Nous présentons ici le processus d'utilisation de la célèbre solution Jaeger pour tracer les applications InterSystems IRIS. Jaeger est un produit open source permettant de suivre et d'identifier des problèmes, en particulier dans les environnements distribués et de microservices. Ce backend de traçage, apparu chez Uber en 2015, a été inspiré par Dapper de Google et OpenZipkin de Twitter. Il a ensuite rejoint la Fondation Cloud Native Computing (CNCF) en tant que projet en incubation en 2017, avant d'obtenir le statut gradué en 2019. Ce guide vous montrera comment utiliser la solution Jaeger conteneurisée intégrée à IRIS.
Caractéristiques du Jaeger
- Surveillance des flux de transactions exécutés par une ou plusieurs applications et composants (services) dans des environnements conventionnels ou distribués:
- Identification précise des goulots d'étranglement dans les flux métier, y compris ceux qui sont distribués:
- Étude et optimisation des dépendances entre services, composants, classes et méthodes:
- Identification des indicateurs de performance pour découvrir les possibilités d'amélioration:




Composants Jaeger
Extrait de la documentation Jaeger: https://www.jaegertracing.io/docs/1.23/architecture/

- Client: Solutions, applications ou technologies (telles que IRIS) qui envoient des données de surveillance à Jaeger.
- Agent: Démon réseau qui surveille les segments envoyés via UDP, les regroupe et les transmet au collecteur. Il est conçu pour être déployé sur tous les hôtes en tant que composant d'infrastructure, en abstraisant le routage et la découverte des collecteurs depuis le client.
- Collecteur: Récepteur des traces provenant des agents Jaeger, qui les traite via un pipeline de traitement , lequel valide les traces, les indexe, effectue les transformations nécessaires, puis les stocke.
- Agent d'ingestion (facultatif): Si une file d'attente de messages telle qu'Apache Kafka tamponne les données entre le collecteur et le stockage, l'agent d'ingestion Jaeger lit les données dans Kafka et les écrit dans le stockage.
- Requête: Service qui récupère les traces du stockage et héberge une interface utilisateur pour les afficher.
- Interface utilisateur: L'interface Web Jaeger pour analyser et tracer les flux de transactions.
Aperçu d'Open Telemetry (OTel)
Étant donné qu'OpenTelemetry est la technologie exploitée par IRIS pour envoyer des données de traçage à Jaeger, il est important de comprendre son fonctionnement.
OpenTelemetry (alias OTel) est un framework d'observabilité open source et fournisseur neutre permettant d'instrumenter, de générer, de collecter et d'exporter des données de télémétrie telles que des traces, des métriques et des logs. Dans cet article, nous nous concentrerons sur la fonctionnalité traces.
L'unité fondamentale de données dans OpenTelemetry est le “signal”. L'objectif d'OpenTelemetry est de collecter, traiter et exporter ces signaux, qui sont des sorties système décrivant l'activité sous-jacente du système d'exploitation et des applications s'exécutant sur une plateforme. Un signal peut être quelque chose que vous souhaitez mesurer à un moment précis (par exemple, la température, l'utilisation de la mémoire) ou un événement qui traverse les composants de votre système distribué que vous souhaitez tracer. Vous pouvez regrouper différents signaux afin d'observer le fonctionnement interne d'une même technologie sous plusieurs angles (source: https://opentelemetry.io/docs/concepts/signals/). Cet article explique la manière d'émettre des signaux associés à des traces (le cheminement d'une requête dans votre application) depuis IRIS vers les collecteurs OTel.
OpenTelemetry est un excellent choix pour surveiller et tracer votre environnement IRIS et votre code source, car il est pris en charge par plus de 40 fournisseurs d'observabilité. Il est également intégré à de nombreuses bibliothèques, services et applications, et adopté par de nombreux utilisateurs finaux (source: https://opentelemetry.io/docs/).

