Le nuage Amazon Web Services (AWS) offre un large éventail de services d'infrastructure, tels que des ressources de calcul, des options de stockage et des réseaux, qui sont fournis comme un service public : à la demande, disponibles en quelques secondes, avec une tarification à l'usage. De nouveaux services peuvent être mis à disposition rapidement, sans dépenses d'investissement initiales. Les entreprises, les start-ups, les petites et moyennes entreprises et les clients du secteur public peuvent ainsi accéder aux éléments de base dont ils ont besoin pour répondre rapidement à l'évolution des exigences commerciales.
Updated: 2-Apr, 2021
L'aperçu et les détails suivants sont fournis par Amazon et peuvent être consultés à l'adresse suivante
ici.
Aperçu
Infrastructure globale d'AWS
L'infrastructure du cloud AWS est construite autour de régions et de AZ (zones de disponibilité). Une région est un emplacement physique dans le monde où nous avons plusieurs zones de disponibilité. Les zones de disponibilité sont constituées d'un ou plusieurs centres de données distincts, chacun doté d'une alimentation, d'une mise en réseau et d'une connectivité redondantes, hébergés dans des installations séparées. Ces zones de disponibilité vous offrent la possibilité d'exploiter des applications et des bases de données de production qui sont plus hautement disponibles, plus tolérantes aux pannes et plus évolutives qu'il ne serait possible de le faire à partir d'un seul centre de données.
Les détails de l'infrastructure mondiale d'AWS sont disponiblesici.
Sécurité et conformité d'AWS
La sécurité dans le cloud computing ressemble beaucoup à la sécurité de vos centres de données sur site, mais sans les coûts de maintenance des installations et du matériel. Dans le cloud, vous n'avez pas à gérer de serveurs physiques ou de dispositifs de stockage. En revanche, vous utilisez des outils de sécurité logiciels pour surveiller et protéger le flux d'informations entrant et sortant de vos ressources en cloud.
Le cloud AWS permet un modèle de responsabilité partagée. Alors qu'AWS gère la sécurité du cloud, vous êtes responsable de la sécurité dans le cloud. Cela signifie que vous gardez le contrôle de la sécurité que vous choisissez de mettre en œuvre pour protéger votre propre contenu, votre plate-forme, vos applications, vos systèmes et vos réseaux, comme vous le feriez dans un centre de données sur site.
Les détails de la sécurité du cloud AWS peuvent être trouvés ici .
L'infrastructure informatique qu'AWS fournit à ses clients est conçue et gérée conformément aux meilleures pratiques de sécurité et à diverses normes de sécurité informatique. Vous trouverez une liste complète des programmes d'assurance auxquels AWS se conforme ici .
AWS Cloud Plate-forme
AWS se compose many de services en nuage que vous pouvez utiliser dans des combinaisons adaptées aux besoins de votre entreprise ou de votre organisation. La sous-section suivante présente les principaux services AWS par catégorie qui sont couramment utilisés avec les déploiements d'InterSystems IRIS. Il existe de nombreux autres services disponibles et potentiellement utiles pour votre application spécifique. N'hésitez pas à les rechercher si nécessaire.
Pour accéder aux services, vous pouvez utiliser l'AWS Management Console, l'interface de ligne de commande ou les kits de développement logiciel SDK (Software Development Kits).
<caption>AWS Cloud Platform</caption> |
Composante
| <th>
Détails
</th>
|---|
|
AWS Management Console
| <td>
Les détails de l'AWS Management Console sont disponibles ici.
</td>
|---|
|
Interface de ligne de commande AWS
| <td>
Les détails de l'Interface de ligne de commande AWS sont disponibles ici.
</td>
|---|
|
Les kits de développement logiciel SDK (Software Development Kits)
| <td>
Les détails des kits de développement logiciel SDK (Software Development Kits) sont disponibles ici.
</td>
|---|
|
Calcul AWS
| <td>
De nombreuses options sont disponibles : Les détails d'Amazon Elastic Cloud Computing (EC2) sont disponibles ici Les détails d'Amazon EC2 Container Service (ECS) sont disponibles ici Les détails d'Amazon EC2 Container Registry (ECR) sont disponibles ici Les détails d'Amazon Auto Scaling sont disponibles ici
</td>
|---|
|
Stockage AWS
| <td>
De nombreuses options sont disponibles : Les détails d'Amazon Elastic Block Store (EBS) sont disponibles ici Les détails d'Amazon Simple Storage Service (S3) sont disponibles ici Les détails d'Amazon Elastic File System (EFS) sont disponibles ici
</td>
|---|
|
Mise en réseau AWS
| <td>
De nombreuses options sont disponibles. Les détails d'Amazon Virtual Private Cloud (VPC) sont disponibles ici Les détails d'Amazon Elastic IP Addresses sont disponibles ici Les détails d'Amazon Elastic Network Interfaces sont disponibles ici Les détails d'Amazon Enhanced Networking pour Linux sont disponibles ici Les détails d'Amazon Elastic Load Balancing (ELB) sont disponibles ici Les détails d'Amazon Route 53 sont disponibles ici
</td>
|---|
Exemples d'architectures InterSystems IRIS
Dans le cadre de cet article, des exemples de déploiement d'InterSystems IRIS pour AWS sont fournis comme point de départ pour le déploiement de votre application spécifique. Ils peuvent être utilisés comme ligne directrice pour de nombreuses possibilités de déploiement. Cette architecture de référence démontre des options de déploiement très robustes, allant des plus petits déploiements aux charges de travail massivement évolutives pour les besoins de calcul et de données.
Les options de haute disponibilité et de reprise après sinistre sont abordées dans ce document, ainsi que d'autres opérations système recommandées. Il est prévu que ces dernières soient modifiées par l'individu pour soutenir les pratiques standard et les politiques de sécurité de son organisation.
InterSystems est à votre disposition pour toute discussion ou question sur les déploiements d'InterSystems IRIS basés sur AWS pour votre application spécifique.
Architectures de référence exemplaires
Les architectures exemplaires suivantes fournissent plusieurs configurations différentes avec des capacités et des possibilités croissantes. Considérez ces exemples de petit développement / production / production importante / production avec des clusters shards qui montrent la progression depuis une configuration modeste pour les efforts de développement jusqu'à des solutions massivement évolutives avec une haute disponibilité appropriée entre les zones et une reprise après sinistre multirégionale. En outre, un exemple d'architecture utilisant les nouvelles capacités de sharding d'InterSystems IRIS Data Platform pour les charges de travail hybrides avec traitement massivement parallèle des requêtes SQL.
Configuration du petit développement
Dans le présent exemple, une configuration minimale est utilisée pour illustrer un environnement de développement de petite taille capable de prendre en charge jusqu'à 10 développeurs et 100 Go de données. Il est facile de prendre en charge un plus grand nombre de développeurs et de données stockées en changeant simplement le type d'instance de la machine virtuelle et en augmentant le stockage du ou des volumes EBS, le cas échéant.
Cela permet de soutenir les efforts de développement et de se familiariser avec les fonctionnalités d'IRIS d'InterSystems, ainsi qu'avec la création et l'orchestration de conteneurs Docker, si nécessaire. La haute disponibilité avec la mise en miroir des bases de données n'est généralement pas utilisée avec une petite configuration, mais elle peut être ajoutée à tout moment si la haute disponibilité est nécessaire.
