
Dans cette section, nous allons découvrir comment utiliser Python comme langage principal dans IRIS, ce qui vous permettra d'écrire la logique de votre application en Python tout en profitant de la puissance d'IRIS.
- Introduction à l'approche "Python d'abord" dans IRIS
- Section supplémentaire
- Conclusion
Utilisation (irispython)
Tout d'abord, nous allons commencer par la méthode officielle, qui consiste à la mise en œuvre de l'interpréteur irispython.
Vous pouvez utiliser l'interpréteur irispython pour exécuter du code Python directement dans IRIS. Cela vous permet d'écrire du code Python et de l'exécuter dans le contexte de votre application IRIS.
Qu'est-ce qu'irispython?
irispython est un interpréteur Python qui se trouve dans le répertoire d'installation d'IRIS (<installation_directory>/bin/irispython) et qui sert à exécuter du code Python dans le contexte d'IRIS.
Cela vous permettra :
- De configurer
sys.pathpour inclure les bibliothèques et les modules Python IRIS.- Cela est réalisé par le fichier
site.py, qui se trouve dans<installation_directory>/lib/python/iris_site.py. - Pour plus d'informations, consultez l'article sur les modules Introduction aux modules Python.
- Cela est réalisé par le fichier
- Vous pourrez ainsi importer les modules
iris, qui sont des modules spéciaux permettant d'accéder aux fonctionnalités IRIS, telles que la conversion de n'importe quelle classe ObjectScript vers Python, et réciproquement. - Vous pourrez corriger les problèmes d'autorisations et le chargement dynamique des bibliothèques du noyau iris.
Exemple d'utilisation d'irispython
Vous pouvez exécuter l'interpréteur irispython à partir de la ligne de commande:
<installation_directory>/bin/irispython
Prenons un exemple simple:
# src/python/article/irispython_example.py
import requests
import iris
def run():
response = requests.get("https://2eb86668f7ab407989787c97ec6b24ba.api.mockbin.io/")
my_dict = response.json()
for key, value in my_dict.items():
print(f"{key}: {value}") # print message: Hello World
return my_dict
if __name__ == "__main__":
print(f"Iris version: {iris.cls('%SYSTEM.Version').GetVersion()}")
run()
Vous pouvez lancer ce script à l'aide de l'interpréteur irispython:
<installation_directory>/bin/irispython src/python/article/irispython_example.py
Vous verrez le résultat:
Iris version: IRIS for UNIX (Ubuntu Server LTS for x86-64 Containers) 2025.1 (Build 223U) Tue Mar 11 2025 18:23:31 EDT
message: Hello World
Il est présenté ici comment utiliser l'interpréteur irispython pour exécuter du code Python dans le contexte d'IRIS.
Avantages
- Python d'abord : vous pouvez écrire la logique de votre application en Python, ce qui vous permet de profiter des fonctionnalités et des bibliothèques de Python.
- Intégration IRIS : vous pouvez facilement intégrer votre code Python aux fonctionnalités et aux caractéristiques d'IRIS.
Inconvénients
- Débogage limité : le débogage du code Python dans
irispythonn'est pas aussi simple que dans un environnement Python dédié.- Cela ne signifie pas que c'est impossible, mais ce n'est pas aussi facile que dans un environnement Python dédié.
- Consultez la Section supoplémentaire for more details.
- Environnement virtuel : il est difficile de configurer un environnement virtuel pour votre code Python dans
irispython.- Cela ne signifie pas que c'est impossible, mais c'est difficile à réaliser à cause de l'environnement virtuel qui recherche par défaut un interpréteur appelé
pythonoupython3, ce qui n'est pas le cas dans IRIS. - Consultez la Section supoplémentaire for more details.
- Cela ne signifie pas que c'est impossible, mais c'est difficile à réaliser à cause de l'environnement virtuel qui recherche par défaut un interpréteur appelé
Conclusion
En conclusion, en utilisant irispython, vous pouvez écrire la logique de votre application en Python tout en profitant de la puissance d'IRIS. Cependant, cet outil présente certaines limites en matière de débogage et de configuration de l'environnement virtuel.
Utilisation de WSGI
Dans cette section, nous allons découvrir comment utiliser WSGI (Interface de passerelle serveur Web) pour exécuter des applications Web Python dans IRIS.
WSGI est une interface standard entre les serveurs Web et les applications ou frameworks Web Python. Elle vous permet d'exécuter des applications Web Python dans un environnement de serveur Web.
