Mes clients me contactent régulièrement à propos du dimensionnement de la mémoire lorsqu'ils reçoivent des alertes indiquant que la mémoire libre est inférieure à un seuil ou lorsqu'ils constatent que la mémoire libre a soudainement diminué. Existe-t-il un problème? Leur application va-t-elle cesser de fonctionner parce qu'elle manque de mémoire pour exécuter les processus système et applicatifs? La réponse est presque toujours non, il est inutile de s'inquiéter. Mais cette réponse simple n'est généralement pas suffisante. Que se passe-t-il?
Considérez le graphique ci-dessous. Il montre le résultat de la métrique free dans vmstat. Il existe d'autres moyens d'afficher la mémoire libre d'un système, par exemple la commande free -m. Parfois, la mémoire libre disparaît progressivement au fil du temps. Le graphique ci-dessous est un exemple exagéré, mais il illustre bien ce qui se passe.
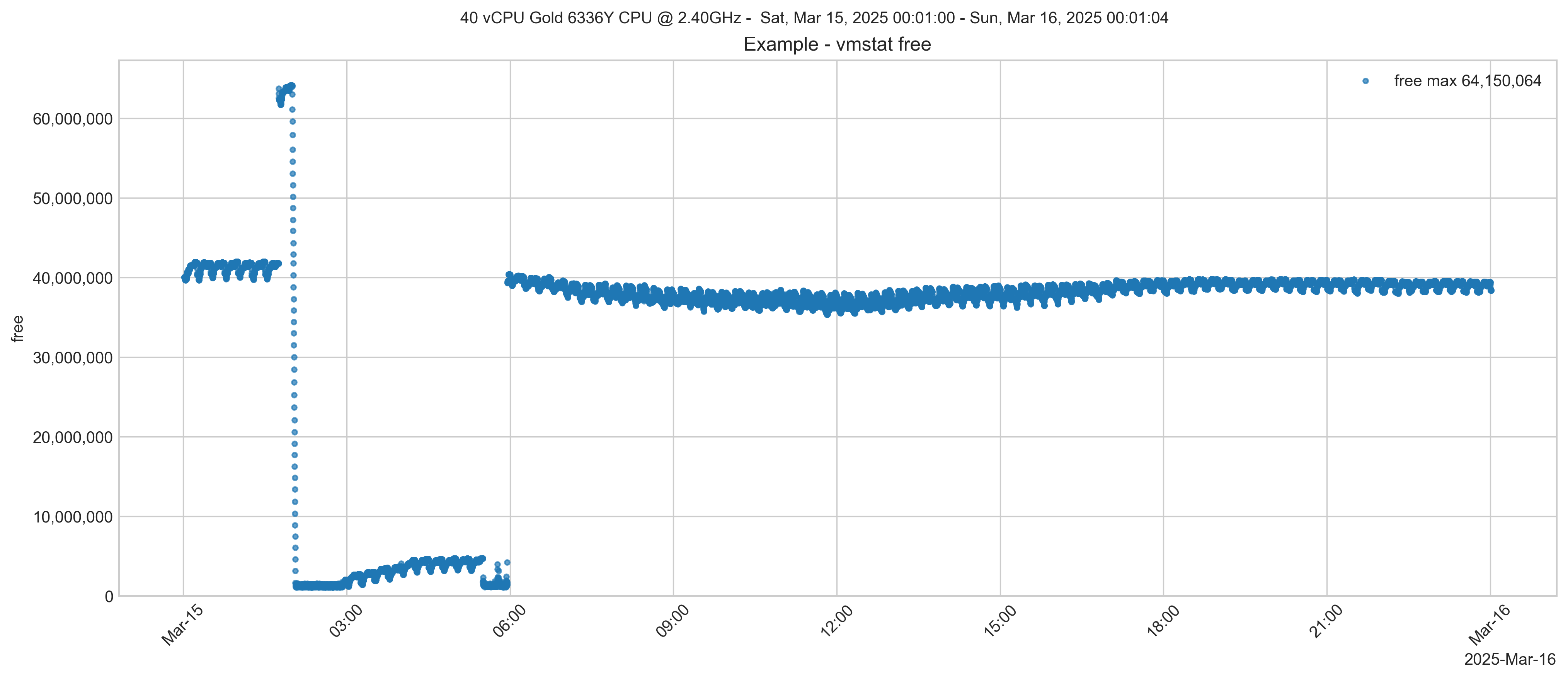
Comme vous pouvez le constater, vers 2 heures du matin, une partie de la mémoire est récupérée, puis chute soudainement à près de zéro. Ce système exécute l'application IntelliCare EHR sur la base de données InterSystems IRIS. Les informations vmstat proviennent d'un fichier HTML ^SystemPerformance qui collecte les métriques vmstat, iostat et plusieurs autres métriques système. Que se passe-t-il d'autre sur ce système ? Comme nous sommes en pleine nuit, je ne m'attends pas à ce qu'il se passe grand-chose à l'hôpital. Examinons iostat pour les volumes de la base de données.