- Les microservices développés en Java, .NET, Python, NodeJS, InterSystems ObjectScript et des dizaines d'autres langages peuvent envoyer des données de télémétrie à un collecteur OTel à l'aide des points de terminaison et des ports distants (dans notre exemple, nous utiliserons un port HTTP).
- Les composants de l'infrastructure peuvent également envoyer des données, notamment des données sur les performances, l'utilisation des ressources (processeur, mémoire, etc.) et d'autres informations pertinentes pour la surveillance de ces composants. Pour InterSystems IRIS, les données sont collectées par Prometheus à partir du point de terminaison /monitor et peuvent être transférées vers un collecteur OTel.
- Les API et les outils de base de données peuvent également envoyer des données de télémétrie. Certains produits de base de données sont capables de le faire automatiquement (instrumentalisation).
- Le collecteur OTel reçoit les données OTel et les stocke dans une base de données compatible et/ou les transmet à des outils de surveillance (par exemple, Jaeger).
Comment InterSystems IRIS envoie des données de surveillance à Jaeger
À partir de la version 2025, InterSystems a lancé la prise en charge d'OpenTelemetry (OTel) dans son API de surveillance. Cette nouvelle fonctionnalité inclut l'émission de données de télémétrie pour le traçage, la journalisation et les métriques d'environnement. Cet article traite de l'envoi de données de traçage à Jaeger via OTel. Vous trouverez plus de détails ici: https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=AOTEL&ADJUST=1.
Bien que certains langages de programmation et certaines technologies prennent en charge la transmission automatique des données OTel (instrumentation automatique), pour IRIS, vous devez écrire des instructions de code spécifiques pour activer cette fonctionnalité. Téléchargez le code source de l'application exemple à partir de https://openexchange.intersystems.com/package/iris-telemetry-sample, ouvrez votre IDE et suivez les étapes ci-dessous:
1. Accédez à la classe dc.Sample.REST.TelemetryUtil. La méthode SetTracerProvider initialise un fournisseur de traceurs, ce qui vous permet de définir le nom et la version du service surveillé:
/// Définition du fournisseur de traceursClassMethod SetTracerProvider(ServiceName As%String, Version As%String) As%Status
{
Set sc = $$$OKset attributes("service.name") = ServiceName
set attributes("service.version") = Version
Set tracerProv = ##class(%Trace.TracerProvider).%New(.attributes)
Set sc = ##class(%Trace.Provider).SetTracerProvider(tracerProv)
Quit sc