IRIS prend en charge WSGI, ce qui signifie que vous pouvez exécuter des applications Web Python dans IRIS à l'aide du serveur WSGI intégré.
Utilisation
Pour utiliser WSGI dans IRIS, vous devez créer une application WSGI et l'enregistrer auprès du serveur web IRIS.
Pour plus de détails, consultez la documentation officielle.
Exemple d'utilisation de WSGI
Vous trouverez un template complet ici iris-flask-example.
Avantages
- Frameworks Web Python : Pour créer vos applications Web, vous pouvez utiliser des frameworks Web Python populaires tels que Flask ou Django.
- Intégration IRIS : Vous pouvez intégrer vos applications Web Python aux fonctionnalités IRIS en toute simplicité.
Inconvénients
- Complexité : la configuration d'une application WSGI peut s'avérer plus complexe en comparaison avec une simple utilisation de
uvicornougunicornavec un framework web Python.
Conclusion
En conclusion, l'utilisation de WSGI dans IRIS vous permet de créer des applications web puissantes à l'aide de Python tout en profitant des fonctionnalités et des capacités d'IRIS.
DB-API
Dans cette section, nous allons découvrir comment utiliser l'API Python DB pour interagir avec les bases de données IRIS.
L'API Python DB est une interface standard pour se connecter à des bases de données en Python. Elle vous permet d'exécuter des requêtes SQL et de récupérer les résultats dans la base de données.
Utilisation
Vous pouvez l'installer en utilisant pip:
pip install intersystems-irispython
Ensuite, vous pouvez utiliser l'API DB pour la connexion à une base de données IRIS et exécuter des requêtes SQL.
Exemple d'utilisation de DB-API
Vous l'utilisez comme n'importe quelle autre API Python DB. Voici un exemple:
# src/python/article/dbapi_example.py
import iris
def run():
# Connexion à la base de données IRIS
# Ouverture d'une connexion au serveur
args = {
'hostname':'127.0.0.1',
'port': 1972,
'namespace':'USER',
'username':'SuperUser',
'password':'SYS'
}
conn = iris.connect(**args)
# Création d'un curseur
cursor = conn.cursor()
# Exécution d'une requête
cursor.execute("SELECT 1")
# Récupération de tous les résultats
results = cursor.fetchall()
for row in results:
print(row)
# Fermeture du curseur et de la connexion
cursor.close()
conn.close()
if __name__ == "__main__":
run()
Ce script peut être exécuté à l'aide de n'importe quel interpréteur Python:
python3 /irisdev/app/src/python/article/dbapi_example.py
Vous verrez le résultat:
(1,)
Avantages
- Interface standard : l'API DB fournit une interface standard pour se connecter aux bases de données, ce qui facilite le passage d'une base de données à l'autre.
- Requêtes SQL : vous pouvez exécuter des requêtes SQL et récupérer les résultats de la base de données à l'aide de Python.
- Accès à distance : vous pouvez vous connecter à des bases de données IRIS distantes à l'aide de l'API DB.
Inconvénients
- Fonctionnalités limitées : l'API DB fournit uniquement un accès SQL à la base de données. Vous ne pourrez donc pas utiliser les fonctionnalités avancées d'IRIS telles que l'exécution de code ObjectScript ou Python.
Alternatives
Il existe également une édition communautaire de la DB-API, disponible ici : intersystems-irispython-community.
Elle offre une meilleure prise en charge de SQLAlchemy, Django, langchain et d'autres bibliothèques Python qui utilisent la DB-API.
Pour plus de détail, consultez la Section supplémentaire.
Conclusion
En conclusion, l'utilisation de l'API Python DB avec IRIS vous permet de créer des applications puissantes capables d'interagir de manière transparente avec votre base de données.
Notebook
Après avoir vu comment utiliser Python dans IRIS, nous allons découvrir comment utiliser Jupyter Notebooks avec IRIS.
Jupyter Notebooks est un excellent moyen d'écrire et d'exécuter du code Python de manière interactive. Il peut être utilisé avec IRIS pour profiter de ses fonctionnalités.
Utilisation
Pour utiliser Jupyter Notebooks avec IRIS, vous devez installer les packages notebook et ipykernel:
pip install notebook ipykernel
Ensuite, vous pouvez créer un nouveau Jupyter Notebook et sélectionner le noyau Python 3.