Diagramme exemplaire de petite configuration
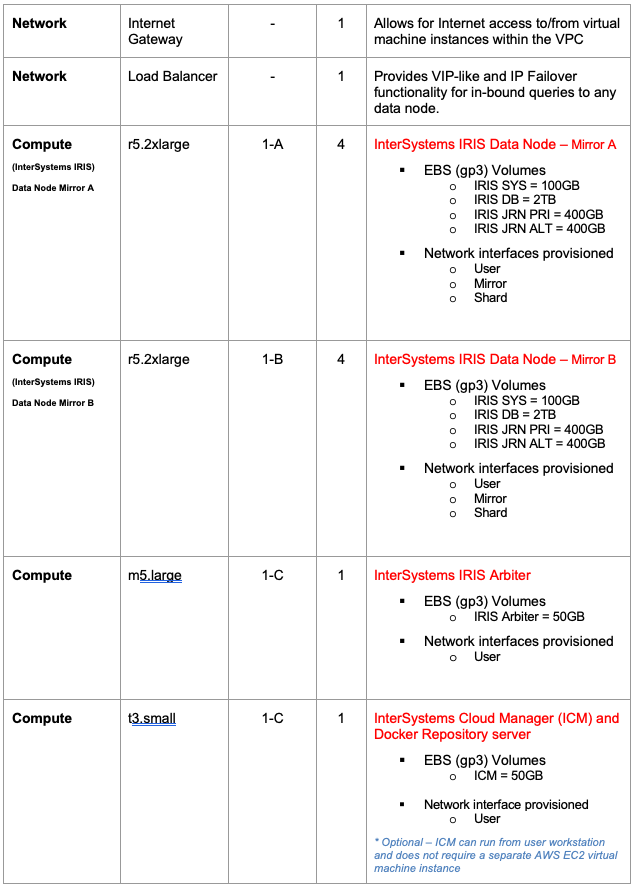
Le diagramme exemplaire de la Figure 2.1.1-a ci-dessous illustre le tableau des ressources de la Figure 2.1.1-b. Les passerelles incluses ne sont que des exemples et peuvent être adaptées en fonction des pratiques réseau standard de votre organisation.
Figure-2.1.1-a: Architecture exemplaire de petits développements
.png)
Les ressources suivantes dans le VPC AWS sont provisionnées comme une petite configuration minimale. Les ressources AWS peuvent être ajoutées ou supprimées le cas échéant.
Ressources AWS pour petites configurations
Un exemple de ressources AWS de petite configuration (Small Configuration AWS) est fourni ci-dessous dans le tableau suivant.

Une sécurité du réseau appropriée et des règles de pare-feu doivent être envisagées pour empêcher tout accès indésirable au VPC. Amazon fournit les meilleures pratiques en matière de sécurité réseau pour commencer, qui sont disponibles : ici
https://docs.aws.amazon.com/vpc/index.html#lang/en_us
https://docs.aws.amazon.com/quickstart/latest/vpc/architecture.html#best-practices
Note: Les instances VM ont besoin d'une adresse IP publique pour accéder aux services AWS. Bien que cette pratique puisse susciter quelques inquiétudes, AWS recommande de limiter le trafic entrant vers ces instances VM à l'aide de règles de pare-feu.
Si votre politique de sécurité exige des instances VM réellement internes, vous devrez configurer manuellement un proxy NAT sur votre réseau et une route correspondante pour que les instances internes puissent atteindre l'Internet. Il est important de noter que vous ne pouvez pas vous connecter à une instance VM entièrement interne directement en utilisant SSH. Pour vous connecter à de telles machines internes, vous devez configurer une instance de bastion qui possède une adresse IP externe, puis la traverser par un tunnel. Un hôte bastion peut être provisionné pour fournir le point d'entrée externe dans votre VPC.
Les détails de l'utilisation des bastion hosts sont disponibles : ici
https://aws.amazon.com/blogs/security/controlling-network-access-to-ec2-instances-using-a-bastion-server/
https://docs.aws.amazon.com/quickstart/latest/linux-bastion/architecture.html
Configuration de production
Dans cet exemple, une configuration plus importante est traîtée comme exemple de configuration de production qui incorpore la capacité de mise en miroir de la base de données InterSystems IRIS pour prendre en charge la haute disponibilité et la reprise après sinistre.
Cette configuration comprend une paire de serveurs de base de données InterSystems IRIS en miroir synchrone répartis entre deux zones de disponibilité dans la région 1 pour un basculement automatique, et un troisième membre miroir asynchrone DR dans la région 2 pour une reprise après sinistre dans le cas peu probable où une région AWS entière serait hors ligne.
DLes détails d'une région multiple avec la connectivité Multi-VPC sont disponibles ici.
InterSystems Arbiter et le serveur ICM sont déployés dans une troisième zone séparée pour plus de résilience. L'exemple d'architecture comprend également un ensemble de serveurs Web facultatifs à charge équilibrée pour prendre en charge une application Web. Ces serveurs Web et la passerelle InterSystems Gateway peuvent être mis à l'échelle indépendamment selon les besoins.
Diagramme exemplaire de la configuration de la production
Le diagramme exemplaire de la Figure 2.2.1-a illustre le tableau des ressources de la Figure 2.2.1-b. Les passerelles incluses ne sont que des exemples et peuvent être adaptées en fonction des pratiques réseau standard de votre organisation.
Figure 2.2.1-a : Architecture de production exemplaire avec haute disponibilité et reprise après sinistre
.png)
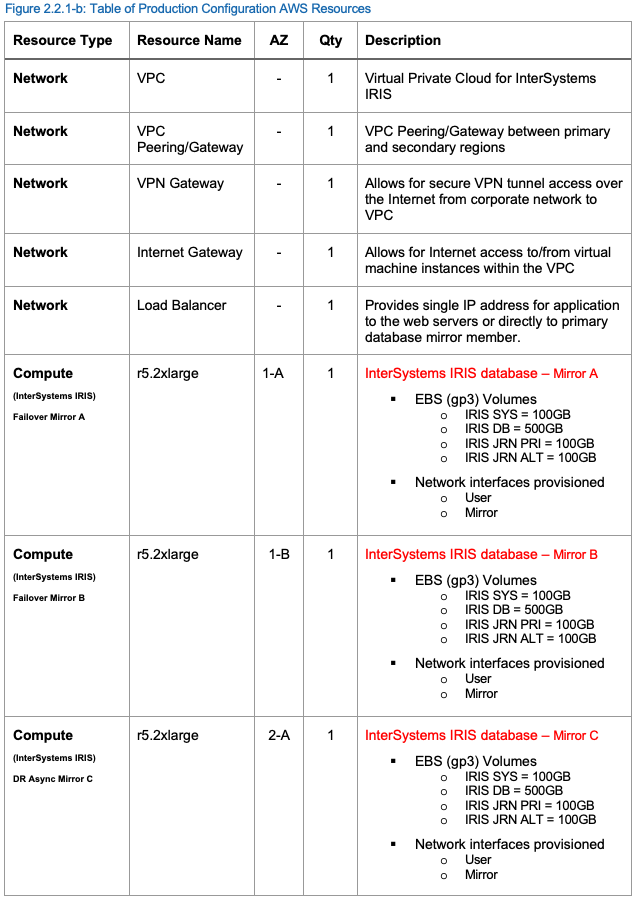
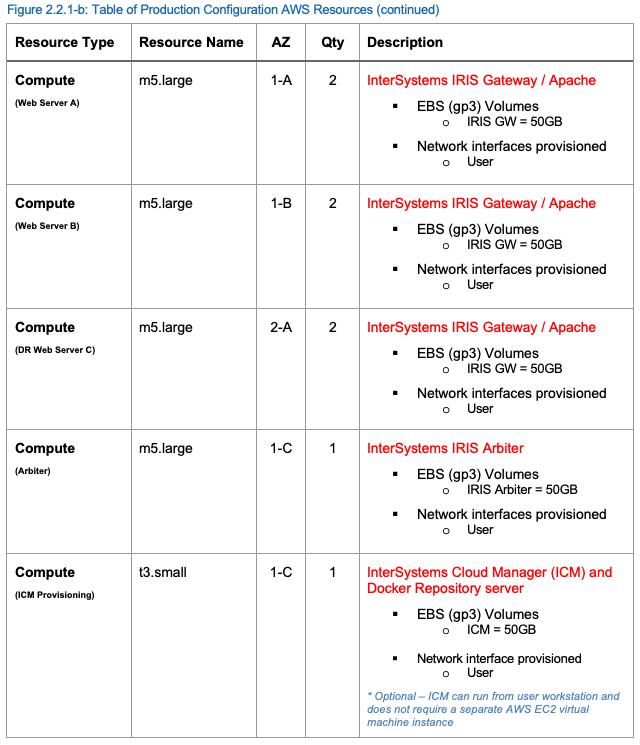
Les ressources suivantes au sein du AWS VPC sont recommandées au minimum pour supporter une charge de travail de production pour une application web. Les ressources AWS peuvent être ajoutées ou supprimées selon les besoins.