}2. L'étape suivante consiste à récupérer l'instance du fournisseur de traceurs créée:
/// Obtention du fournisseur de traceursClassMethod GetTracerProvider() As%Trace.Provider
{
Return##class(%Trace.Provider).GetTracerProvider()
}3. Cet exemple va surveiller l'API PersonREST sur le point de terminaison /persons/all. Accédez à la classe dc.Sample.PersonREST (méthode de classe GetAllPersons):
/// Récupération de tous les enregistrements de dc.Sample.PersonClassMethod GetAllPersons() As%Status
{
<span class="hljs-keyword">#dim</span> tSC <span class="hljs-keyword">As</span> <span class="hljs-built_in">%Status</span> = <span class="hljs-built_in">$$$OK</span>
<span class="hljs-keyword">do</span> <span class="hljs-keyword">##class</span>(dc.Sample.REST.TelemetryUtil).SetTracerProvider(<span class="hljs-string">"Get.All.Persons"</span>, <span class="hljs-string">"1.0"</span>)
<span class="hljs-keyword">set</span> tracerProv = <span class="hljs-keyword">##class</span>(dc.Sample.REST.TelemetryUtil).GetTracerProvider()
<span class="hljs-keyword">set</span> tracer = tracerProv.GetTracer(<span class="hljs-string">"Get.All.Persons"</span>, <span class="hljs-string">"1.0"</span>)
4. Le fournisseur de traceurs vient de créer un service de surveillance appelé Get.All.Persons (version 1.0) et a obtenu l'instance de traceurs avec GetTracer.
5. L'exemple doit créer un racine Span comme suit:
set rootAttr("GetAllPersons") = 1set rootSpan = tracer.StartSpan("GetAllPersons", , "Server", .rootAttr)
set rootScope = tracer.SetActiveSpan(rootSpan)6. Les spans sont des éléments du flux de traçage. Chaque span doit être mappé à un élément du code source que vous souhaitez analyser.
7. SetActiveSpan est obligatoire pour définir le span actuel à surveiller.
8. À présent, l'exemple crée plusieurs spans descendants mappés à des éléments importants du flux:
set childSpan1 = tracer.StartSpan("Query.All.Persons")
set child1Scope = tracer.SetActiveSpan(childSpan1)
Try {
Set rset = ##class(dc.Sample.Person).ExtentFunc()
do childSpan1.SetStatus("Ok")
} Catch Ex {
do childSpan1.SetStatus("Error")
}
do childSpan1.End()
kill childSpan19. Ce premier span des descendant surveille la requête pour toutes les personnes dans la base de données. Pour créer un span descendant, l'exemple utilise StartSpan avec un titre suggéré (Query.All.Persons). Le span actif doit ensuite être défini sur le span descendant actuel, ce que l'exemple réalise à l'aide de SetActiveSpan avec la référence childSpan1.
10. L'exemple exécute le code source métier (Set rset = ##class(dc.Sample.Person).ExtentFunc()). Si l'opération réussit, il définit le statut sur "Ok" ; sinon, il le définit sur "Error."