Exemple d'utilisation de Notebook
Vous pouvez créer un nouveau Jupyter Notebook et écrire le code suivant:
# src/python/article/my_notebook.ipynb
# Importation des modules nécessaires
import iris
# La magie
iris.system.Version.GetVersion()
Vous pouvez exécuter ce notebook à l'aide de Jupyter Notebook:
jupyter notebook src/python/article/my_notebook.ipynb
Avantages
- Développement interactif : les notebooks Jupyter vous permettent d'écrire et d'exécuter du code Python de manière interactive, ce qui est idéal pour l'analyse et l'exploration de données.
- Résulltat riche : vous pouvez afficher des résultats riches, tels que des graphiques et des tableaux, directement dans le notebook.
- Documentation : vous pouvez ajouter de la documentation et des explications à côté de votre code, ce qui rend
Inconvénients
- Configuration délicate : la configuration des notebooks Jupyter avec IRIS peut s'avérer délicate, en particulier au niveau de la configuration du noyau.
Conclusion
Pour conclure, l'utilisation des notebooks Jupyter avec IRIS vous permet d'écrire et d'exécuter du code Python de manière interactive tout en profitant des fonctionnalités d'IRIS. Cependant, la configuration peut s'avérer délicate, en particulier au niveau du noyau.
Section supplémentaire
À partir de cette section, nous aborderons certains sujets avancés liés à Python dans IRIS, tels que le débogage à distance du code Python ou encore l'utilisation d'environnements virtuels.
La plupart de ces sujets ne sont pas officiellement pris en charge par InterSystems, mais il est utile de les aborder si vous souhaitez utiliser Python dans IRIS.
Utilisation d'un interpréteur natif (sans irispython)
Dans cette section, nous allons voir comment utiliser un interpréteur Python natif au lieu de l'interpréteur irispython.
Cela vous permet d'utiliser des environnements virtuels prêts à l'emploi et d'utiliser l'interpréteur Python auquel vous êtes habitué.
Utilisation
Pour utiliser un interpréteur Python natif, vous devez installer IRIS localement sur votre machine et disposer du package iris-embedded-python-wrapper installé.
Vous pouvez l'installer avec pip:
pip install iris-embedded-python-wrapper
Ensuite, vous devez configurer certaines variables d'environnement pour faire référence à votre installation IRIS:
export IRISINSTALLDIR=<installation_directory>
export IRISUSERNAME=<username>
export IRISPASSWORD=<password>
export IRISNAMESPACE=<namespace>
Ensuite, vous pouvez exécuter votre code Python à l'aide de votre interpréteur Python natif:
python3 src/python/article/irispython_example.py
# src/python/article/irispython_example.py
import requests
import iris
def run():
response = requests.get("https://2eb86668f7ab407989787c97ec6b24ba.api.mockbin.io/")
my_dict = response.json()
for key, value in my_dict.items():
print(f"{key}: {value}") # message d'impression: Hello World
return my_dict
if __name__ == "__main__":
print(f"Iris version: {iris.cls('%SYSTEM.Version').GetVersion()}")
run()
Pour plus de détails; consultez iris-embedded-python-wrapper documentation.
Avantages
- Environnements virtuels : vous pouvez utiliser des environnements virtuels avec votre interpréteur Python natif, ce qui vous permet de gérer plus facilement les dépendances.
- Workflow familier : vous pouvez utiliser votre interpréteur Python habituel, ce qui facilite l'intégration avec vos flux de travail existants.
- Débogage : vous pouvez utiliser vos outils de débogage Python préférés, tels que
pdbouipdb, pour déboguer votre code Python dans IRIS.
Inconvénients
- Complexité de la configuration : la configuration des variables d'environnement et du package
iris-embedded-python-wrapperpeut s'avérer complexe, en particulier pour les débutants. - Non pris en charge officiellement : cette approche n'est pas prise en charge officiellement par InterSystems. Vous risquez donc de rencontrer des problèmes qui ne sont pas documentés ni pris en charge.
Edition communautaire de DB-API
Dans cette section, nous allons explorer l'édition communautaire de l'API DB, disponible sur GitHub.
Utilisation
Vous pouvez l'installer avec pip:
pip install sqlalchemy-iris
Cette option installe l'édition communautaire de DB-API.
Ou avec une version spécifique:
pip install https://github.com/intersystems-community/intersystems-irispython/releases/download/3.9.3/intersystems_iris-3.9.3-py3-none-any.whl
Ensuite, vous pouvez utiliser l'API DB pour vous connecter à une base de données IRIS et exécuter des requêtes SQL ou tout autre code Python qui utilise l'API DB, comme SQLAlchemy, Django, langchain, pandas, etc.