Production Configuration AWS Resources
Un exemple de configuration de production des ressources AWS est fourni dans le tableau suivant.
Configuration de production importante
Dans cet exemple, une configuration massivement évolutive est fournie en étendant la capacité d'InterSystems IRIS pour introduire également des serveurs d'applications utilisant le protocole ECP (Enterprise Cache Protocol) d'InterSystems afin de permettre une évolution horizontale massive des utilisateurs. Un niveau de disponibilité encore plus élevé est inclus dans cet exemple car les clients ECP préservent les détails de la session même en cas de basculement d'une instance de base de données. Plusieurs zones de disponibilité AWS sont utilisées avec des serveurs d'application basés sur ECP et des membres miroirs de base de données déployés dans plusieurs régions. Cette configuration est capable de prendre en charge des dizaines de millions d'accès à la base de données par seconde et plusieurs téraoctets de données.
Diagramme exemplaire de la configuration de la production
Le schéma exemplaire de la Figure 2.3.1-a illustre le tableau des ressources de la Figure 2.3.1-b. Les passerelles incluses ne sont que des exemples, et peuvent être ajustées en fonction des pratiques réseau standard de votre organisation.
Cette configuration comprend une paire de miroirs de basculement, quatre clients ECP ou plus (serveurs d'application) et un ou plusieurs serveurs Web par serveur d'application. Les paires de miroirs de base de données à basculement sont réparties entre deux zones de disponibilité AWS différentes dans la même région pour la protection du domaine de défaillance, avec le serveur InterSystems Arbiter et ICM déployé dans une troisième zone distincte pour une résilience supplémentaire.
La reprise après sinistre s'étend à une deuxième région AWS et à une ou plusieurs zones de disponibilité, comme dans l'exemple précédent. Plusieurs régions DR peuvent être utilisées avec plusieurs cibles de membres miroirs DR Async si nécessaire.
Figure 2.3.1-a : Architecture exemplaire de la production importante avec serveurs d'application ECP.
.png)
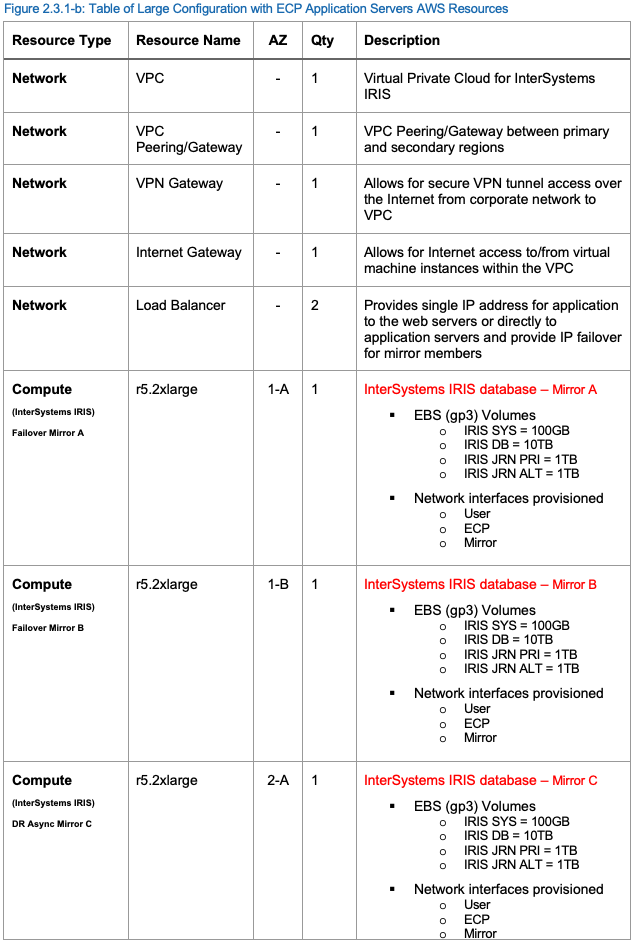
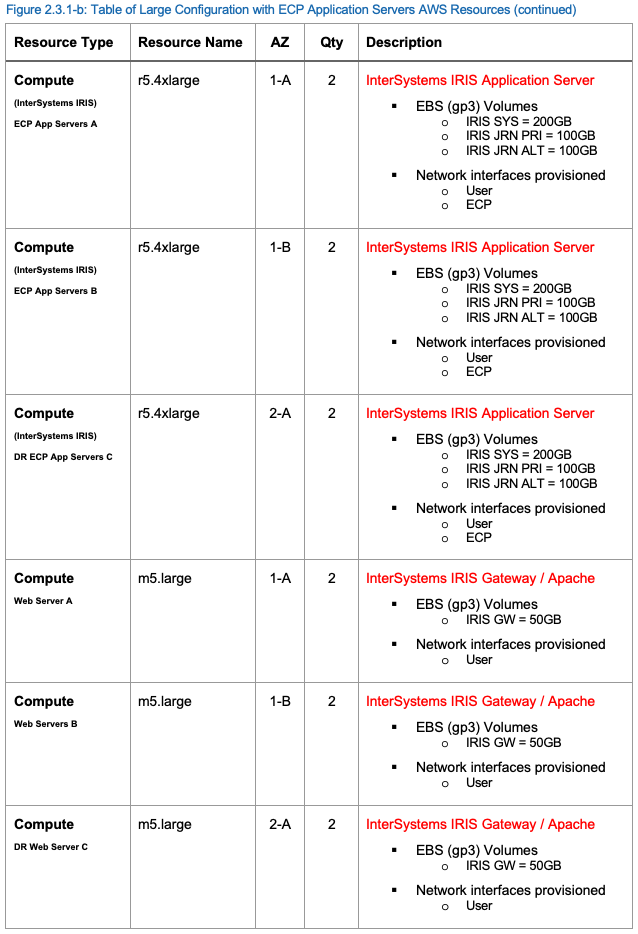
Les ressources suivantes au sein du projet AWS VPC sont recommandées au minimum pour prendre en charge un cluster shard. Les ressources AWS peuvent être ajoutées ou supprimées selon les besoins.