11. L'exemple termine la surveillance de ce morceau de code à l'aide de la méthode End et en supprimant la référence childSpan1.
12. Vous pouvez répéter cette procédure pour tous les autres segments de code que vous souhaitez examiner:
Pour surveiller la détection d'une personne par son ID (obtenir les détails de la personne):
set childSpan2 = tracer.StartSpan("Get.PersonByID")
set child2Scope = tracer.SetActiveSpan(childSpan2)
Set person = ##class(dc.Sample.Person).%OpenId(rset.ID)
Pour observer le calcul de l'âge (classe dc.Sample.Person, méthode CalculateAge):
set tracerProv = ##class(dc.Sample.REST.TelemetryUtil).GetTracerProvider()
set tracer = tracerProv.GetTracer("Get.All.Persons", "1.0")
set childSpan1 = tracer.StartSpan("CalculateAge")
set child1Scope = tracer.SetActiveSpan(childSpan1)Pour vérifier la définition du signe du zodiaque (classe dc.Sample.Person, méthode CalculateZodiacSign):
set tracerProv = ##class(dc.Sample.REST.TelemetryUtil).GetTracerProvider()
set tracer = tracerProv.GetTracer("Get.All.Persons", "1.0")
set childSpan1 = tracer.StartSpan("GetZodiacSign")
set child1Scope = tracer.SetActiveSpan(childSpan1)
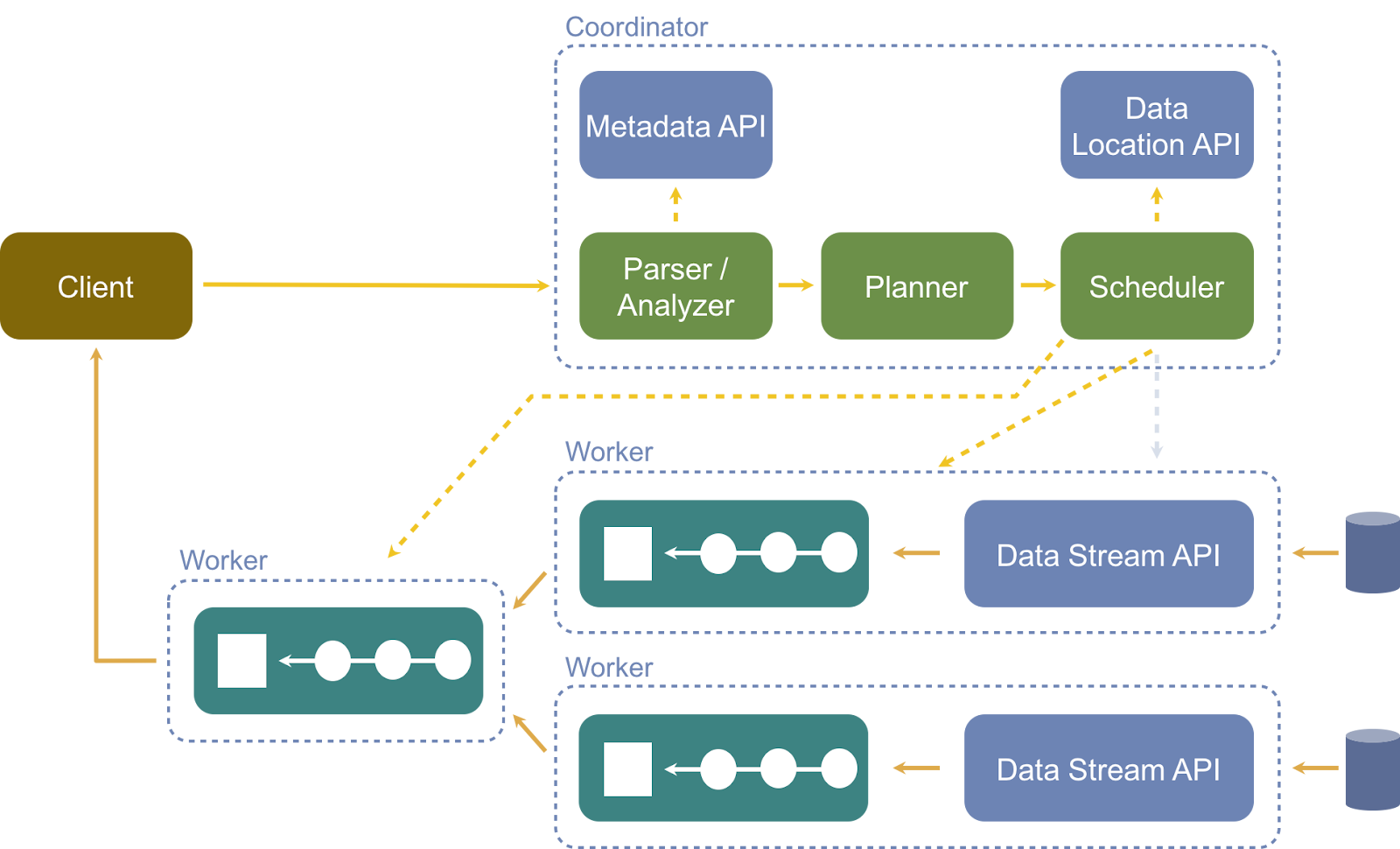
Configuration des conteneurs IRIS et Jaeger
1. Créez le conteneur collecteur OTel (dans docker-composer.yml):
# --- 2. Collecteur OpenTelemetry --- otel-collector: image:otel/opentelemetry-collector-contrib:latest command:["--config=/etc/otel-collector-config.yml"] volumes: -./otel-collector-config.yml:/etc/otel-collector-config.yml ports: -"4317:4317"# OTLP gRPC -"4318:4318"# OTLP HTTP -"9464:9464"# Métriques depends_on: -iris -jaeger2. Ajustez le fichier de configuration du collecteur OTel:
receivers: otlp: protocols: grpc: endpoint:"0.0.0.0:4317" http: endpoint:"0.0.0.0:4318"exporters: otlp: endpoint:jaeger:4317# Le nom du service « jaeger » de docker-compose pour le collecteur gRPC tls: insecure:true prometheus: endpoint:"0.0.0.0:9464" debug:{}processors: batch:# Processeur pour regrouper des traces en lots send_batch_size:100 timeout:10sconnectors: spanmetrics:# Connecteur SpanMetricsservice: pipelines: traces: receivers:[otlp] processors:[batch]# Les traces sont traitées pour générer des métriques exporters:[otlp,spanmetrics] metrics: receivers:[otlp,spanmetrics] exporters:[prometheus] logs: receivers:[otlp] exporters:[debug]3. Le collecteur OTel recevra les données de surveillance à l'adresse suivante:
http: endpoint:"0.0.0.0:4318"4. Le collecteur OTel enverra les exportateurs (Exporters) à Jaeger comme indiqué ci-dessous:
exporters:
otlp:
endpoint: jaeger:4317 # O nome do serviço 'jaeger' do docker-compose para o Collector gRPC
tls:
insecure: true
5. Le service OTel créera un pipeline pour recevoir et envoyer les données de surveillance:
service: pipelines: traces: receivers:[otlp] processors:[batch] exporters:[otlp]6. Dans le fichier docker-compose.yml, l'exemple va créer un conteneur IRIS, en définissant OTEL_EXPORTER_OTLP_ENDPOINT avec l'adresse du collecteur OTel:
iris: build: context:. dockerfile:Dockerfile restart:always ports: -51773:1972 -52773:52773 -53773 volumes: -./:/home/irisowner/dev environment: -ISC_DATA_DIRECTORY=/home/irisowner/dev/durable -OTEL_EXPORTER_OTLP_ENDPOINT=http://otel-collector:4318
7. Enfin, un conteneur Jaeger est créé pour recevoir les données du collecteur OTel et fournir une interface utilisateur permettant aux utilisateurs de surveiller et de tracer les données IRIS OTel:
jaeger: image:jaegertracing/all-in-one:latest ports: -"16686:16686"# Jaeger UI -"14269:14269"# Jaeger Metrics -"14250:14250"# Jaeger Collector gRPC environment: -COLLECTOR_OTLP_ENABLED=true
Il existe des options de port supplémentaires pour Jaeger qui vous permettent de traiter plusieurs types de collecteurs. Vous trouverez ci-dessous la liste des ports exposés disponibles:
- 6831/udp: Accepte les spans jaeger.thrift (Thrift compact)
- 6832/udp: Accepte les spans jaeger.thrift (Thrift binaire)
- 5778: Configuration Jaeger
- 16686: Interface utilisateur Jaeger
- 4317: Récepteur gRPC du protocole OpenTelemetry (OTLP)
- 4318: Récepteur HTTP du protocole OpenTelemetry (OTLP)
- 14250: Acceptation des spans model.proto via gRPC
- 14268: Acceptation directe des spans jaeger.thrift via HTTP
- 14269: Vérification de l'intégrité de Jaeger
- 9411: Compatibilité Zipkin
Exécution de l'exemple
1. Copiez le code source de l'exemple:
$ git clone https://github.com/yurimarx/iris-telemetry-sample.git2. Ouvrez le terminal dans ce répertoire et exécutez le code ci-dessous:
$ docker-compose up -d --build3. Créez quelques données de test simulées. Pour ce faire, ouvrez le terminal IRIS ou le terminal web sur /localhost:52773/terminal/ and call the following:
USER>do##class(dc.Sample.Person).AddTestData(10)4. Ouvrez http://localhost:52773/swagger-ui/index.html et exécutez le point de terminaison /persons/all.
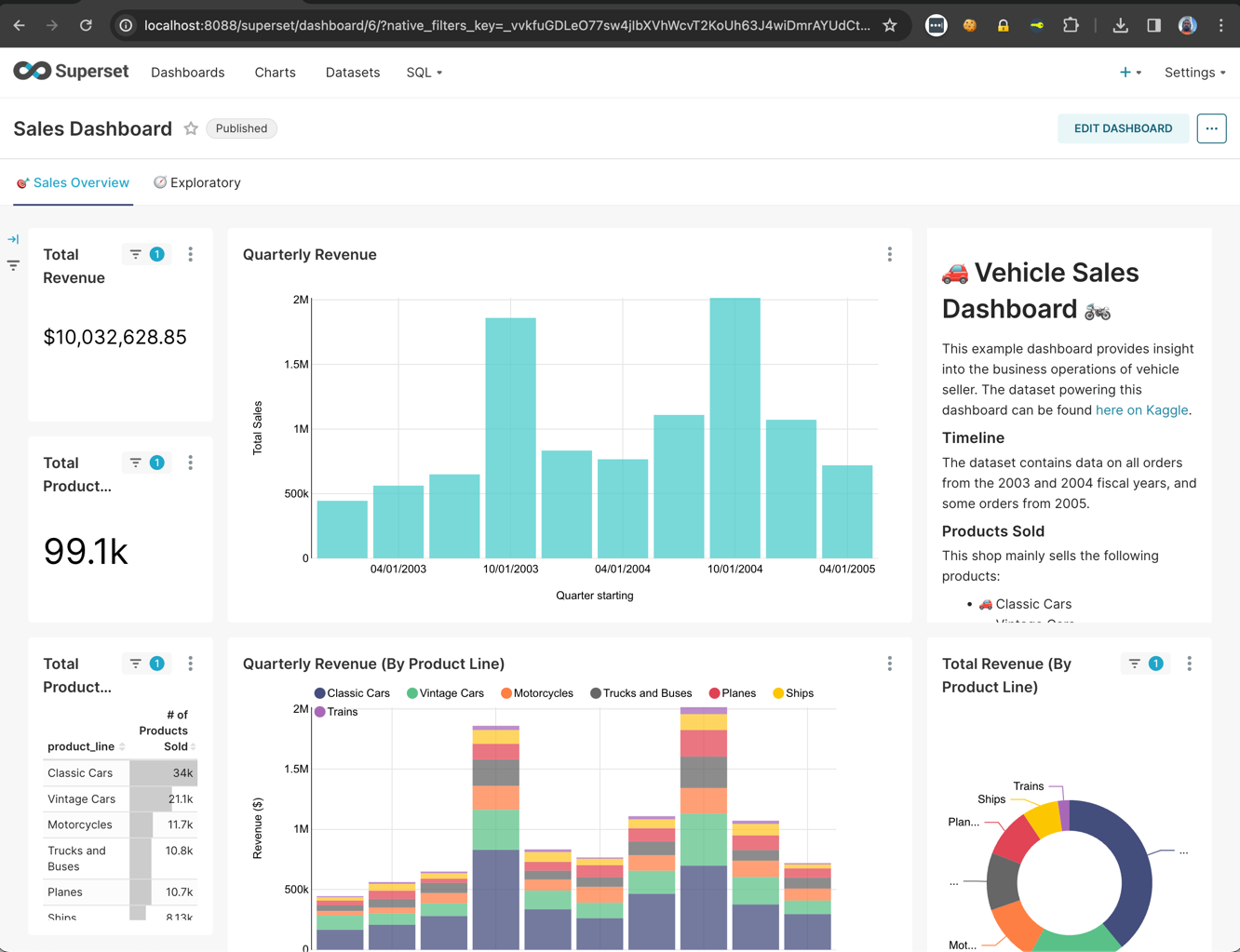
Analyse et traçage du code IRIS sur Jaeger
1. Accédez à Jaeger ici http://localhost:16686/search.
2. Sélectionnez Get.All.Persons dans le champ "Service", puis cliquez sur "Find Traces" (Rechercher les traces).