Exemple d'utilisation de DB-API
Vous pouvez l'utiliser comme n'importe quelle autre API Python DB. Exemple:
# src/python/article/dbapi_community_example.py
import intersystems_iris.dbapi._DBAPI as dbapi
config = {
"hostname": "localhost",
"port": 1972,
"namespace": "USER",
"username": "_SYSTEM",
"password": "SYS",
}
with dbapi.connect(**config) as conn:
with conn.cursor() as cursor:
cursor.execute("select ? as one, 2 as two", 1) # le deuxième argument est la valeur du paramètre
for row in cursor:
one, two = row
print(f"one: {one}")
print(f"two: {two}")
Vous pouvez exécuter ce script à l'aide de n'importe quel interpréteur Python:
python3 /irisdev/app/src/python/article/dbapi_community_example.py
Ou à l'aide de sqlalchemy:
from sqlalchemy import create_engine, text
COMMUNITY_DRIVER_URL = "iris://_SYSTEM:SYS@localhost:1972/USER"
OFFICIAL_DRIVER_URL = "iris+intersystems://_SYSTEM:SYS@localhost:1972/USER"
EMBEDDED_PYTHON_DRIVER_URL = "iris+emb:///USER"
def run(driver):
# Création d'un moteur à l'aide du pilote officiel
engine = create_engine(driver)
with engine.connect() as connection:
# Exécution d'une requête
result = connection.execute(text("SELECT 1 AS one, 2 AS two"))
for row in result:
print(f"one: {row.one}, two: {row.two}")
if __name__ == "__main__":
run(OFFICIAL_DRIVER_URL)
run(COMMUNITY_DRIVER_URL)
run(EMBEDDED_PYTHON_DRIVER_URL)
Vous pouvez exécuter ce script à l'aide de n'importe quel interpréteur Python:
python3 /irisdev/app/src/python/article/dbapi_sqlalchemy_example.py
Vous verrez le résultat:
one: 1, two: 2
one: 1, two: 2
one: 1, two: 2
Avantages
- Meilleur prise en charge : il offre une meilleure prise en charge de SQLAlchemy, Django, langchain et d'autres bibliothèques Python qui utilisent l'API DB.
- Développé par la communauté : il est maintenu par la communauté, ce qui signifie qu'il est susceptible d'être mis à jour et amélioré au fil du temps.