Ressources AWS pour une configuration de la production importante
Un exemple de la configuration de la production importante des ressources AWS est fourni dans le tableau suivant.

Configuration de la production avec InterSystems IRIS Sharded Cluster
Dans cet exemple, une configuration horizontale pour les charges de travail hybrides avec SQL est fournie en incluant les nouvelles capacités d'InterSystems IRIS Sharded Cluster pour fournir une mise à l'échelle horizontale massive des requêtes et des tables SQL sur plusieurs systèmes. Les détails d'InterSystems IRIS Sharded Cluster et de ses capacités sont présentés plus en détail dans la section 9 de cet article.
Diagramme de configuration exemplaire de production avec InterSystems IRIS Sharded Cluster
Le diagramme exemplaire de la Figure 2.4.1-a illustre la table des ressources de la Figure 2.4.1-b. Les passerelles incluses ne sont que des exemples et peuvent être adaptées en fonction des pratiques réseau standard de votre organisation.
Cette configuration comprend quatre paires de miroirs comme nœuds de données. Chacune des paires de miroirs de base de données à basculement est répartie entre deux zones de disponibilité AWS différentes dans la même région pour la protection du domaine de défaillance, avec InterSystems Arbiter et le serveur ICM déployés dans une troisième zone distincte pour une résilience supplémentaire.
Cette configuration permet à toutes les méthodes d'accès à la base de données d'être disponibles à partir de n'importe quel nœud de données du cluster. Les données des grandes tableaux SQL sont physiquement réparties sur tous les nœuds de données pour permettre une parallélisation massive du traitement des requêtes et du volume de données. La combinaison de toutes ces fonctionnalités permet de supporter des charges de travail hybrides complexes, telles que des requêtes SQL analytiques à grande échelle et l'ingestion simultanée de nouvelles données, le tout au sein d'une seule plate-forme de données InterSystems IRIS.
Figure 2.4.1-a : Exemple de configuration de production avec un Sharded Cluster à haute disponibilité
.png)
Notez que dans le diagramme ci-dessus et dans la colonne "type de ressource" du tableau ci-dessous, le terme "EC2" est un terme AWS représentant une instance de serveur virtuel AWS comme décrit plus en détail dans la section 3.1 de ce document. Il ne représente ni n'implique l'utilisation de "nœuds de calcul" dans l'architecture de cluster décrite au chapitre 9.
Les ressources suivantes au sein du VPC AWS sont recommandées au minimum pour prendre en charge un Sharded Cluster. Les ressources AWS peuvent être ajoutées ou supprimées si nécessaire.
Production avec des ressources de Sharded Cluster Configuration AWS/span>
Un exemple de la configuration de la production avec des ressources de Sharded Cluster Configuration AWS est fourni dans le tableau suivant.

Introduction aux Cloud Concepts
Amazon Web Services (AWS) fournit un environnement cloud riche en fonctionnalités pour l'infrastructure en tant que service (IaaS), entièrement capable de prendre en charge tous les produits InterSystems, y compris la prise en charge de DevOps basée sur les conteneurs avec la nouvelle plate-forme de données InterSystems IRIS. Il faut veiller, comme pour toute plateforme ou modèle de déploiement, à prendre en compte tous les aspects d'un environnement tels que les performances, la disponibilité, les opérations système, la haute disponibilité, la reprise après sinistre, les contrôles de sécurité et autres procédures de gestion. Cet article couvre les trois principaux composants de tous les déploiements de cloud computing : Le calcul, le stockage et la mise en réseau.
Moteurs de calcul (machines virtuelles)
Dans AWS EC2, plusieurs options sont disponibles pour les ressources du moteur de calcul avec de nombreuses spécifications de CPU et de mémoire virtuelles et des options de stockage associées. Il convient de noter qu'au sein d'AWS EC2, les références au nombre de vCPU dans un type de machine donné équivalent à un vCPU, soit un hyper-thread sur l'hôte physique au niveau de la couche hyperviseur.
Dans le cadre de ce document, les types d'instance m5* et r5* EC2 seront utilisés et sont les plus largement disponibles dans la plupart des régions de déploiement AWS. Cependant, l'utilisation d'autres types d'instance spécialisés tels que : x1* avec une très grande mémoire sont d'excellentes options pour les très grands ensembles de données de travail conservant des quantités massives de données en mémoire cache, ou i3* avec un stockage d'instance local NVMe. Les détails de l'accord de niveau de service (SLA) d'AWS sont disponibles ici.
Stockage sur disque
Le type de stockage le plus directement lié aux produits InterSystems est celui des types de disques persistants, mais le stockage local peut être utilisé pour des niveaux de performance élevés si les restrictions de disponibilité des données sont comprises et prises en compte. Il existe plusieurs autres options telles que S3 (buckets) et Elastic File Store (EFS), mais elles sont plus spécifiques aux exigences d'une application individuelle qu'au fonctionnement de la plate-forme de données IRIS d'InterSystems.
Comme la plupart des autres fournisseurs de cloud computing, AWS impose des limites à la quantité de stockage persistant qui peut être associée à un moteur de calcul individuel. Ces limites incluent la taille maximale de chaque disque, le nombre de disques persistants attachés à chaque moteur de calcul, et le nombre d'IOPS par disque persistant avec un plafond global d'IOPS par instance de moteur de calcul. En outre, des limites d'IOPS sont imposées par Go d'espace disque, de sorte qu'il est parfois nécessaire de provisionner davantage de capacité disque pour atteindre le taux d'IOPS requis.
Ces limites peuvent se modifier au fil du temps et doivent être confirmées avec AWS, le cas échéant.
Il existe trois types de stockage persistant pour les volumes de disque : EBS gp2 (SSD), EBS st1 (HDD) et EBS io1 (SSD). Les disques EBS gp2 standard sont plus adaptés aux charges de travail de production qui nécessitent des IOPS prévisibles à faible latence et un débit plus élevé. Les disques Persistent standard constituent une option plus économique pour les charges de travail de type développement, test ou archive hors production.
Les détails sur les différents types de disques et leurs limitations sont disponibles ici.
Mise en réseau VPC
Le réseau de cloud privé virtuel (VPC) est fortement recommandé pour prendre en charge les divers composants de la plate-forme de données InterSystems IRIS, tout en fournissant les contrôles de sécurité réseau appropriés, les diverses passerelles, le routage, les attributions d'adresses IP internes, l'isolation des interfaces réseau et les contrôles d'accès. Un exemple de VPC sera détaillé dans les exemples fournis dans ce document.
Les détails de la mise en réseau VPC et des pare-feu sont disponibles ici.
Aperçu du Cloud privé virtuel (VPC)
Les détails d'AWS VPC sont disponibles ici.
Dans la plupart des grands déploiements en nuage, plusieurs VPC sont provisionnés afin d'isoler les différents types de passerelles des VPC applicatifs et de profiter du peering VPC pour les communications entrantes et sortantes. Il est fortement recommandé de consulter votre administrateur réseau pour obtenir des détails sur les sous-réseaux autorisés et les règles de pare-feu de votre entreprise. Le peering VPC n'est pas abordé dans ce document.
Dans les exemples fournis dans ce document, un seul VPC avec trois sous-réseaux sera utilisé pour fournir une isolation réseau des différents composants pour une latence et une bande passante prévisibles et une isolation de sécurité des différents composants d'InterSystems IRIS.
