systèmes. Désormais, vous pouvez facilement créer, afficher, mettre à jour et supprimer des informations d'une base de données IRIS, via une interface qui vous permet non seulement de personnaliser son apparence, ainsi que de traiter les données avec n'importe quel outil Python sans difficulté.
Vous pouvez me contacter pour me faire part de vos doutes ou des idées que vous avez rencontrées après la lecture ! Dans le prochain article, j'aborderai plus en détail la théorie de cette implémentation et présenterai l'application OpenExchange développée ici. En prime, je révèlerai quelques erreurs que j'ai rencontrées et les solutions que j'ai réussi à trouver dans la dernière section.
.png)
.png)
.png)
.png)
.png)


.png)
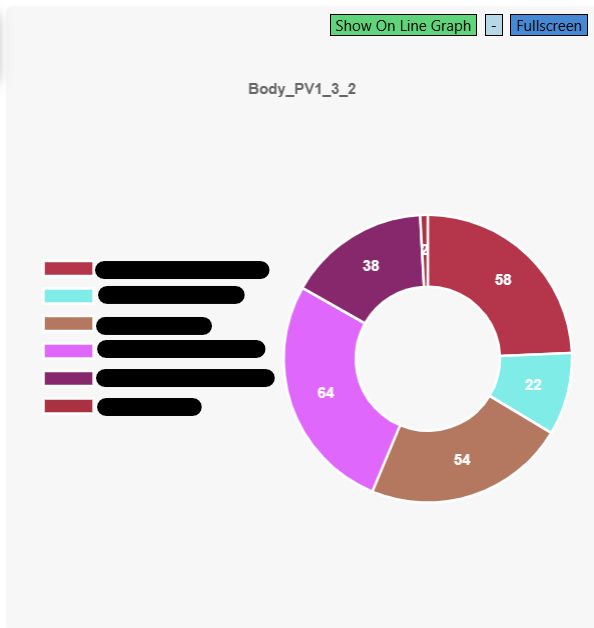
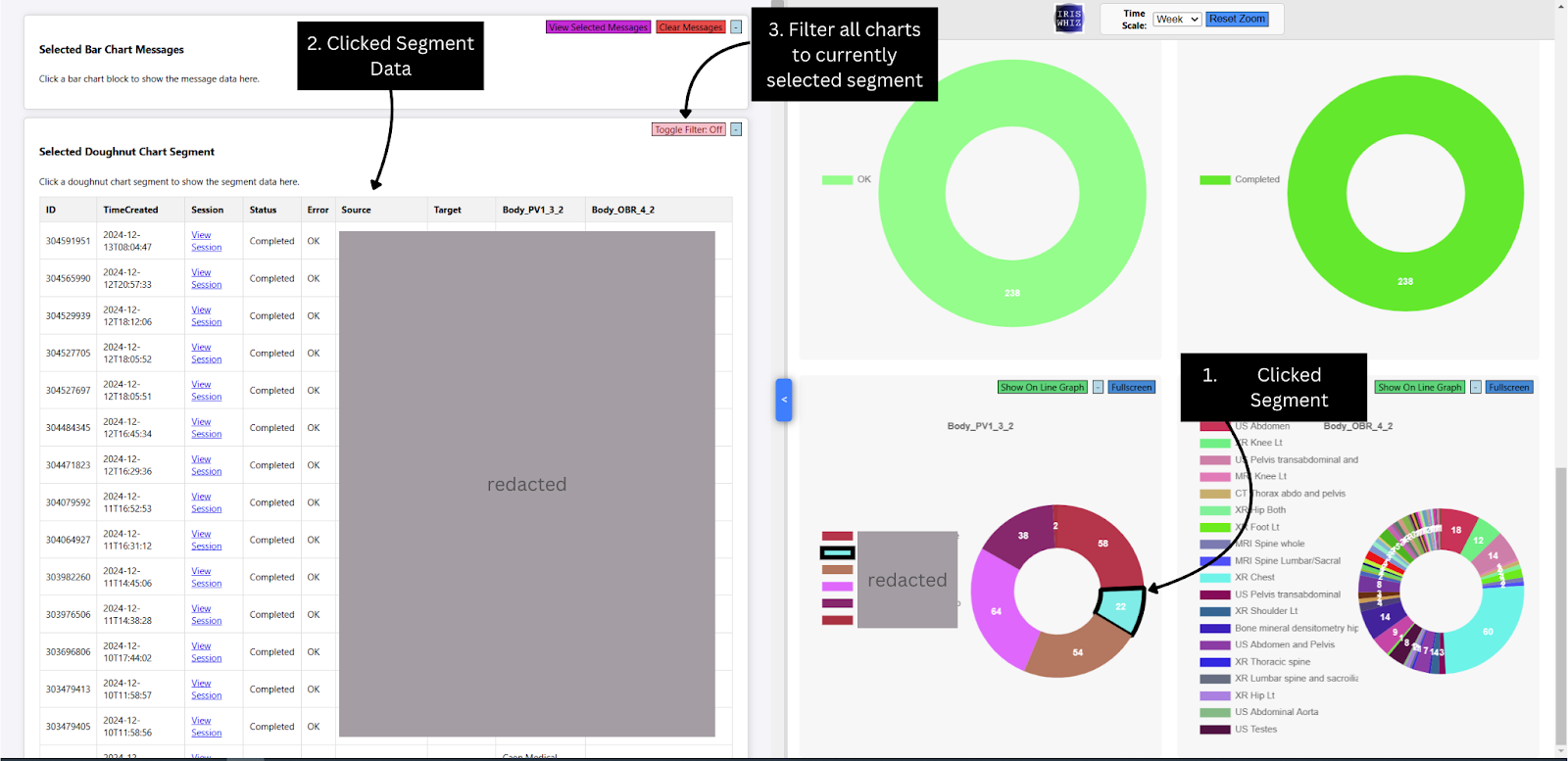
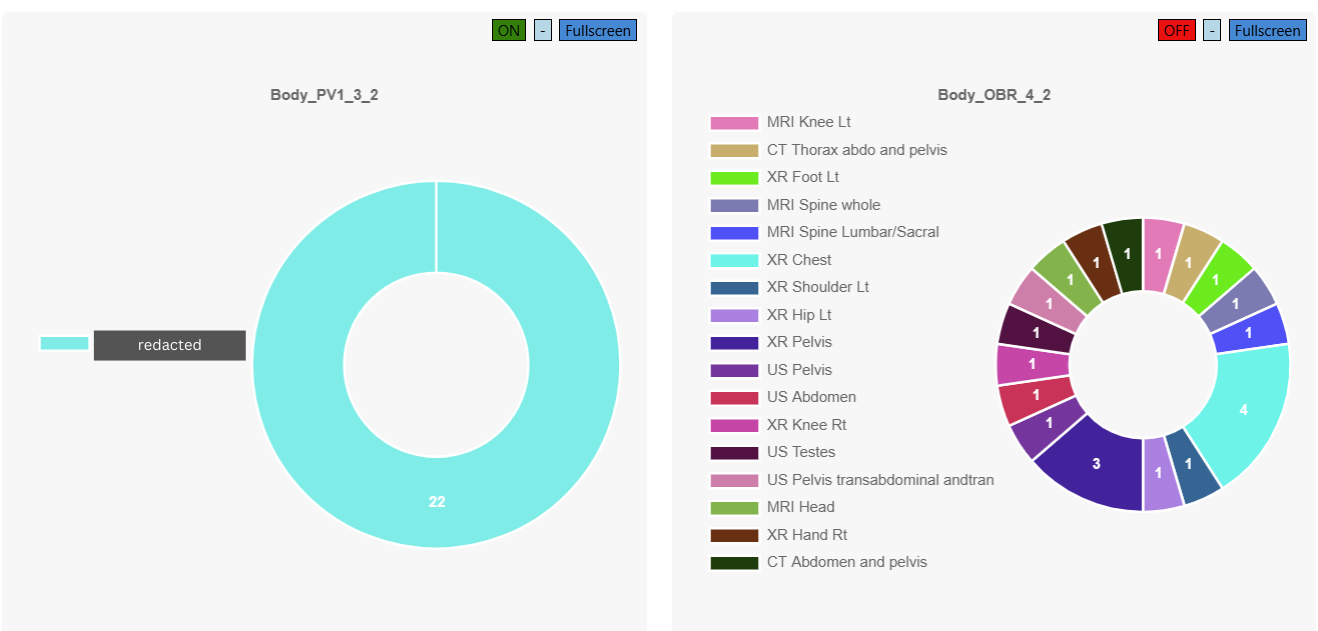
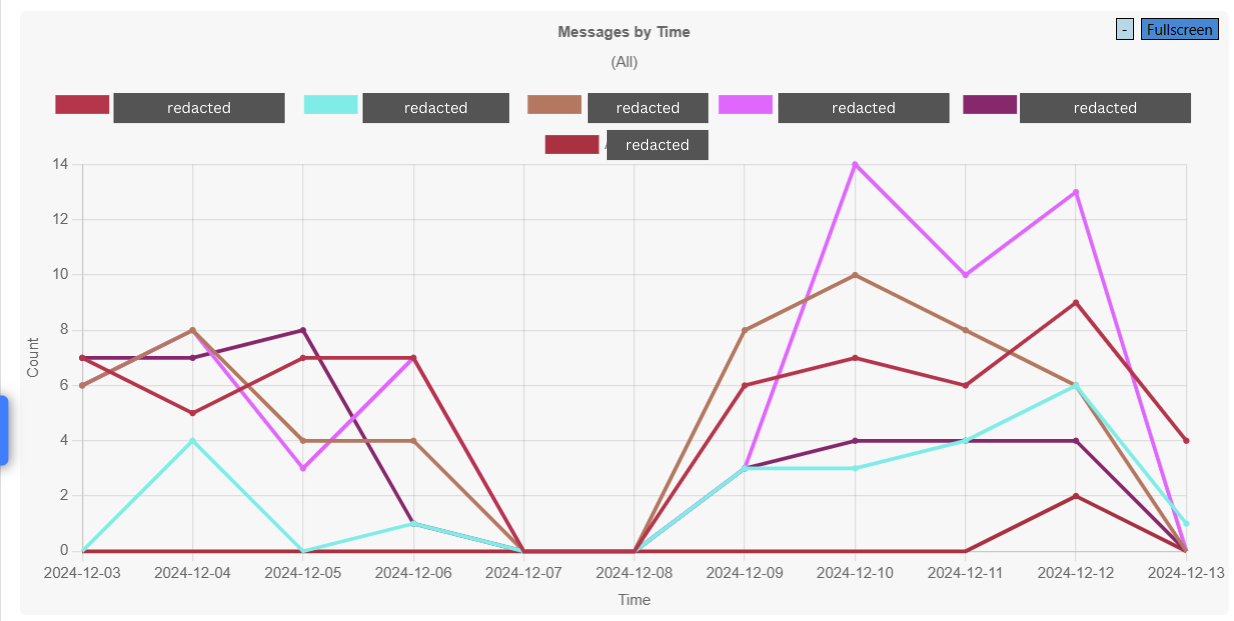
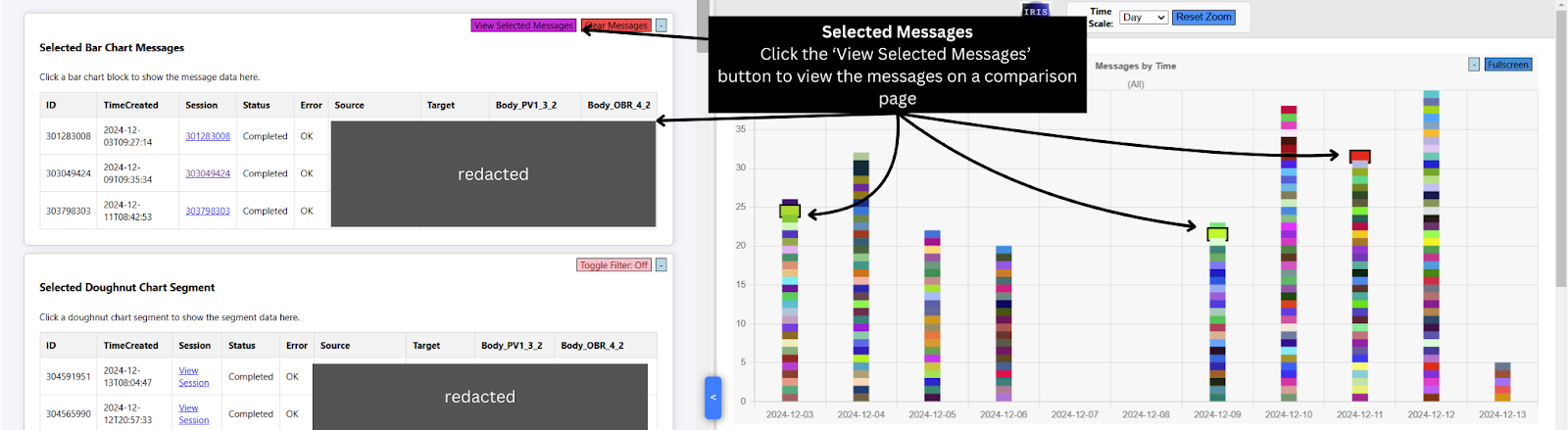
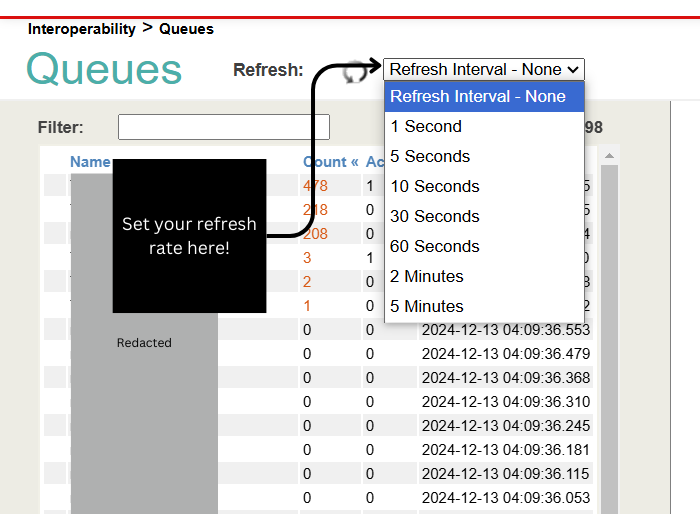
