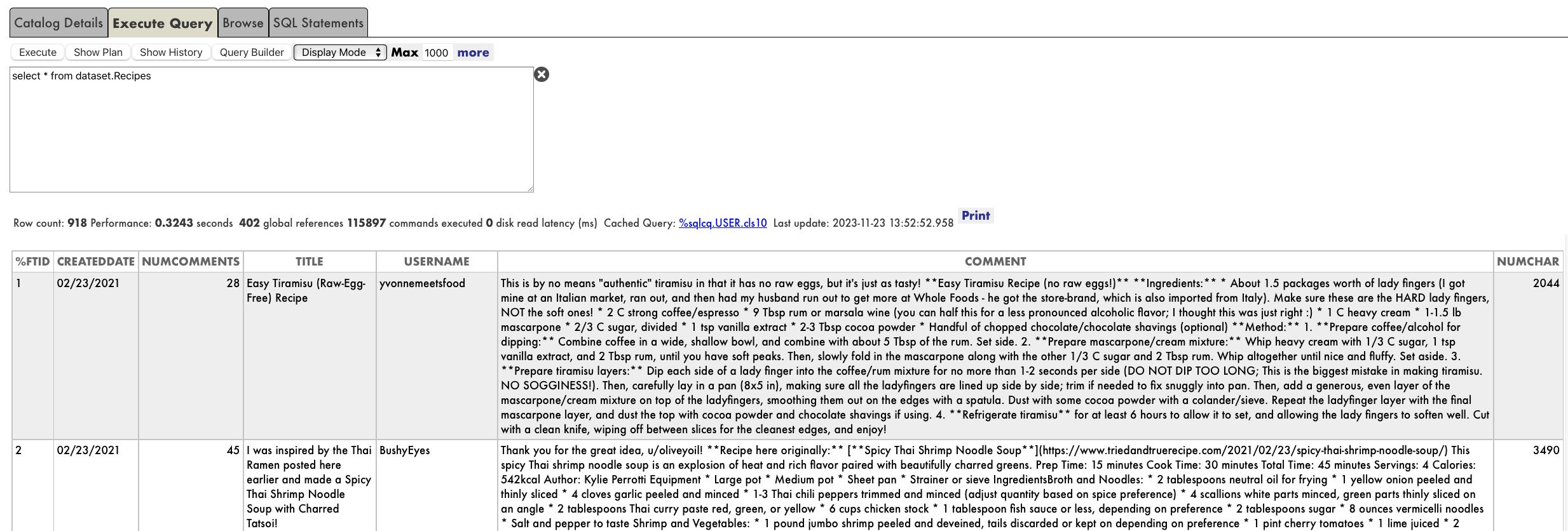
L'utilisation traditionnelle d'une production IRIS consiste, pour un adaptateur entrant, à recevoir des données d'une source externe, à envoyer ces données à un service IRIS, puis à faire en sorte que ce service envoie ces données par l'intermédiaire de la production.
.png)
Cependant, grâce à un adaptateur entrant personnalisé, nous pouvons faire en sorte qu'une production IRIS soit plus performante. Nous pouvons utiliser une production IRIS pour traiter les données de notre propre base de données sans aucun déclencheur externe.
.png)
BEn utilisant une production IRIS de cette manière, vos tâches de traitement des données peuvent désormais tirer parti de toutes les fonctionnalités intégrées d'une production IRIS, y compris:
- Suivi et contrôle avancés
- Traitement multithread pour l'évolutivité
- Logique métier basée sur la configuration
- Opérations IRIS intégrées pour se connecter rapidement à des systèmes externes
- Récupération rapide des défaillances du système
La documentation pour créer un adaptateur entrant personnalisé peut être consultée à: https://docs.intersystems.com/hs20231/csp/docbook/DocBook.UI.Page.cls?KEY=EGDV_adv#EGDV_adv_adapterdev_inbound
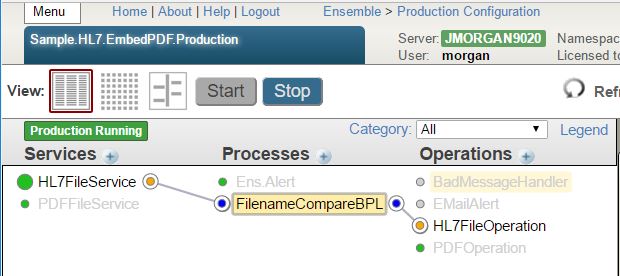
Regardons 3 exemples d'une production simple configurée pour traiter des objets "Fish" à partir d'une base de données.
Dans le premier exemple, nous allons créer une production pilotée par les données qui traitera continuellement les données.
Dans le deuxième exemple, nous modifierons cette production pour traiter les données uniquement à des moments précis.
Dans le troisième exemple, nous modifierons cette production pour traiter les données uniquement lorsqu'elles sont déclenchées via une tâche système.
Exemple 1: Traitement continu des données
Cet exemple est une simple production configurée pour traiter continuellement des objets "Fish" à partir d'une base de données. Tout ce que fait la production est de rechercher continuellement de nouveaux objets fish, de convertir ces objets fish en JSON, puis de recracher ce JSON dans un fichier.
.png)
Tout d'abord, nous créons l'objet Fish que nous avons l'intention de traiter:
Class Sample.Fish Extends (%Persistent, Ens.Util.MessageBodyMethods, %JSON.Adaptor, %XML.Adaptor)
{