Network Gateway and Subnet Definitions
Deux passerelles sont fournies dans l'exemple de ce document pour prendre en charge la connectivité Internet et la connectivité VPN sécurisée. Chaque accès d'entrée doit être doté de règles de pare-feu et de routage appropriées afin de garantir une sécurité adéquate pour l'application. Les détails sur la façon d'utiliser les Tableaux VPC Route sont disponibles ici.
Trois sous-réseaux sont utilisés dans les exemples d'architectures fournis, dédiés à l'utilisation de la plate-forme de données IRIS d'InterSystems. L'utilisation de ces sous-réseaux et interfaces réseau distincts permet une flexibilité dans les contrôles de sécurité et la protection et la surveillance de la bande passante pour chacun des trois composants majeurs ci-dessus. Les détails de la création d'instances de machines virtuelles avec plusieurs interfaces réseau sont disponibles ici.
Les sous-réseaux inclus dans ces exemples :
- User Space Network pour les utilisateurs connectés et les requêtes
- Shard Network pour les communications entre les noeuds shards
- Réseau miroir pour une haute disponibilité utilisant la réplication synchrone et le basculement automatique des nœuds de données individuels.
Note: La mise en miroir synchrone des bases de données avec basculement n'est recommandée qu'entre plusieurs zones disposant d'interconnexions à faible latence au sein d'une même région AWS. La latence entre les régions est généralement trop élevée pour offrir une expérience positive aux utilisateurs, en particulier pour les déploiements avec un taux élevé de mises à jour.
Équilibreurs de charge internes
La plupart des fournisseurs de cloud computing IaaS ne sont pas en mesure de fournir une adresse IP virtuelle (VIP) qui est généralement utilisée dans les conceptions de basculement automatique de base de données. Pour remédier à ce problème, plusieurs des méthodes de connectivité les plus couramment utilisées, en particulier les clients ECP et les passerelles Web, sont améliorées dans InterSystems IRIS afin de ne plus dépendre des capacités VIP, ce qui les rend sensibles aux miroirs et automatiques.
Connectivity methods such as xDBC, direct TCP/IP sockets, or other direct connect protocols, require the use of a VIP-like address. To support those inbound protocols, InterSystems database mirroring technology makes it possible to provide automatic failover for those connectivity methods within AWS using a health check status page called <span class="Characteritalic" style="font-style:italic">mirror_status.cxw </span> to interact with the load balancer to achieve VIP-like functionality of the load balancer only directing traffic to the active primary mirror member, thus providing a complete and robust high availability design within AWS.
Les détails de l'équilibreur de charge Elastic Load Balancer (ELB) d'AWS sont disponibles ici.
Figure 4.2-a : Basculement automatique sans adresse IP virtuelle
.png)
Les détails de l'utilisation d'un équilibreur de charge pour fournir une fonctionnalité de type VIP sont disponibles ici.
Sample VPC Topology
En combinant tous les composants, l'illustration suivante de la Figure 4.3-a présente la disposition d'un VPC avec les caractéristiques suivantes :
- Exploitation de plusieurs zones au sein d'une région pour une haute disponibilité
- Fourniture deux régions pour la reprise après sinistre
- Utilisation de plusieurs sous-réseaux pour la ségrégation du réseau
- Intégration de passerelles distinctes pour la connectivité VPC Peering, Internet et VPN
- Utilisation d'un équilibreur de charge en nuage pour le basculement IP des membres du miroir
Veuillez noter que dans AWS, chaque sous-réseau doit résider entièrement dans une zone de disponibilité et ne peut pas s'étendre sur plusieurs zones. Ainsi, dans l'exemple ci-dessous, la sécurité du réseau ou les règles de routage doivent être correctement définies. Plus de détails sur les sous-réseaux AWS VPC sont disponibles ici.
Figure 4.3-a : Exemple de topologie de réseau VPC
.png)
Aperçu du stockage persistant
Comme indiqué dans l'introduction, il est recommandé d'utiliser les volumes AWS Elastic Block Store (EBS), et plus particulièrement les types de volumes EBS gp2 ou les plus récents gp3. Les volumes EBS gp3 sont recommandés en raison des taux d'IOPS en lecture et en écriture plus élevés et de la faible latence requise pour les charges de travail des bases de données transactionnelles et analytiques. Les disques SSD locaux peuvent être utilisés dans certaines circonstances, mais il faut savoir que les gains de performance des disques SSD locaux s'accompagnent de certains compromis en termes de disponibilité, de durabilité et de flexibilité.
Les détails de la persistance des données du SSD local sont disponibles ici pour comprendre les événements de quand les données du SSD local sont préservées et quand elles ne le sont pas.
LVM PE Striping
Comme d'autres fournisseurs cloud, AWS impose de nombreuses limites au stockage, tant en termes d'IOPS que de capacité d'espace et de nombre de dispositifs par instance de machine virtuelle. Consultez la documentation d'AWS pour connaître les limites actuelles, qui peuvent être disponibles ici .
Avec ces limites, le striping LVM devient nécessaire pour maximiser l'IOPS au-delà de celui d'un seul périphérique disque pour une instance de base de données. Dans les exemples d'instances de machine virtuelle fournis, les dispositions de disque suivantes sont recommandées. Les limites de performance associées aux disques persistants SSD peuvent être disponibles ici .
Note: Il y a actuellement un maximum de 40 volumes EBS par instance Linux EC2, mais les capacités des ressources AWS changent souvent. Veuillez donc consulter la documentation AWS pour connaître les limites actuelles.
Figure 5.1-a : Exemple d'allocation de groupe de volumes LVM
.png)
Les avantages du striping LVM permettent de répartir les charges de travail IO aléatoires sur un plus grand nombre de périphériques de disque et d'hériter des files d'attente de disque. Vous trouverez ci-dessous un exemple d'utilisation du striping LVM avec Linux pour le groupe de volumes de la base de données. Cet exemple utilise quatre disques dans une bande PE LVM avec une taille d'étendue physique (PE) de 4 Mo. Il est également possible d'utiliser des tailles PE plus importantes si nécessaire.
- Étape 1 : Créez des disques persistants standard ou SSD selon vos besoins
- Etape 2 : L'ordonnanceur IO est NOOP pour chacun des disques en utilisant "lsblk -do NAME,SCHED"
- Etape 3 : Identifier les périphériques de disque en utilisant "lsblk -do KNAME,TYPE,SIZE,MODEL"
- Étape 4 : Créer un groupe de volumes avec de nouveaux périphériques de disque
- vgcreate s 4M <vg name> <liste de tous les disques qui viennent d'être créés>
Étape 4 : Créer un groupe de volumes avec de nouveaux périphériques de disque
- example:
<span style="color:#c0392b;"><i>vgcreate -s 4M vg_iris_db /dev/sd[h-k]</i></span>
- Étape 4 : Créer un volume logique
- lvcreate n <lv name> -L <size of LV> -i <number of disks in volume group> -I 4MB <vg name>
- example:
<i>lvcreate -n lv_irisdb01 -L 1000G -i 4 -I 4M vg_iris_db</i>
- Étape 5 : Créer un système de fichiers
- mkfs.xfs K <périphérique de volume logique>
- example:
<i>mkfs.xfs -K /dev/vg_iris_db/lv_irisdb01</i>
- Étape 6 : Monter le système de fichiers
- éditer /etc/fstab avec les entrées de montage suivantes
- /dev/mapper/vg_iris_db-lv_irisdb01 /vol-iris/db xfs defaults 0 0
- mount /vol-iris/db
En utilisant le tableau ci-dessus, chacun des serveurs InterSystems IRIS aura la configuration suivante avec deux disques pour SYS, quatre disques pour DB, deux disques pour les journaux primaires et deux disques pour les journaux alternatifs.
