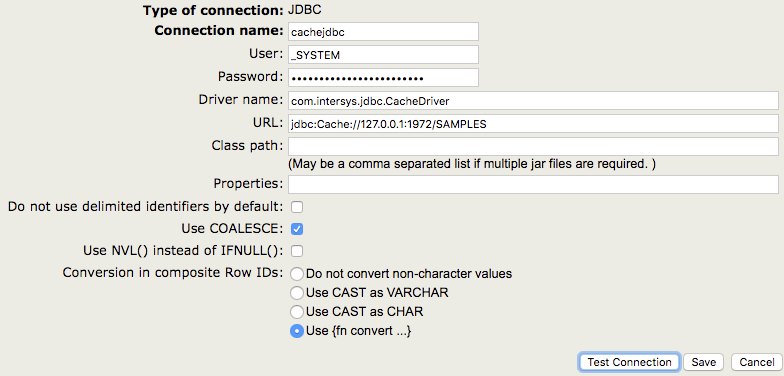
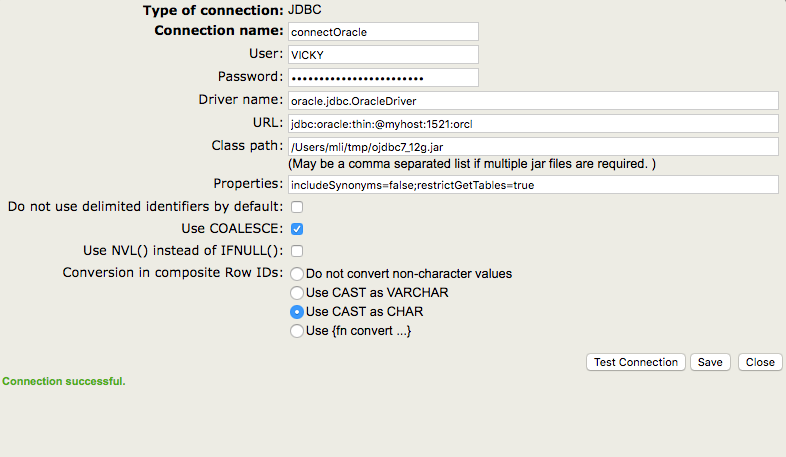
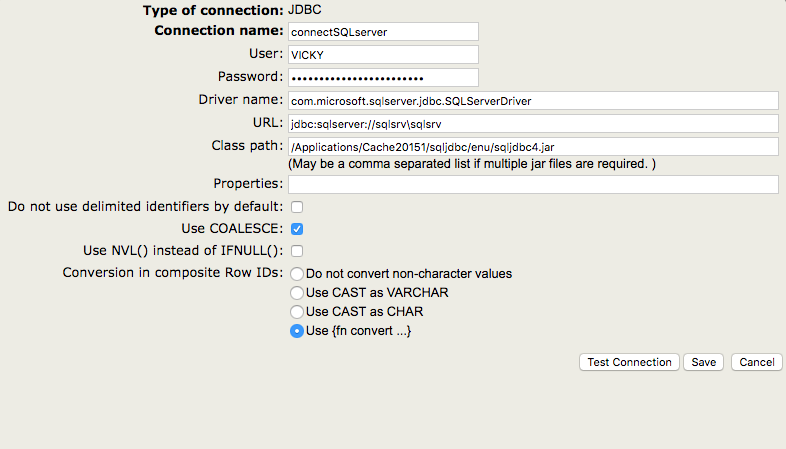
En tant qu'ancien développeur de JAVA, j'ai toujours eu du mal à décider quelle base de données était la plus appropriée pour le projet à développer. L'un des principaux critères que j'utilisais était la performance, ainsi que les capacités de configuration de HA (haute disponibilité). Eh bien, il est maintenant temps de mettre IRIS à l'épreuve en ce qui concerne certaines bases de données les plus couramment utilisées, j'ai donc décidé de créer un petit projet Java basé sur SpringBoot qui se connecte via JDBC avec une base de données MySQL, avec une autre base de données PostgreSQL et enfin avec une base de données IRIS.