- Compatibilité : il est compatible avec l'API DB officielle d'InterSystems, vous pouvez donc passer facilement de l'édition officielle à l'édition communautaire.
Inconvénients
- Vitesse : la version communautaire n'est peut-être pas aussi optimisée que la version officielle, ce qui peut entraîner des performances plus lentes dans certains cas.
Débogage de code Python dans IRIS
Dans cette section, nous allons voir comment déboguer du code Python dans IRIS.
Par défaut, le débogage du code Python dans IRIS (dans objectscript avec la balise de langage ou %SYS.Python) n'est pas possible, mais la communauté a trouvé une solution pour vous permettre de déboguer le code Python dans IRIS.
Utilisation
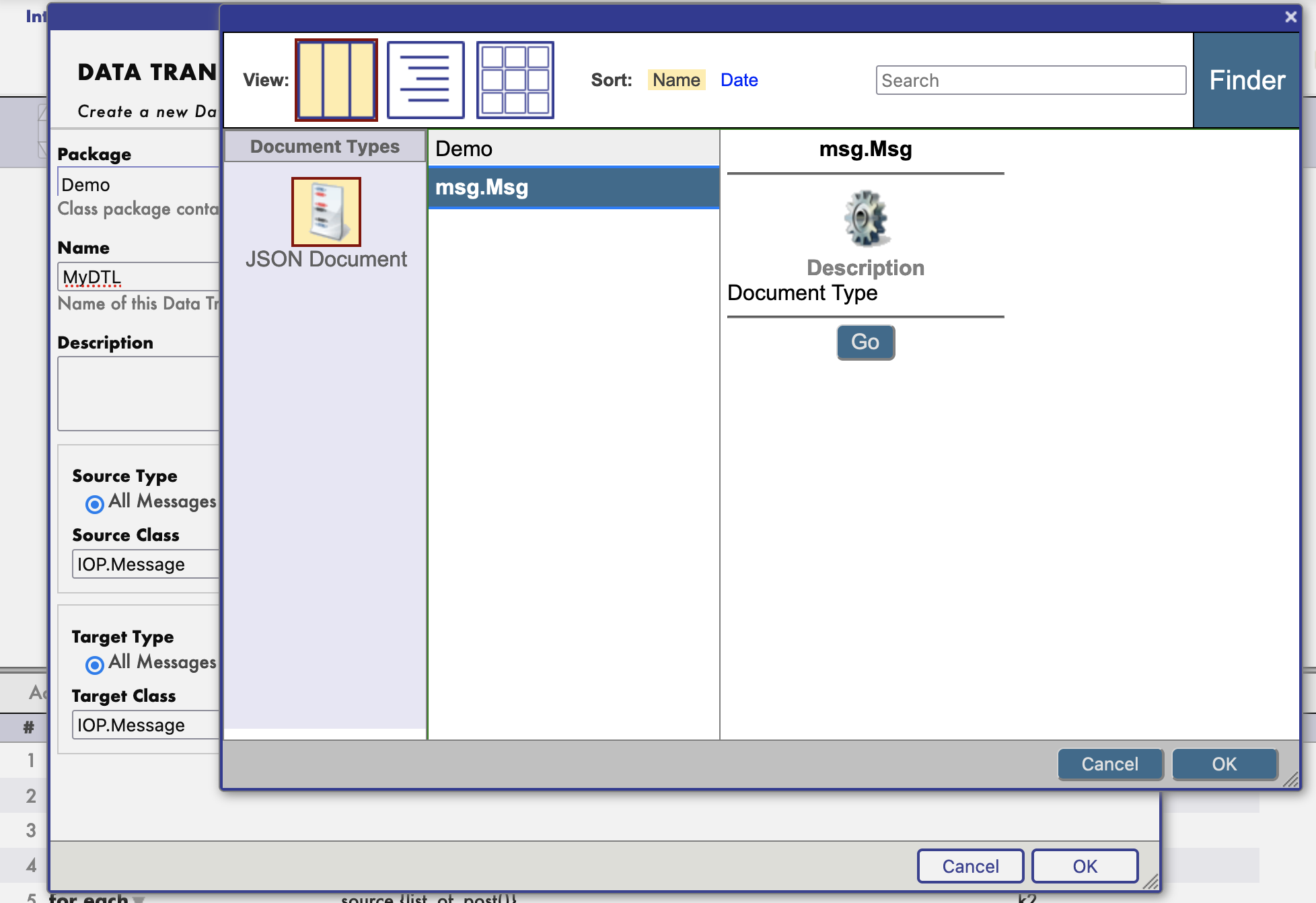
Installez d'abord IoP Interopérabilité en Python:
pip install iris-pex-embedded-python
iop --init
Cela installera IoP et les nouvelles classes ObjectScript qui vous permettront de déboguer le code Python dans IRIS.
Ensuite, vous pouvez utiliser la classe IOP.Wrapper pour encapsuler votre code Python et activer le débogage.
Class Article.DebuggingExample Extends %RegisteredObject
{
ClassMethod Run() As %Status
{
set myScript = ##class(IOP.Wrapper).Import("my_script", "/irisdev/app/src/python/article/", 55550) // Ajustez le chemin d'accès à votre module
Do myScript.run()
Quit $$$OK
}
}
Configurez ensuite VsCode pour utiliser le débogueur IoP en ajoutant la configuration suivante à votre fichier launch.json:
{
"version": "0.2.0",
"configurations": [
{
"name": "Python in IRIS",
"type": "python",
"request": "attach",
"port": 55550,
"host": "localhost",
"pathMappings": [
{
"localRoot": "${workspaceFolder}/src/python/article",
"remoteRoot": "/irisdev/app/src/python/article"
}
]
}
]
}
Vous pouvez désormais exécuter votre code ObjectScript qui importe le module Python, puis connecter le débogueur dans VsCode au port 55550.