Figure 5.1-b : Configuration InterSystems IRIS LVM
.png)
Pour la croissance, LVM permet d'étendre les périphériques et les volumes logiques lorsque cela est nécessaire, sans interruption. Consultez la documentation de Linux sur les meilleures pratiques pour la gestion continues et l'expansion des volumes LVM.
Note: TL'activation de l'IO asynchrone à la fois pour la base de données et les fichiers de journal d'image d'écriture sont fortement recommandés. Voir l'article de la communauté pour les détails sur l'activation sous Linux.
Provisionnement
La nouveauté avec InterSystems IRIS est InterSystems Cloud Manager (ICM). ICM exécute de nombreuses tâches et offre de nombreuses options pour le provisionnement d'InterSystems IRIS Data Platform. ICM est fourni sous la forme d'une image Docker qui comprend tous les éléments nécessaires au provisionnement d'une solution robuste basée sur le cloud AWS.
ICM supporte actuellement le provisionnement sur les plateformes suivantes :
- Amazon Web Services avec GovCloud (AWS / GovCloud)
- Google Cloud Plate-forme (GCP)
- Microsoft Azure Resource Manager, avec l'administration (ARM / MAG)
- VMware vSphere (ESXi)
ICM et Docker peuvent fonctionner à partir d'un poste de travail de bureau ou d'un ordinateur portable, ou encore à partir d'un modeste serveur de "provisionnement" et d'un référentiel centralisé.
Le rôle d'ICM dans le cycle de vie des applications est le suivant : Définir -> Approvisionner -> Déployer -> Gérer
Les détails de l'installation et de l'utilisation de la GIC avec Docker sont disponibles ici.
NOTE: L'utilisation d'ICM ne nécessite pas de déploiement cloud. La méthode traditionnelle d'installation et de déploiement avec des distributions tar-ball est entièrement prise en charge et disponible. Cependant, ICM est recommandé pour faciliter le provisionnement et la gestion dans les déploiements cloud.
Container Monitoring
ICM comprend deux dispositifs de surveillance de base pour les déploiements basés sur des conteneurs: Rancheret Weave Scope. Ni l'un ni l'autre ne sont déployés par défaut, et doivent être spécifiés dans le fichier defaults à l'aide du champ Monitor. Les détails de la surveillance, de l'orchestration et de la planification avec ICM sont disponibles ici.
Une présentation de Rancher et une documentation sont disponibles ici.
Une présentation de Weave Scope et une documentation sont disponibles ici.
Haute disponibilité
La mise en miroir des bases de données InterSystems offre le plus haut niveau de disponibilité dans tout environnement en nuage. AWS n'offre aucune garantie de disponibilité pour une seule instance EC2, la mise en miroir de bases de données est donc un niveau de base de données requis qui peut également être couplé à l'équilibrage de charge et aux groupes d'auto-évaluation.
Les sections précédentes ont abordé la manière dont un équilibreur de charge en nuage fournira un basculement automatique de l'adresse IP pour une capacité de type IP virtuelle (VIP) avec une mise en miroir de la base de données. L'équilibreur de charge cloud utilise mirror_status.cxwla page d'état du bilan de santé mentionnée précédemment dans la section Internal Load Balancers. Il existe deux modes de mise en miroir des bases de données : synchrone avec basculement automatique et asynchrone. Dans cet exemple, la mise en miroir synchrone avec basculement automatique sera couverte. Les détails de la mise en miroir sont disponibles ici.
La configuration de mise en miroir la plus élémentaire est une paire de membres miroirs à basculement dans une configuration contrôlée par un arbitre. L'arbitre est placé dans une troisième zone au sein de la même région afin d'éviter que des pannes potentielles de la zone de disponibilité n'affectent à la fois l'arbitre et l'un des membres miroirs.
Il existe de nombreuses façons de configurer le mirroring spécifiquement dans la configuration du réseau. Dans cet exemple, nous allons utiliser les sous-réseaux définis précédemment dans Network Gateway et Subnet Definitions sections de ce document. Des exemples de schémas d'adresses IP seront fournis dans une section suivante. Pour les besoins de cette section, seules les interfaces réseau et les sous-réseaux désignés seront représentés.
Figure 7-a : Exemple de configuration miroir avec arbitre
.png)
Reprise après sinistre
La mise en miroir des bases de données InterSystems étend la capacité de haute disponibilité pour prendre également en charge la reprise après sinistre vers une autre région géographique AWS afin de soutenir la résilience opérationnelle dans le cas peu probable où une région AWS entière serait mise hors ligne. La manière dont une application doit supporter de telles pannes dépend de l'objectif de temps de récupération (RTO) et des objectifs de point de récupération (RPO). Ceux-ci fourniront le cadre initial de l'analyse nécessaire à la conception d'un plan de reprise après sinistre approprié. Le lien suivant fournit un guide des éléments à prendre en compte lors de l'élaboration d'un plan de reprise après sinistre pour votre application. https://aws.amazon.com/disaster-recovery/
Mise en miroir asynchrone des bases de données
La mise en miroir des bases de données InterSystems IRIS Data Platform offre des fonctionnalités robustes pour la réplication asynchrone des données entre les zones de disponibilité et les régions AWS afin de soutenir les objectifs RTO et RPO de votre plan de reprise après sinistre. Les détails des membres de la mise en miroir asynchrone sont disponibles ici.
Comme dans la section précédente sur la haute disponibilité, un équilibreur de charge cloud fournira un basculement automatique d'adresse IP pour une capacité d'IP virtuelle (de type VIP) pour la mise en miroir asynchrone DR également en utilisant la même mirror_status.cxwpage d'état de contrôle de santé mentionnée précédemment dans la section d'Équilibreurs de charge internes.
Dans cet exemple, la mise en miroir de basculement asynchrone DR sera couverte ainsi que l'introduction du service AWS Route53 DNS pour fournir aux systèmes ascendants et aux postes de travail clients une adresse DNS unique, quelle que soit la zone de disponibilité ou la région dans laquelle votre déploiement InterSystems IRIS fonctionne.
Les détails de AWS Route53 sont disponibles ici.
Figure 8.1-a: Sample DR Asynchronous Mirroring with AWS Route53
.png)
Dans l'exemple ci-dessus, les adresses IP de l'équilibreur de charge Elastic Load Balancer (ELB) des deux régions qui sont en tête des instances InterSystems IRIS sont fournies à Route53, et ce dernier ne dirigera le trafic que vers le membre miroir qui est le miroir primaire actif, quelle que soit la zone de disponibilité ou la région où il se trouve.
Cluster Sharded
IInterSystems IRIS comprend un ensemble complet de fonctionnalités permettant de faire évoluer vos applications, qui peuvent être appliquées seules ou en combinaison, selon la nature de votre charge de travail et les défis de performance spécifiques auxquels elle fait face. L'une d'entre elles, le sharding, répartit les données et leur cache associé sur plusieurs serveurs, ce qui permet de faire évoluer les performances des requêtes et de l'ingestion de données de manière flexible et peu coûteuse, tout en maximisant la valeur de l'infrastructure grâce à une utilisation très efficace des ressources. Un cluster sharded InterSystems IRIS peut offrir des avantages significatifs en termes de performances pour une grande variété d'applications, mais surtout pour celles dont la charge de travail comprend un ou plusieurs des éléments suivants :
- L'ingestion de données à haut volume ou à grande vitesse, ou une combinaison de ces éléments.