Parameter ENSPURGE As%Boolean = 0Property Type As%StringProperty Size As%NumericProperty FirstName As%StringProperty Status As%String [ InitialExpression = "Initialized" ]
Index StatusIndex On Status
}
L'état est important car c'est ainsi que nous distinguerons l'état des objets fish non traités de l'état des objets traités.
En fixant ENSPURGE à 0 empêchera cet objet d'être purgé avec les en-têtes du message à l'avenir.
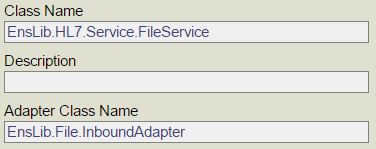
Deuxièmement, nous créons un adaptateur personnalisé pour rechercher les nouveaux objets fish:
Class Sample.Adapter.FishMonitorAdapter Extends Ens.InboundAdapter
{
Property GetFishStatus As%String [ InitialExpression = "Initialized", Required ]Property SetFishStatus As%String [ InitialExpression = "Processed", Required ]Parameter SETTINGS = "GetFishStatus:Basic,SetFishStatus:Basic"Parameter SERVICEINPUTCLASS = "Sample.Fish"
Method OnTask() As%Status
{
set getFishStatus = ..GetFishStatus
&sql(declare fishCursor cursorforselectIDinto :fishId
from Sample.Fish
whereStatus = :getFishStatus)
&sql(open fishCursor)
for {
&sql(fetch fishCursor)
quit:SQLCODE'=0set fishObj = ##class(Sample.Fish).%OpenId(fishId)
set fishObj.Status = ..SetFishStatus$$$ThrowOnError(fishObj.%Save())
$$$ThrowOnError(..BusinessHost.ProcessInput(fishObj))
}
&sql(close fishCursor)
if SQLCODE < 0 {
throw##class(%Exception.SQL).CreateFromSQLCODE(SQLCODE,%msg)
}
quit$$$OK
}
La méthode OnTask() recherche tous les objet Fish correspondant à la valeur GetFishStatus configurée. Pour chaque objet Fish trouvé, elle modifie son état en fonction de la valeur SetFishStatus configurée, puis le transmet à la méthode ProcessInput du service.
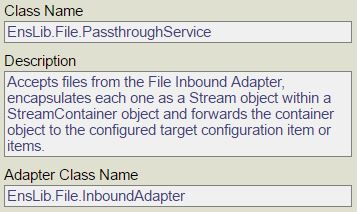
Troisièmement, nous créons un service personnalisé pour utiliser cet adaptateur:
Class Sample.Service.FishMonitorService Extends Ens.BusinessService
{
Property TargetConfigName As Ens.DataType.ConfigNameParameter SETTINGS = "TargetConfigName:Basic"Parameter ADAPTER = "Sample.Adapter.FishMonitorAdapter"
Method OnProcessInput(pInput As Sample.Fish, pOutput As%RegisteredObject) As%Status
{
quit:..TargetConfigName=""quit..SendRequestAsync(..TargetConfigName, pInput)
}
}
Ce service prend les objet Fish en entrée et les transmet via une requête asynchrone à la cible configurée.
Quatrièmement, nous créons un processus métier personnalisé pour convertir l'objet Fish en JSON.