Vous pouvez exécuter ce script à l'aide de la commande suivante:
iris session iris -U IRISAPP '##class(Article.DebuggingExample).Run()'
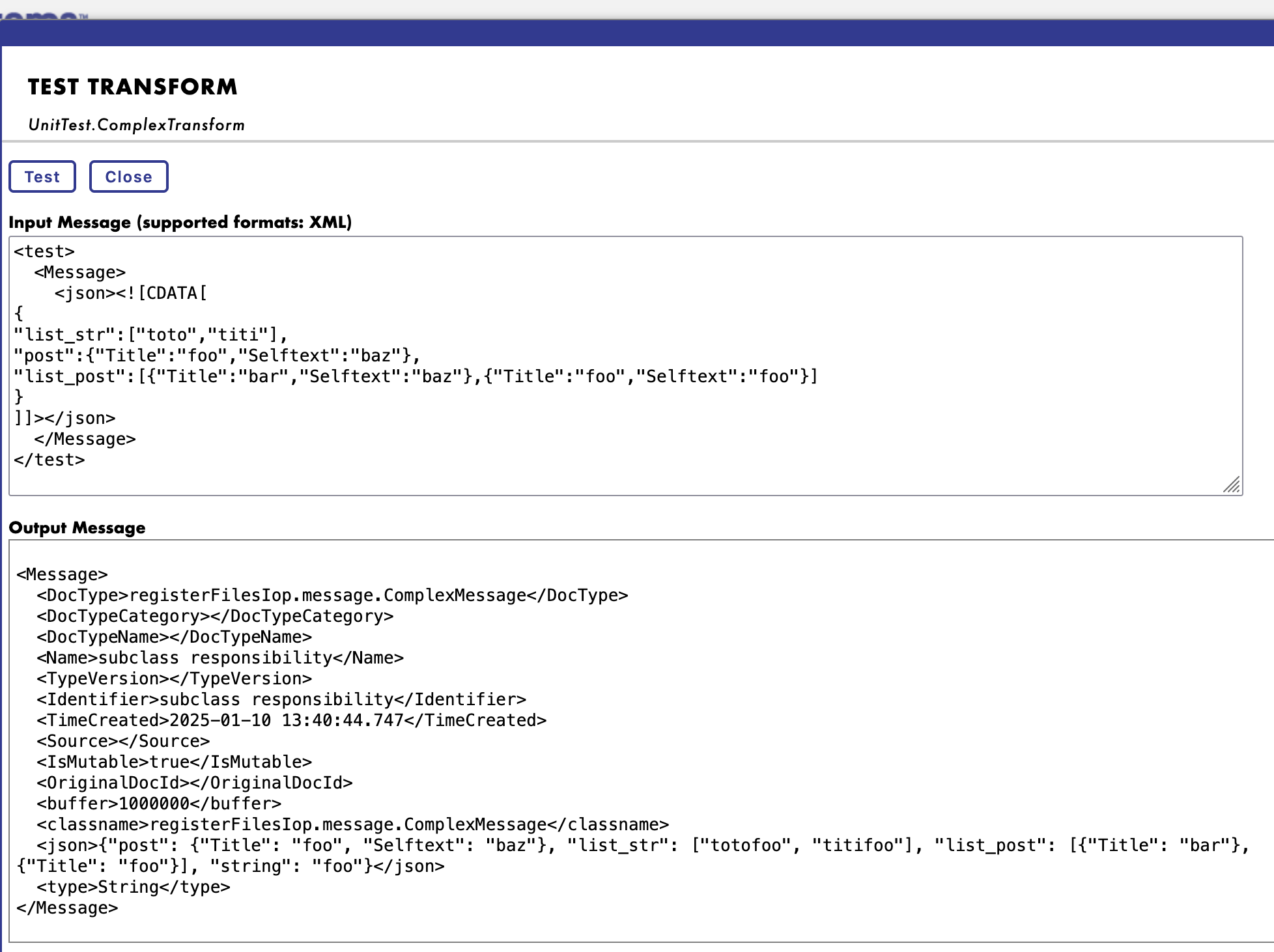
Vous pouvez ensuite définir des points d'arrêt dans votre code Python, et le débogueur s'arrêtera à ces points d'arrêt, ce qui vous permettra d'inspecter les variables et de parcourir le code.
Vidéo de débogage à distance en action (pour IoP, mais le concept est le même):
Et vous disposez également de tracebacks dans votre code Python, ce qui est très utile pour le débogage.