- Des ensembles de données relativement importants, des requêtes qui renvoient de grandes quantités de données, ou les deux.
- Les requêtes complexes qui effectuent de grandes quantités de traitement de données, comme celles qui analysent beaucoup de données sur disque ou qui impliquent un travail de calcul important.
Chacun de ces facteurs influence à lui seul le gain potentiel du sharding, mais l'avantage peut être renforcé lorsqu'ils se combinent. Par exemple, la combinaison de ces trois facteurs (grandes quantités de données ingérées rapidement, grands ensembles de données et requêtes complexes qui récupèrent et traitent beaucoup de données) fait de la plupart des charges de travail analytiques actuelles de très bons candidats pour le sharding.
Notez que ces caractéristiques sont toutes liées aux données ; la fonction principale d'InterSystems IRIS sharding est de s'adapter au volume de données. Cependant, un cluster sharded peut également inclure des fonctionnalités qui évoluent en fonction du volume d'utilisateurs, lorsque les charges de travail impliquant certains ou tous ces facteurs liés aux données connaissent également un volume de requêtes très élevé de la part d'un grand nombre d'utilisateurs. Le sharding peut également être combiné à une mise à l'échelle verticale.
Aperçu opérationnel
Au cœur de l'architecture sharded se trouve le partitionnement des données et de leur cache associé sur plusieurs systèmes. Un cluster sharded partitionne physiquement les grandes tableaux de base de données horizontalement - c'est-à-dire par ligne - sur plusieurs instances InterSystems IRIS, appelées nœuds de données, tout en permettant aux applications d'accéder de manière transparente à ces tableaux par le biais de n'importe quel nœud et de continuer à voir l'ensemble des données comme une seule union logique. Cette architecture offre trois avantages :
Les requêtes sont exécutées en parallèle sur les nœuds de données, les résultats étant fusionnés, combinés et renvoyés à l'application en tant que résultats complets de la requête par le nœud auquel l'application s'est connectée, ce qui améliore considérablement la vitesse d'exécution dans de nombreux cas.
- Mise en cache partitionnée
Chaque nœud de données dispose de son propre cache, dédié à la partition de données de la table sharded qu'il stocke, plutôt que le cache d'une instance unique desservant l'ensemble des données, ce qui réduit considérablement le risque de déborder du cache et de forcer des lectures sur disque dégradant les performances.
Les données peuvent être chargées sur les nœuds de données en parallèle, ce qui réduit les conflits de cache et de disque entre la charge de travail d'ingestion et la charge de travail d'interrogation et améliore les performances des deux.
Les détails du cluster sharded InterSystems IRIS sont disponibles ici.
Éléments du sharding et types d'instance
Un cluster sharded se compose d'au moins un nœud de données et, si nécessaire pour des performances spécifiques ou des exigences de charge de travail, d'un nombre optionnel de nœuds de calcul. Ces deux types de nœuds offrent des blocs de construction simples présentant un modèle de mise à l'échelle simple, transparent et efficace.
Data Nodes
Les nœuds de données stockent les données. Au niveau physique, les données du tableau shardedsont réparties sur tous les nœuds de données du cluster et les données du tableau non sharded sont physiquement stockées sur le premier nœud de données uniquement. Cette distinction est transparente pour l'utilisateur, à l'exception peut-être du fait que le premier nœud pourrait avoir une consommation de stockage légèrement plus élevée que les autres, mais cette différence devrait devenir négligeable, car les données du tableau sharded dépassent généralement les données du tableau non sharded d'au moins un ordre de grandeur.
Les données des tableaux sharded peuvent être rééquilibrées dans le cluster si nécessaire, généralement après l'ajout de nouveaux nœuds de données. Cette opération permet de déplacer des "seaux" de données entre les nœuds afin d'obtenir une distribution plus ou moins égale des données.
Au niveau logique, les données des tableaux non shardés et l'union de toutes les données des tableaux shardés sont visibles depuis n'importe quel nœud, de sorte que les clients verront l'ensemble des données, quel que soit le nœud auquel ils se connectent. Les métadonnées et le code sont également partagés entre tous les nœuds de données.
Le diagramme d'architecture de base d'un cluster sharded se compose simplement de nœuds de données qui apparaissent uniformément dans le cluster. Les applications clientes peuvent se connecter à n'importe quel nœud et percevront les données comme si elles étaient locales.
Figure 9.2.1-a : Diagramme de base d'un cluster sharded
Nœuds de calcul
Pour les scénarios avancés nécessitant de faibles latences, potentiellement en contradiction avec un afflux constant de données, des nœuds de calcul peuvent être ajoutés afin de fournir une couche de mise en cache transparente pour le traitement des requêtes.
Les nœuds de calcul stockent les données en cache. Chaque nœud de calcul est associé à un nœud de données pour lequel il met en cache les données du tableau sharded correspondant et, en plus de cela, il met également en cache les données du tableau non sharded si nécessaire, pour satisfaire les requêtes.
Figure 9.2.2-a : Cluster shared avec nœuds de calcul
.png)
Comme les nœuds de calcul ne stockent physiquement aucune donnée et qu'ils sont destinés à prendre en charge l'exécution de requêtes, leur profil matériel peut être adapté à ces besoins, par exemple en privilégiant la mémoire et le processeur et en limitant le stockage au strict minimum. L'ingestion est transmise aux nœuds de données, soit directement par le pilote (xDBC, Spark), soit implicitement par le code du gestionnaire de sharding lorsque le code d'application "nu" s'exécute sur un nœud de calcul.
Illustrations de cluster sharded
Le déploiement d'un cluster sharded peut se faire de différentes manières. Les diagrammes de haut niveau suivants sont fournis pour illustrer les modèles de déploiement les plus courants. Ces diagrammes n'incluent pas les passerelles et les détails du réseau et se concentrent uniquement sur les composants du cluster sharded.
Cluster sharded de base
Le schéma suivant représente le cluster sharded le plus simple avec quatre nœuds de données déployés dans une seule région et dans une seule zone. Un équilibreur de charge AWS Elastic Load Balancer (ELB) est utilisé pour distribuer les connexions des clients à l'un des nœuds du cluster sharded
Figure 9.3.1-a: Basic Sharded Cluster
.png)
Dans ce modèle de base, il n'y a pas de résilience ou de haute disponibilité au-delà de ce que AWS fournit pour une seule machine virtuelle et son stockage SSD persistant attaché. Deux adaptateurs d'interface réseau distincts sont recommandés pour assurer à la fois l'isolation de la sécurité du réseau pour les connexions client entrantes et l'isolation de la bande passante entre le trafic client et les communications du cluster sharded.
Cluster Sharded de base avec haute disponibilité
Le diagramme suivant représente le cluster sharded le plus simple avec quatre nœuds de données miroir déployés dans une seule région et divisant le miroir de chaque nœud entre les zones. Un équilibreur de charge AWS est utilisé pour distribuer les connexions des clients à l'un des nœuds du cluster sharded.
La haute disponibilité est assurée par l'utilisation de la mise en miroir des bases de données InterSystems, qui maintient un miroir répliqué de manière synchrone dans une zone secondaire de la région.