Class Sample.Process.FishToJSONProcess Extends Ens.BusinessProcess
{
Property TargetConfigName As Ens.DataType.ConfigNameParameter SETTINGS = "TargetConfigName:Basic"
Method OnRequest(pRequest As Sample.Fish, Output pResponse As Ens.Response) As%Status
{
do pRequest.%JSONExportToStream(.jsonFishStream)
set tRequest = ##class(Ens.StreamContainer).%New(jsonFishStream)
quit..SendRequestAsync(..TargetConfigName, tRequest, 0)
}
Method OnResponse(request As Ens.Request, ByRef response As Ens.Response, callrequest As Ens.Request, callresponse As Ens.Response, pCompletionKey As%String) As%Status
{
quit$$$OK
}
}
La méthode OnRequest() est la seule méthode qui agisse. Il accepte l'objet Fish, génère un flux JSON à partir de l'objet Fish, conditionne ce flux dans un conteneur Ens.StreamContainer, puis transmet ce conteneur de flux via une requête asynchrone à la cible configurée.
Enfin, nous configurons la production:
Class Sample.DataProduction Extends Ens.Production
{
XData ProductionDefinition
{
<Production Name="Sample.DataProduction" LogGeneralTraceEvents="false">
<Description></Description>
<ActorPoolSize>2</ActorPoolSize>
<Item Name="Sample.Service.FishMonitorService" Category="" ClassName="Sample.Service.FishMonitorService" PoolSize="1" Enabled="true" Foreground="false" Comment="" LogTraceEvents="false" Schedule="">
<Setting Target="Host" Name="TargetConfigName">Sample.Process.FishToJSONProcess</Setting>
</Item>
<Item Name="Sample.Process.FishToJSONProcess" Category="" ClassName="Sample.Process.FishToJSONProcess" PoolSize="1" Enabled="true" Foreground="false" Comment="" LogTraceEvents="false" Schedule="">
<Setting Target="Host" Name="TargetConfigName">EnsLib.File.PassthroughOperation</Setting>
</Item>
<Item Name="EnsLib.File.PassthroughOperation" Category="" ClassName="EnsLib.File.PassthroughOperation" PoolSize="1" Enabled="true" Foreground="false" Comment="" LogTraceEvents="false" Schedule="">
<Setting Target="Adapter" Name="FilePath">C:\temp\fish\</Setting>
</Item>
</Production>
}
}
.png)
Il ne reste plus qu'à la tester. Pour cela, il suffit d'ouvrir une fenêtre de terminal et de créer un nouvel objet Fish.
.png)
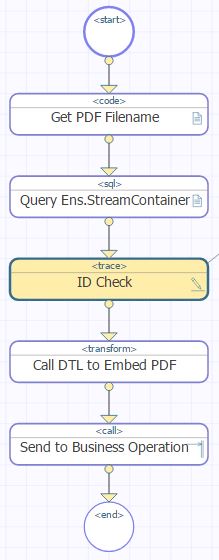
En regardant les messages de production, nous pouvons voir que l'objet Fish a été trouvé et transformé:

Nous pouvons inspecter la trace des deux messages:


En regardant le dossier de sortie (C:\temp\fish\), nous pouvons voir le fichier de sortie:
.png)
Exemple 2: Traitement des données basé sur les horaires
Pour les cas d'utilisation où nous ne voulons traiter les données qu'à des moments précis, comme la nuit, nous pouvons configurer le service pour qu'il s'exécute selon des horaires précis.
Pour modifier l'exemple 1 pour qu'il fonctionne selon des horaires, nous créons d'abord une spécification de l'horaire. La documentation sur la manière de procéder est disponible ici: https://docs.intersystems.com/iris20231/csp/docbook/DocBook.UI.PortalHelpPage.cls?KEY=Ensemble%2C%20Schedule%20Editor

Ensuite, nous modifions la configuration du service pour utiliser cet horaire:
Class Sample.DataProduction Extends Ens.Production
{
XData ProductionDefinition
{
<Production Name="Sample.DataProduction" LogGeneralTraceEvents="false">
<Description></Description>
<ActorPoolSize>2</ActorPoolSize>
<Item Name="Sample.Service.FishMonitorService" Category="" ClassName="Sample.Service.FishMonitorService" PoolSize="1" Enabled="true" Foreground="false" Comment="" LogTraceEvents="false" Schedule="@Midnight Processing">
<Setting Target="Host" Name="TargetConfigName">Sample.Process.FishToJSONProcess</Setting>
</Item>
<Item Name="Sample.Process.FishToJSONProcess" Category="" ClassName="Sample.Process.FishToJSONProcess" PoolSize="1" Enabled="true" Foreground="false" Comment="" LogTraceEvents="false" Schedule="">
<Setting Target="Host" Name="TargetConfigName">EnsLib.File.PassthroughOperation</Setting>
</Item>
<Item Name="EnsLib.File.PassthroughOperation" Category="" ClassName="EnsLib.File.PassthroughOperation" PoolSize="1" Enabled="true" Foreground="false" Comment="" LogTraceEvents="false" Schedule="">
<Setting Target="Adapter" Name="FilePath">C:\temp\fish\</Setting>
</Item>
</Production>
}
}
.png)
Maintenant, lorsque nous regardons cet onglet "Tâches" du service, nous voyons qu'il n'y a aucun tâche en cours:
Désormais, ce service n'aura plus que des tâches à exécuter entre minuit et 1 heure du matin.
Exemple 3: Traitement de données sur la base des événements avec le Gestionnaire de tâches
Pour les cas d'utilisation où nous ne voulons traiter les données qu'une seule fois à un moment précis ou lorsqu'un événement particulier a lieu, nous pouvons configurer le service pour qu'il ne s'exécute que lors de l'exécution d'une tâche système.
.png)
Pour modifier l'exemple 1 afin qu'il ne s'exécute que lorsqu'il est déclenché par une tâche, nous créons d'abord une tâche personnalisée pour déclencher le service.
Class Sample.Task.TriggerServiceTask Extends%SYS.Task.Definition
{
Property BuinessServiceName As%String [ Required ]
Method OnTask() As%Status
{
#dim pBusinessService As Ens.BusinessService
$$$ThrowOnError(##class(Ens.Director).CreateBusinessService(..BuinessServiceName, .pBusinessService))
Quit pBusinessService.OnTask()
}
}
Deuxièmement, nous configurons une nouvelle tâche système. La documentation sur la configuration des tâches système est disponible ici: https://docs.intersystems.com/iris20233/csp/docbook/Doc.View.cls?KEY=GSA_manage_taskmgr
Ceci est la partie personnalisée du processus de configuration pour cet exemple:

En outre, je configure la tâche pour qu'elle soit exécutée à la demande, mais vous pouvez aussi établir un horaire.
Enfin, nous configurons la production:
Class Sample.DataProduction Extends Ens.Production
{
XData ProductionDefinition
{
<Production Name="Sample.DataProduction" LogGeneralTraceEvents="false">
<Description></Description>
<ActorPoolSize>2</ActorPoolSize>
<Item Name="Sample.Service.FishMonitorService" Category="" ClassName="Sample.Service.FishMonitorService" PoolSize="0" Enabled="true" Foreground="false" Comment="" LogTraceEvents="false" Schedule="">
<Setting Target="Host" Name="TargetConfigName">Sample.Process.FishToJSONProcess</Setting>
</Item>
<Item Name="Sample.Process.FishToJSONProcess" Category="" ClassName="Sample.Process.FishToJSONProcess" PoolSize="1" Enabled="true" Foreground="false" Comment="" LogTraceEvents="false" Schedule="">
<Setting Target="Host" Name="TargetConfigName">EnsLib.File.PassthroughOperation</Setting>
</Item>
<Item Name="EnsLib.File.PassthroughOperation" Category="" ClassName="EnsLib.File.PassthroughOperation" PoolSize="1" Enabled="true" Foreground="false" Comment="" LogTraceEvents="false" Schedule="">
<Setting Target="Adapter" Name="FilePath">C:\temp\fish\</Setting>
</Item>
</Production>
}
}
Notez que nous avons fixé le PoolSize de Sample.Service.FishMonitorService à 0.
Il ne reste plus qu'à la tester. Pour cela, il suffit d'ouvrir une fenêtre de terminal et de créer un nouvel objet Fish.

En regardant les messages de production, nous pouvons voir que l'objet Fish n'a pas encore été transformé:

Ensuite, nous exécutons la tâche à la demande pour déclencher le service:

Maintenant, en regardant les messages de production, nous pouvons voir que le service a été déclenché, ce qui a permis de trouver et de traiter l'objet Fish:

Nous pouvons inspecter la trace des deux messages:


En regardant le dossier de sortie (C:\temp\fish\), nous pouvons voir le fichier de sortie:

Conclusion
Les exemples ci-dessus sont assez simples. Vous pouvez cependant configurer les productions pour en faire beaucoup plus. Y compris…
En fait, il est possible de réaliser ici tout ce qui peut être fait dans le cadre d'une production typique d'IRIS.