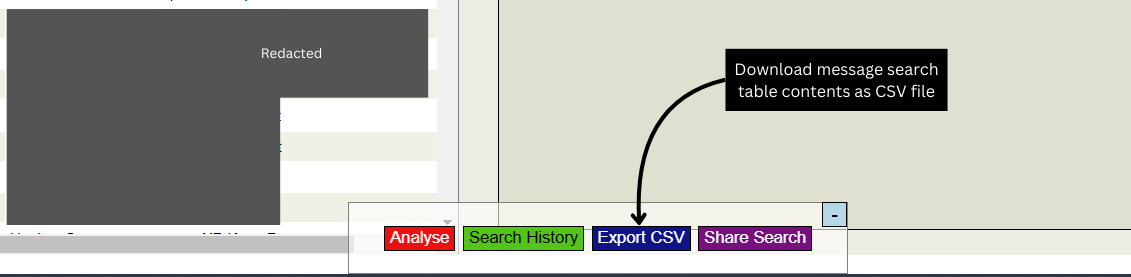
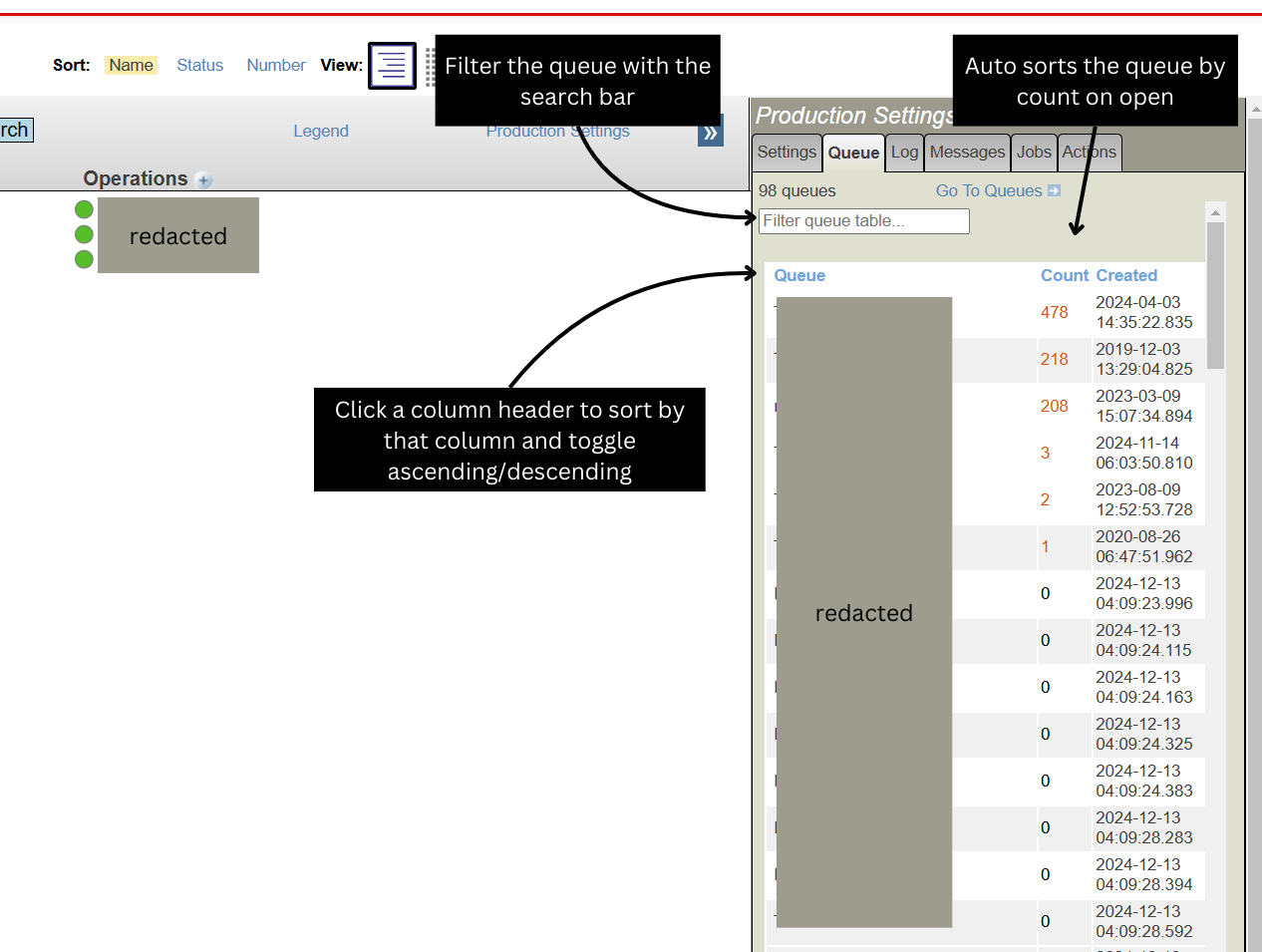




.jpg)
.png)
.png)
.png)


.jpg)

.jpg)

.png)
.png)
.png)
.png)
.png)
.png)
.png)


.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