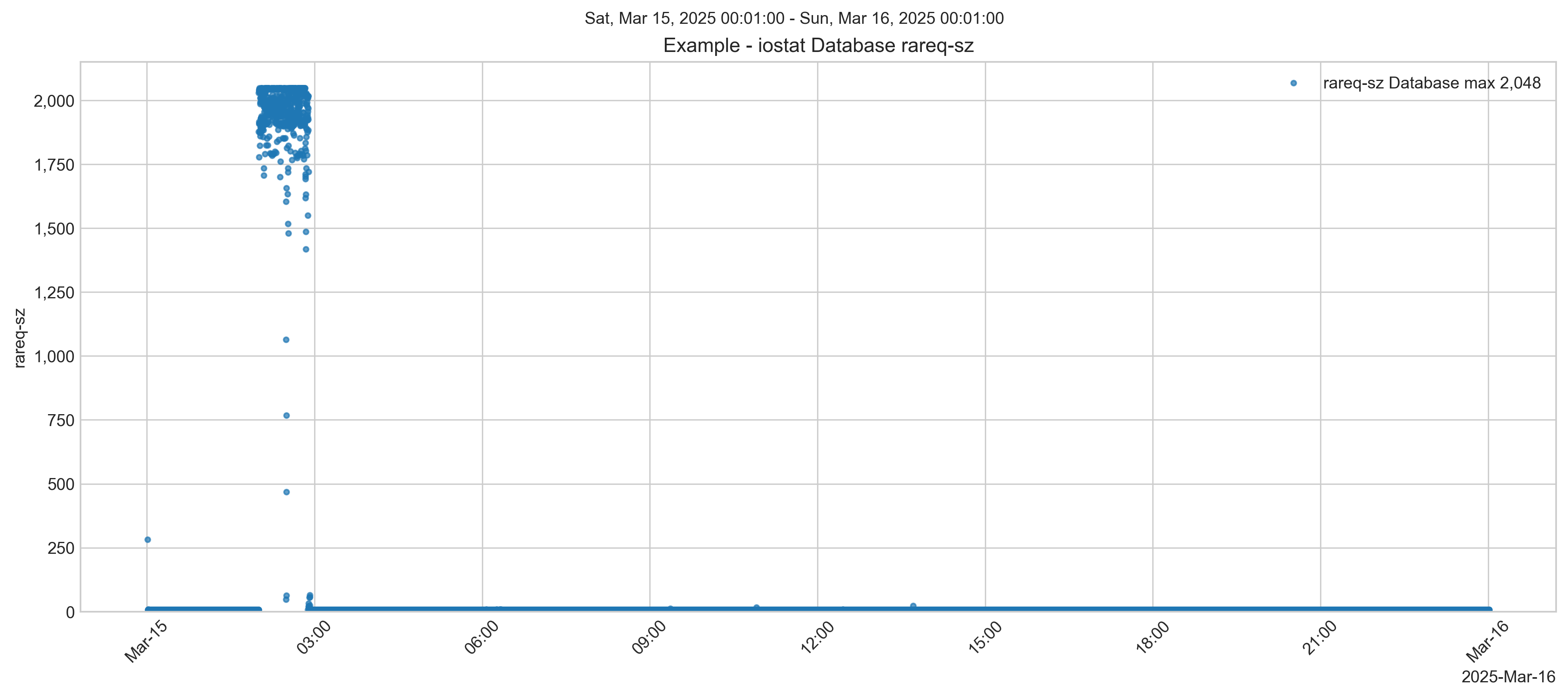
On constate une augmentation soudaine des lectures au moment où la mémoire libre diminue. La baisse de la mémoire libre signalée correspond à un pic des lectures en gros blocs (taille de requête de 2048 Ko) indiqué dans iostat pour le disque de la base de données. Il s'agit très probablement d'un processus de sauvegarde ou d'une copie de fichiers. Bien sûr, corrélation n'est pas synonyme de causalité, mais cela vaut la peine d'être examiné et, en fin de compte, cela explique ce qui se passe.