3. Cliquez sur la trace détectée pour afficher ses détails.

4. Observez la chronologie de la trace sélectionnée.

5. Dans le coin supérieur droit, sélectionnez "Trace Graph" :

6. Analysez les dépendances:

7. Cette analyse des dépendances est essentielle pour identifier les problèmes dans les systèmes/services distants au sein de votre environnement, en particulier si différents services distribués utilisent le même nom de service.
8. Maintenant, sélectionnez “Framegraph”:

9. Observez tous les composants du flux de transactions surveillé dans une table graphique:

10. Grâce à toutes ces ressources Jaeger, vous pouvez résoudre efficacement les problèmes de performances et identifier la source des erreurs.
Pour en savoir plus
Pour approfondir vos connaissances sur le traçage distribué, consultez les ressources externes suivantes:
- Maîtrise du traçage distribué (Mastering Distributed Tracing) (2019) par Yuri Shkuro : article de blog rédigé par le créateur de Jaeger, qui explique l'histoire et les choix architecturaux à l'origine de Jaeger. Ce livre traite en détail de la conception et du fonctionnement de Jaeger, ainsi que du traçage distribué en général.
- Suivez Jaeger pour un tour en HotROD: un tutoriel étape par étape qui montre comment utiliser Jaeger pour résoudre les problèmes de performances des applications.
- Présentation de Jaeger : un (ancien) webinaire présentant Jaeger et ses capacités.
- Tutoriel détaillé sur Jaeger: https://betterstack.com/community/guides/observability/jaeger-guide/
- Évolution du traçage distribué au sein d'Uber.
- Émettre des données de télémétrie vers un outil de surveillance compatible avec OpenTelemetry par la documentation InterSystems.
- Observabilité moderne avec InterSystems IRIS & et OpenTelemetry: Une vidéo de démonstration sur la manière de travailler avec OpenTelemetry et IRIS: https://www.youtube.com/watch?v=NxA4nBe31nA
- OpenTelemetry sur GitHub : Une collection d'API, de SDK et d'outils pour instrumenter, générer, collecter et exporter des données de télémétrie (métriques, journaux et traces) afin d'aider à analyser les performances et le comportement de logiciels: https://github.com/open-telemetry.











.png)
.png)
.png)
.png)
.png)
.png)
.png)


.png)
.png)
.png)
.png)






.png)