Trois adaptateurs d'interface réseau distincts sont recommandés pour assurer à la fois l'isolation de la sécurité du réseau pour les connexions client entrantes et l'isolation de la bande passante entre le trafic client, les communications du cluster sharded et le trafic du miroir synchrone entre les paires de nœuds.
Figure 9.3.2-a : Cluster sharded de base avec haute disponibilité
.png)
Ce modèle de déploiement introduit également un arbitre miroir tel que celui décrit dans une section précédente de cet article.
Cluster sharded avec des nœuds de calcul séparés
Le diagramme suivant développe le cluster sharded pour une concurrence massive entre les utilisateurs et les requêtes avec des nœuds de calcul séparés et quatre nœuds de données. Le pool de serveurs Cloud Load Balancer contient uniquement les adresses des nœuds de calcul. Les mises à jour et l'ingestion de données continueront d'être effectuées directement sur les nœuds de données, comme auparavant, afin de maintenir des performances à très faible latence et d'éviter les interférences et l'encombrement des ressources entre les charges de travail de requête/analyse provenant de l'ingestion de données en temps réel.
Grâce à ce modèle, l'allocation des ressources peut être affinée pour la mise à l'échelle des calculs/requêtes et de l'ingestion de manière indépendante, ce qui permet d'optimiser les ressources là où elles sont nécessaires, en "juste à temps", et de conserver une solution économique mais simple, au lieu de gaspiller inutilement des ressources pour la mise à l'échelle des calculs ou des données.
Les nœuds de calcul se prêtent à une utilisation très simple du regroupement automatique AWS (alias Autoscaling) pour permettre l'ajout ou la suppression automatique d'instances d'un groupe d'instances géré en fonction de l'augmentation ou de la diminution de la charge. L'autoscaling fonctionne en ajoutant des instances à votre groupe d'instances lorsqu'il y a plus de charge (upscaling), et en supprimant des instances lorsque le besoin d'instances diminue (downscaling).
Les détails de la mise à l'échelle automatique d'AWS ssont disponibles ici.
Figure 9.3.3-a : Cluster Sharded avec des nœuds de calcul et de données séparés
.png)
L'auto-scaling aide les applications basées sur le cloud à gérer de manière élégante les augmentations de trafic et réduit les coûts lorsque le besoin en ressources est moindre. Il suffit de définir la politique et l'auto-mesureur effectue une mise à l'échelle automatique en fonction de la charge mesurée.
Opérations de sauvegarde
Il existe de multiples options pour les opérations de sauvegarde. Les trois options suivantes sont viables pour votre déploiement AWS avec InterSystems IRIS.
TLes deux premières options, détaillées ci-dessous, intègrent une procédure de type instantané qui implique la suspension des écritures de la base de données sur le disque avant la création de l'instantané, puis la reprise des mises à jour une fois l'instantané réussi.
Les étapes de haut niveau suivantes sont suivies pour créer une sauvegarde propre en utilisant l'une ou l'autre des méthodes instantanées :
- Pause des écritures dans la base de données via un appel de la base de données External Freeze API.
- Créez des instantanés de l'OS + des disques de données.
- Reprendre les écritures de la base de données via l'appel External Thaw API..
- Sauvegarde des archives de l'installation vers un emplacement de sauvegarde
Les détails de External Freeze/Thaw API sont disponibles ici.
Note: Des exemples de scripts pour les sauvegardes ne sont pas inclus dans ce document, mais il faut régulièrement vérifier les exemples postés dans la communauté InterSystems Developer Community. www.community.intersystems.com La troisième option est la sauvegarde en ligne InterSystems. Il s'agit d'une approche d'entrée de gamme pour les petits déploiements avec un cas d'utilisation et une interface très simples. Cependant, à mesure que la taille des bases de données augmente, les sauvegardes externes avec la technologie des instantanés sont recommandées comme meilleure pratique, avec des avantages tels que la sauvegarde des fichiers externes, des temps de restauration plus rapides et une vue des données et des outils de gestion à l'échelle de l'entreprise.
Des étapes supplémentaires, telles que les contrôles d'intégrité, peuvent être ajoutées périodiquement pour garantir une sauvegarde propre et cohérente.
Le choix de l'option à utiliser dépend des exigences et des politiques opérationnelles de votre organisation. InterSystems est à votre disposition pour discuter plus en détail des différentes options.
Sauvegarde des instantanés de l'AWS Elastic Block Store (EBS)
Les opérations de sauvegarde peuvent être réalisées à l'aide de l'API de ligne de commande AWS CLI et des capacités API ExternalFreeze/Thaw d'InterSystems. Cela permet une véritable résilience opérationnelle 24 heures sur 24, 7 jours sur 7, et l'assurance de sauvegardes régulières et propres. Les détails de la gestion, de la création et de l'automatisation des snapshots AWS EBS sont disponibles à l'adresse suivante ici.
Instantanés du Logical Volume Manager (LVM)
Il est également possible d'utiliser un grand nombre d'outils de sauvegarde tiers disponibles sur le marché en déployant des agents de sauvegarde individuels dans la VM elle-même et en exploitant les sauvegardes au niveau des fichiers conjointement avec les instantanés du Logical Volume Manager (LVM).
L'un des principaux avantages de ce modèle est la possibilité d'effectuer des restaurations au niveau des fichiers des machines virtuelles basées sur Windows ou Linux. Il convient de noter que, comme AWS et la plupart des autres fournisseurs de cloud IaaS ne fournissent pas de bandes magnétiques, tous les référentiels de sauvegarde sont sur disque pour l'archivage à court terme et peuvent exploiter un stockage à faible coût de type blob ou bucket pour la rétention à long terme (LTR). Si vous utilisez cette méthode, il est fortement recommandé d'utiliser un produit de sauvegarde qui prend en charge les technologies de déduplication afin d'utiliser le plus efficacement possible les référentiels de sauvegarde sur disque.
Quelques exemples de ces produits de sauvegarde ayant une prise en charge dans le cloud incluent, sans y être limités, sont les suivants : Commvault, EMC Networker, HPE Data Protector et Veritas Netbackup. InterSystems ne valide ni n'approuve un produit plutôt qu'un autre.
Sauvegarde en ligne
Pour les petits déploiements, la fonction intégrée de sauvegarde en ligne Online Backup est également une option viable. Cet utilitaire de sauvegarde en ligne des bases de données InterSystems sauvegarde les données dans les fichiers de base de données en capturant tous les blocs dans les bases de données, puis écrit la sortie dans un fichier séquentiel. Ce mécanisme de sauvegarde propriétaire est conçu pour ne pas causer de temps d'arrêt aux utilisateurs du système de production. Les détails de la sauvegarde en ligne sont disponibles ici.
Dans AWS, une fois la sauvegarde en ligne terminée, le fichier de sortie de la sauvegarde et tous les autres fichiers utilisés par le système doivent être copiés vers un autre emplacement de stockage en dehors de cette instance de machine virtuelle. Le stockage de type "Bucket/Object" est une bonne désignation pour cela.
Il existe deux options pour utiliser un bucket AWS Single Storage Space (S3).
- Utilisez les AWS CLIscripting APIs directement pour copier et manipuler les fichiers de sauvegarde en ligne (et autres fichiers non liés à la base de données) nouvellement créés
- Les détails sont disponibles ici.
- Montez un volume Elastic File Store (EFS) et utilisez-le de la même manière qu'un disque persistant à faible coût.
- Les détails de l'EFS sont disponibles ici.
.png)