Examinons d'autres résultats de ^SystemPerformance. La commande free -m est exécutée à la même fréquence que vmstat (par exemple, toutes les 5 secondes) et est accompagnée de la date et de l'heure, ce qui nous permet également de représenter graphiquement les compteurs dans free -m.
Les compteurs:
- Memtotal – Total de RAM physique.
- used – RAM activement utilisée (applications + système d'exploitation + cache).
- free – RAM complètement inutilisée.
- shared – Mémoire partagée entre les processus.
- buf/cache – RAM utilisée pour les tampons et le cache, récupérable si nécessaire.
- available – RAM disponible sans swap.
- swaptotal – Espace de swap total sur le disque.
- swapused – Espace de swap actuellement utilisé.
- swapfree – Espace de swap inutilisé.
Pourquoi la mémoire libre diminue-t-elle à 2 heures du matin?
- Les lectures séquentielles de grande taille remplissent le cache de page du système de fichiers, consommant temporairement de la mémoire qui apparaît comme "utilisée" dans
free -m. - Linux utilise de manière agressive la mémoire inexploitée pour la mise en cache des E/S afin d'améliorer les performances.
- Une fois la sauvegarde terminée (≈ 03h00), la mémoire est progressivement récupérée au fur et à mesure que les processus en ont besoin.
- Vers 6 heures du matin, l'hôpital commence à s'activer et la mémoire est utilisée pour IRIS et d'autres processus.
Une mémoire libre insuffisante ne constitue pas une pénurie, mais plutôt une utilisation de la mémoire "libre" par le système à des fins de mise en cache. Il s'agit d'un comportement normal sous Linux! Le processus de sauvegarde lit de grandes quantités de données, que Linux met agressivement en cache dans la mémoire tampon/cache. Le noyau Linux convertit la mémoire "libre" en mémoire "cache" afin d'accélérer les opérations d'E/S.
Résumé
Le cache du système de fichiers est conçu pour être dynamique. Si la mémoire est requise par un processus, elle sera immédiatement récupérée. Il s'agit d'un élément normal de la gestion de la mémoire sous Linux.
Les Huge Pages ont-elles un impact?
Pour optimiser les performances et réserver de la mémoire pour la mémoire partagée IRIS, la meilleure pratique pour les déploiements IRIS en production sur des serveurs dotés d'une mémoire importante consiste à utiliser les Huge Pages de Linux. Pour IntelliCare, j'utilise généralement 8 Go de mémoire par noyau et environ 75 % de la mémoire pour la mémoire partagée d'IRIS (tampons Routine et Global, GMHEAP et autres structures de mémoire partagée). La répartition de la mémoire partagée dépend des exigences de l'application. Vos exigences peuvent être complètement différentes. Par exemple, en utilisant ce rapport CPU/mémoire, 25 % suffisent-ils pour les processus IRIS et les processus du système d'exploitation de votre application?
InterSystems IRIS utilise l'E/S directe pour les fichiers de base de données et les fichiers journaux, ce qui contourne le cache du système de fichiers. Ses segments de mémoire partagée (globales, routines, gmheap, etc.) sont alloués à partir de Huge Pages.
- Ces pages immenses (huge pages) sont dédiées à la mémoire partagée IRIS et n'apparaissent pas comme "libres" ou "cache" dans
free -m. - Once allocated, huge pages are not available for filesystem cache or user processes.