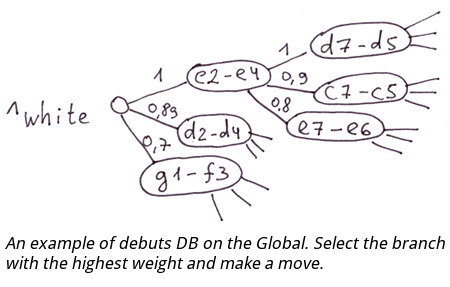
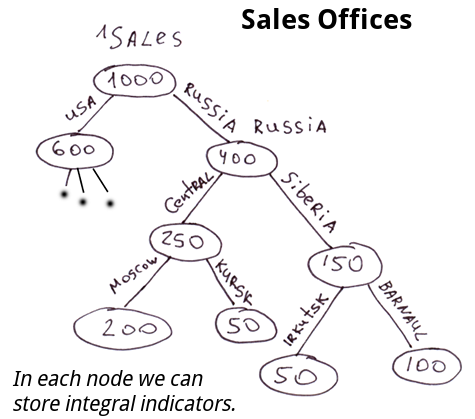
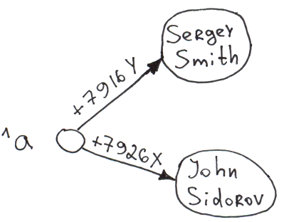
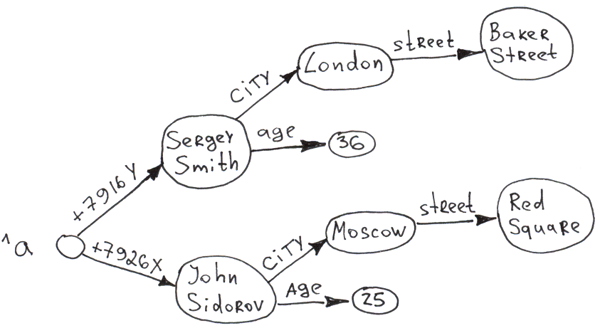
 Dans les parties précédentes (
Dans les parties précédentes (






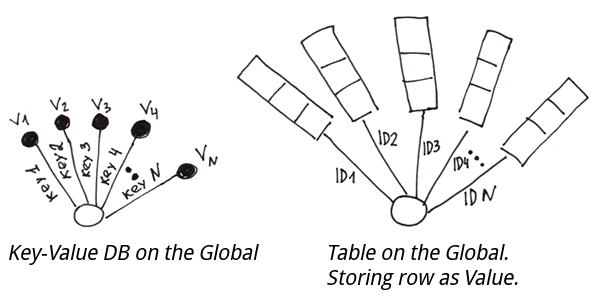
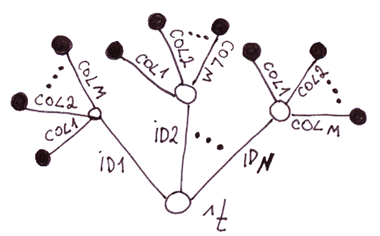
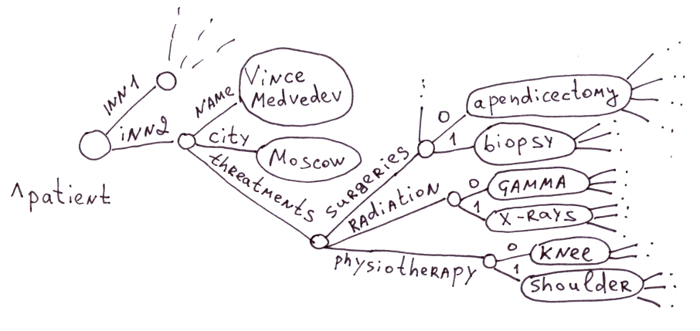
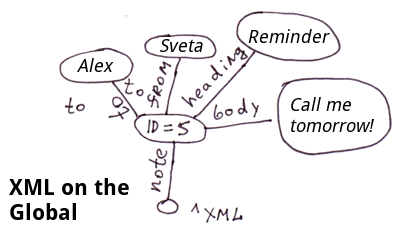
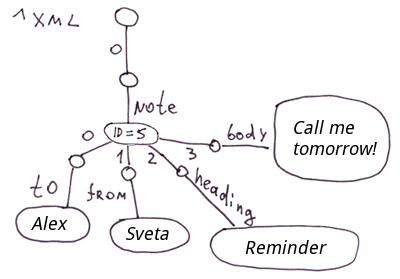
 En général, si le schéma de données ne change pas souvent, que la vitesse d'insertion n'est pas critique et que l'ensemble de la base de données peut être facilement représenté par des tables normalisées, il est plus facile de travailler avec SQL, car il offre un niveau d'abstraction plus élevé.
En général, si le schéma de données ne change pas souvent, que la vitesse d'insertion n'est pas critique et que l'ensemble de la base de données peut être facilement représenté par des tables normalisées, il est plus facile de travailler avec SQL, car il offre un niveau d'abstraction plus élevé.