Avec les tracebacks activés:
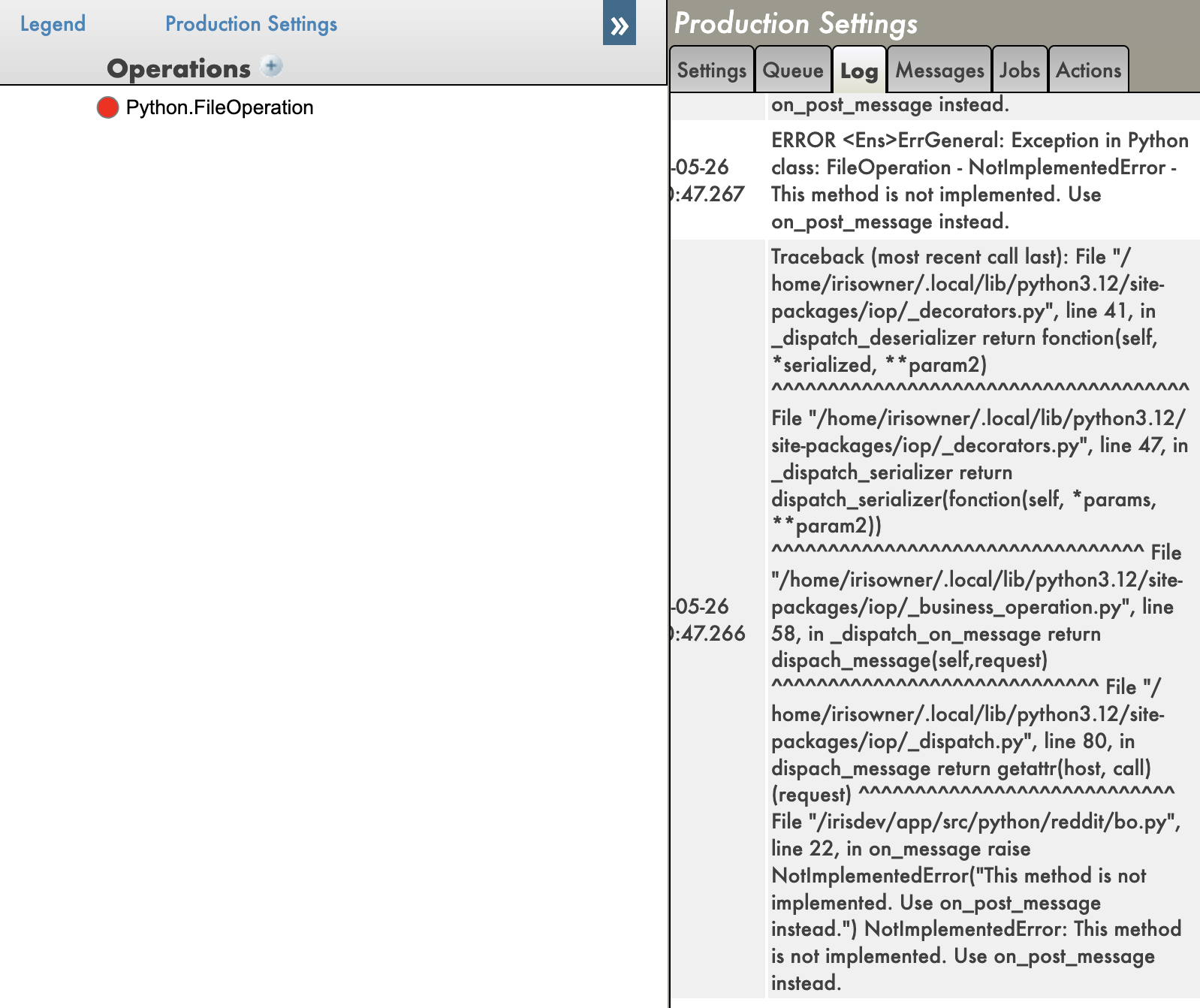
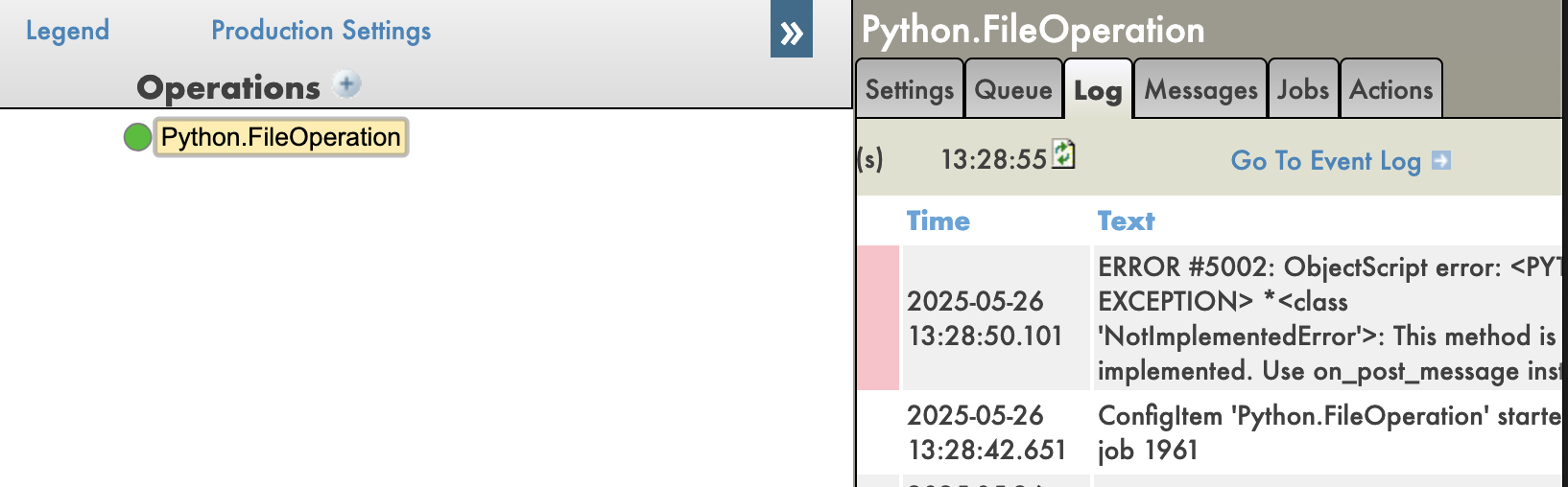
Avec les tracebacks désactivés:
Avantages
- Débogage à distance : vous pouvez déboguer à distance le code Python exécuté dans IRIS, ce qui, à mon avis, change la donne.
- Fonctionnalités de débogage Python : vous pouvez utiliser toutes les fonctionnalités de débogage Python, telles que les points d'arrêt, l'inspection des variables et l'exécution du code pas à pas.
- Tracebacks : vous pouvez voir le traceback complet des erreurs dans votre code Python, ce qui est très utile pour le débogage.
Inconvénients
- Complexité de la configuration : La configuration de l'IoP et du débogueur peut s'avérer complexe, en particulier pour les débutants.
- Solution communautaire : Il s'agit d'une solution communautaire, qui peut donc être moins stable ou moins bien documentée que les solutions officielles.
Conclusion
En conclusion, le débogage de code Python dans IRIS est possible grâce à la solution communautaire IoP, qui vous permet d'utiliser le débogueur Python pour déboguer votre code Python exécuté dans IRIS. Cependant, cela nécessite une certaine configuration et peut ne pas être aussi stable que les solutions officielles.
IoP (Interopérabilité en Python)
Dans cette section, nous allons explorer la solution IoP (Interopérabilité en Python), qui vous permet d'exécuter du code Python dans IRIS dans une approche "Python d'abord".
Je développe cette solution depuis un certain temps déjà, c'est mon bébé, elle essaie de résoudre ou d'améliorer tous les points précédents que nous avons vus dans cette série d'articles.