Cela explique pourquoi les métriques free -m semblent "insuffisantes" même si la base de données IRIS elle-même ne manque pas de mémoire.
Comment la mémoire libre pour un processus est-elle calculée?
À partir de ce qui précède, dans free -m, les lignes pertinentes sont les suivantes:
- free – RAM totalement inutilisée.
- available – RAM encore utilisable sans échange.
La disponibilité est un bon indicateur: elle inclut la mémoire cache et les tampons récupérables, indiquant ce qui est réellement disponible pour les nouveaux processus sans échange. Quels processus? Pour plus d'informations, consultez InterSystems Data Platforms and Performance Part 4 - Looking at Memory . Voici une liste simple: système d'exploitation, autres processus d'application non-IRIS et processus IRIS.
Examinons un graphique de la sortie free -m.
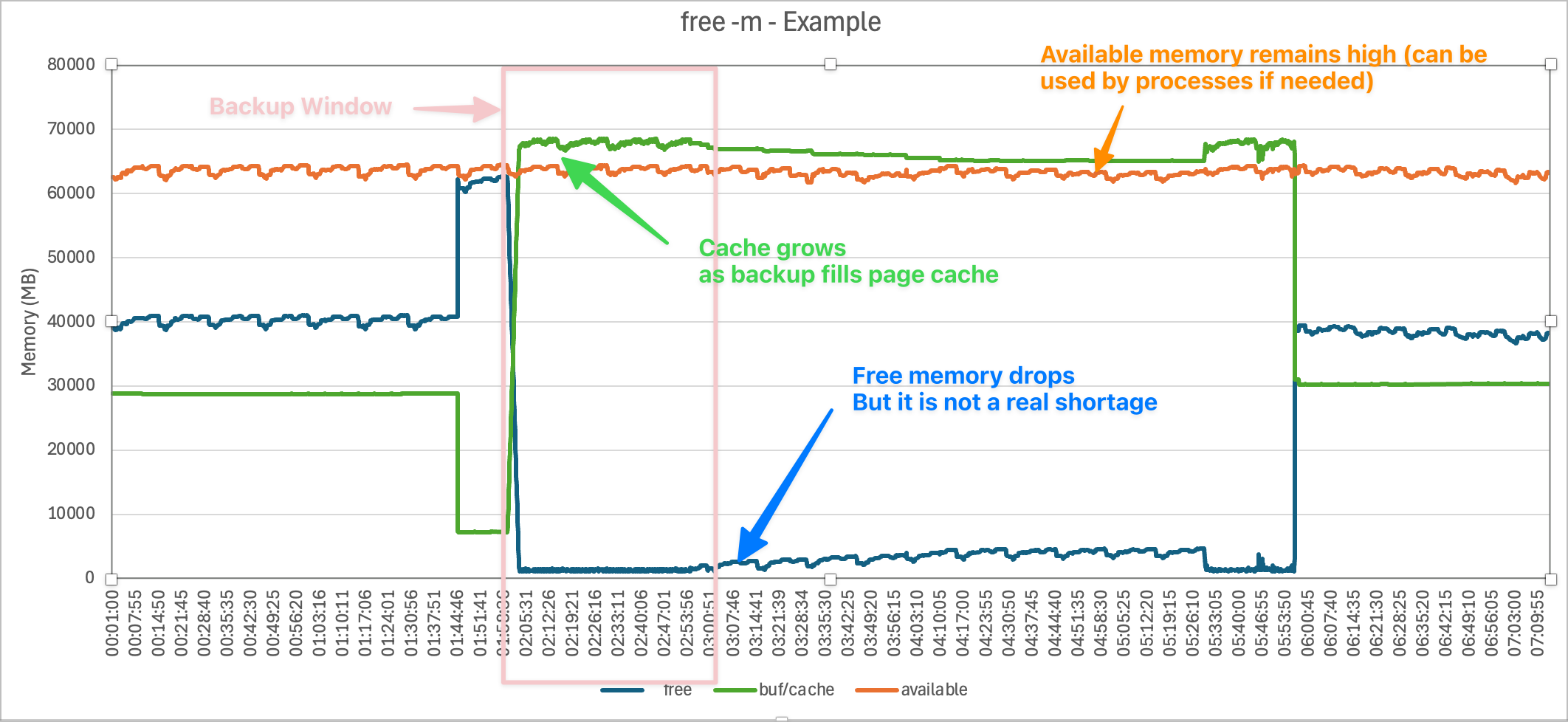
Bien que la valeur de la mémoire libre (free) chute à près de zéro pendant la sauvegarde, la valeur de la mémoire disponible (available) reste beaucoup plus élevée (plusieurs dizaines de Go). Cela signifie que le système pourrait fournir cette mémoire aux processus si nécessaire.