Nous allons profiter du fait de disposer d'images Docker de ces bases de données pour les utiliser dans notre projet et vous permettre de l'essayer vous-même sans avoir à procéder à une quelconque installation. Nous pouvons vérifier la configuration du docker dans notre fichier docker-compose.yml
version:"2.2"services: mysql: build: context:mysql container_name:mysql restart:always command:--default-authentication-plugin=mysql_native_password environment: MYSQL_ROOT_PASSWORD:SYS MYSQL_USER:testuser MYSQL_PASSWORD:testpassword MYSQL_DATABASE:test volumes: -./mysql/sql/dump.sql:/docker-entrypoint-initdb.d/dump.sql ports: -3306:3306 postgres: build: context:postgres container_name:postgres restart:always environment: POSTGRES_USER:testuser POSTGRES_PASSWORD:testpassword volumes: -./postgres/sql/dump.sql:/docker-entrypoint-initdb.d/dump.sql ports: -5432:5432 adminer: container_name:adminer image:adminer restart:always depends_on: -mysql -postgres ports: -8081:8080 iris: init:true container_name:iris build: context:. dockerfile:iris/Dockerfile ports: -52773:52773 -1972:1972 command:--check-capsfalse tomcat: init:true container_name:tomcat build: context:. dockerfile:tomcat/Dockerfile volumes: -./tomcat/performance.war:/usr/local/tomcat/webapps/performance.war ports: -8080:8080
D'un coup d'œil rapide, nous constatons que nous utilisons les images suivantes :
- IRIS: Instance de la Communauté IRIS à laquelle nous nous connecterons par JDBC.
- Postgres: Image de base de données PostgreSQL sur le port 5432.
- MySQL: Image de base de données MySQL sur le port 3306
- Tomcat: Image Docker configurée avec un serveur d'application Apache Tomcat sur lequel nous allons déployer le fichier WAR de notre application.
- Adminer: Administrateur de base de données qui nous permettra de consulter les bases de données Postgres et MySQL.
Comme vous pouvez le voir, nous avons configuré les ports de listening de manière à ce qu'ils soient également mappés sur notre ordinateur, et pas seulement au sein de Docker. Pour les bases de données, ce n'est pas nécessaire, car la connexion se fait dans les conteneurs Docker, donc si vous avez des problèmes avec les ports, vous pouvez supprimer la ligne de prots de votre fichier docker-compose.yml.
Chaque image de base de données exécute un pré-script qui créera les tables nécessaires aux tests de performance. Examinons l'un des fichiers dump.sql
CREATESCHEMAtest;
DROPTABLEIFEXISTS test.patient;
CREATETABLE test.country (
idINT PRIMARY KEY,
nameVARCHAR(225)
);
CREATETABLE test.city (
idINT PRIMARY KEY,
nameVARCHAR(225),
lastname VARCHAR(225),
photo BYTEA,
phone VARCHAR(14),
address VARCHAR(225),
country INT,
CONSTRAINT fk_country
FOREIGN KEY(country)
REFERENCES test.country(id)
);
CREATETABLE test.patient (
idINTGENERATEDBYDEFAULTASIDENTITY PRIMARY KEY,
nameVARCHAR(225),
lastname VARCHAR(225),
photo BYTEA,
phone VARCHAR(14),
address VARCHAR(225),
city INT,
CONSTRAINT fk_city
FOREIGN KEY(city)
REFERENCES test.city(id)
);
INSERTINTO test.country VALUES (1,'Spain'), (2,'France'), (3,'Portugal'), (4,'Germany');
INSERTINTO test.city VALUES (1,'Madrid',1), (2,'Valencia',1), (3,'Paris',2), (4,'Bordeaux',2), (5,'Lisbon',3), (6,'Porto',3), (7,'Berlin',4), (8,'Frankfurt',4);
Nous allons créer 3 tables pour nos tests: patient, ville et pqys, ces deux dernières vont avoir des données préchargées de villes et de pays.
Parfait, maintenant nous allons étudier comment établir les connexions avec la base de données.
Pour ce faire, nous avons créé notre projet Java à partir d'un projet Spring Boot préconfiguré disponible dans Visual Studio Code qui nous fournit la structure de base.
.png)
Ne vous inquiétez pas si vous ne comprenez pas immédiatement la structure du projet, le but n'est pas d'apprendre Java, mais nous allons tout de même expliquer un peu plus en détail les documents principaux.
MyDataSourceFactory.java
Cette classe Java permet d'ouvrir les connexions aux différentes bases de données.
PerformancerController.java
Contrôleur chargé de publier les endpoints que nous appellerons depuis Postman.
application.properties
Fichier de configuration avec les différentes connexions aux bases de données déployées dans notre Docker.