Points clés de l'IoP:
- Python d'abord : vous pouvez écrire la logique de votre application en Python, ce qui vous permet de profiter des fonctionnalités et des bibliothèques de Python.
- Intégration IRIS : vous pouvez facilement intégrer votre code Python aux fonctionnalités et aux caractéristiques d'IRIS.
- Débogage à distance : vous pouvez déboguer à distance votre code Python exécuté dans IRIS.
- Tracebacks : vous pouvez voir le traceback complet des erreurs dans votre code Python, ce qui est très utile pour le débogage.
- Environnements virtuels : vous bénéficiez d'une prise en charge des environnements virtuels, ce qui vous permet de gérer plus facilement les dépendances.
Pour en savoir plus sur IoP, vous pouvez consulter la documentation officielle.
Vous pouvez ensuite lire les articles suivants pour en savoir plus sur IoP:
🐍❤️ Comme vous pouvez le constater, IoP offre un moyen puissant d'intégrer Python à IRIS, ce qui facilite le développement et le débogage de vos applications.
Vous n'avez plus besoin d'utiliser irispython, vous n'avez plus à définir manuellement votre sys.path, vous pouvez utiliser des environnements virtuels et vous pouvez déboguer votre code Python exécuté dans IRIS.
Conclusion
J'espère que vous avez apprécié cette série d'articles sur Python dans IRIS.
N'hésitez pas à me contacter si vous avez des questions ou des commentaires à propos de cette série d'articles.
Bonne chance, amusez-vous avec Python dans IRIS!


.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)