A quel endroit apparaissent les pages immenses dans la mémoire libre?
Par défaut, free -m n'affiche pas directement les pages immenses. Pour les voir, vous avez besoin des entrées /proc/meminfo telles que HugePages_Total, HugePages_Free et Hugepagesize.
Puisque le système d'exploitation réserve des pages immenses au démarrage, elles sont effectivement invisibles pour
free -m. Elles sont verrouillées et isolées du pool de mémoire général.
Résumé
- La "mémoire disponible" insuffisante constatée vers 02h00 est due au remplissage du cache de pages Linux par des lectures de sauvegarde. Il s'agit d'un comportement normal qui n'indique pas une pénurie de mémoire.
- Les pages immenses réservées à IRIS ne sont pas affectées et continuent à servir efficacement la base de données.
- La mémoire réellement disponible pour les applications est mieux mesurée par la colonne
disponible, qui montre que le système dispose encore d'une marge suffisante.
Mais attendez, que se passe-t-il si je n'utilise pas les Huge Pages?
Généralement, on n'utilise pas les Huge Pages sur les systèmes non productifs ou à mémoire limitée. Les gains de performances des Huge Pages ne sont généralement pas significatifs en dessous de 64 Go, bien qu'il soit toujours recommandé d'utiliser les Huge Pages pour protéger la mémoire partagée IRIS.
A propos. J'ai vu des sites rencontrer des problèmes en allouant des pages immenses moins grandes que la mémoire partagée, ce qui oblige IRIS à essayer de démarrer avec des tampons globaux très petits ou à échouer au démarrage si memlock est utilisé (envisagez memlock=192 pour les systèmes de production).
Sans Huge Pages, les segments de mémoire partagée IRIS ( globales, routines, gmheap, etc.) sont alloués à partir de pages de mémoire normales du système d'exploitation. Cela apparaîtrait sous la mémoire "utilisée" dans free -m. Cela contribuerait également à réduire la mémoire "disponible", car cette mémoire ne peut pas être facilement récupérée.
- utilisée – Beaucoup plus élevée, reflétant la mémoire partagée IRIS + le noyau + d'autres processus.
- libre – Probablement moins suffisante, car plus de RAM est allouée en permanence à IRIS dans le pool régulier.
- buf/cache – Augmenterait toujours pendant les sauvegardes, mais la marge apparente pour les processus semblerait plus restreinte, car la mémoire IRIS se trouve dans le même pool.
- disponible – Plus proche de la véritable “mémoire libre + cache récupérable” moins la mémoire IRIS. Cela semblerait plus petit que dans votre configuration Huge Pages.
Alors, faut-il utiliser Huge Pages dans des systèmes de production?
OUI!
Pour la protection de la mémoire. La mémoire partagée IRIS est protégée contre:
- Remplacement en cas de sollicitation de la mémoire.
- Concurrence avec les opérations du système de fichiers telles que les sauvegardes et les copies de fichiers, comme nous l'avons vu dans cet exemple.
Autres remarques - trop profondément dans les détails...
Comment les données sont-elles collectées?
La commande utilisée dans ^SystemPerformance pour une collecte de 24 heures (17 280 secondes) avec des coches toutes les 5 secondes est la suivante:
free -m -s 5 -c 17280 | awk '{now=strftime(""%m/%d/%y %T""); print now "" "" $0; fflush()}' > ","/filepath/logs/20250315_000100_24hours_5sec_12.log
.png)
.png)
.png)