.png)
Comme vous pouvez le constater, les URL de connexion utilisent le nom du conteneur puisque, lorsqu'elles sont déployées dans un conteneur Tomcat, les bases de données ne seront accessibles par notre application Java qu'avec le nom du conteneur correspondant. Nous pouvons également vérifier la manière dont l'URL établit une connexion via JDBC à nos bases de données. Les bibliothèques Java utilisées dans le projet sont définies dans le fichier pom.xml.
Si vous modifiez le code source, il vous suffit d'exécuter la commande suivante :
mvn package
Cela va générer un fichier performance-0.0.1-SNAPSHOT.war, renommez-le en performance.war et déplacez-le dans le répertoire /tomcat, en remplaçant le fichier existant.
Puisque le projet est sur GitHub, il suffit de le cloner sur notre ordinateur depuis Visual Studio et d'exécuter les commandes suivantes dans le terminal:
docker-compose build
docker-compose up -d
Vérifions le portail Docker:
.png)
Génial! Les conteneurs Docker fonctionnent. Vérifions maintenant depuis notre Adminer et le portail de gestion IRIS que nos tables sont correctement créées.
.png) Accédons d'abord à la base de données MySQL. Si vous consultez le fichier docker-compose.yml vous verrez que le nom d'utilisateur et le mot de passe définis pour MySQL et PostgreSQL sont les mêmes: testuser/testpassword
Accédons d'abord à la base de données MySQL. Si vous consultez le fichier docker-compose.yml vous verrez que le nom d'utilisateur et le mot de passe définis pour MySQL et PostgreSQL sont les mêmes: testuser/testpassword
.png) Les trois tables se trouvent dans notre base de données Test, regardons notre base de données PostgreSQL:
Les trois tables se trouvent dans notre base de données Test, regardons notre base de données PostgreSQL:
.png)
Sélectionnons la base de données testuser et le schéma test:
.png)
Nous avons ici nos tables parfaitement créées dans PostgreSQL. Vérifions enfin si tout est bien configuré dans IRIS:
.png)
Tout est correct, nous avons créé nos tables dans l'espace de noms USER Namespace sous le schéma Test.
Très bien, une fois les vérifications effectuées, c'est parti ! Pour ce faire, nous utiliserons Postman, dans lequel nous chargerons le fichier attaché au projet: performance.postman_collection.json
.png)
Voici les différents tests que nous allons lancer, nous commencerons par des insertions et nous continuerons par des requêtes sur la base de données. Je n'ai inclus aucun type d'index autre que ceux qui sont créés automatiquement avec la définition des clés primaires dans les différentes bases de données.
Insertion
Appel REST: GET http://localhost:8080/performance/tests/insert/{database}?total=1000
La variable {database} peut avoir les valeurs suivantes:
Et l'attribut total sera celui que nous modifierons pour indiquer le nombre total d'insertions que nous voulons faire.
La méthode qui sera invoquée s'appelle insertRecords et se trouve dans le fichier PerformanceController.java situé dans /src/main/java/com/performance/controller/, vous pouvez voir qu'il s'agit d'une insertion extrêmement simple:
INSERTINTO test.patient VALUES (null, ?, ?, null, ?, ?, ?)
La première valeur est nulle car il s'agit de la clé primaire autogénérée et la deuxième valeur nulle correspond à un champ de type BLOB/BYTEA/LONGVARBINARY dans lequel nous enregistrerons une photo ultérieurement.
Nous allons lancer les lots de commandes type push suivants : 100, 1000, 10000, 20000 et nous allons vérifier les temps de réponse que nous recevons dans Postman. Pour chaque mesure, nous effectuerons 3 tests et nous calculerons la moyenne des 3 valeurs obtenues.
Représentons-le graphiquement.
.png)
Insertion avec un fichier binaire
Dans l'exemple précédent, nous avons fait des insertions simples, allons donc accélérer les choses en incluant dans notre insertion une image de 50 kB qui servira de photo pour nos patients.
Appel REST: GET http://localhost:8080/performance/tests/insertBlob/{database}?total=1000
La variable {database} peut avoir les valeurs suivantes:
Et l'attribut total sera celui que nous modifierons pour indiquer le nombre total d'insertions que nous voulons faire.
La méthode qui sera invoquée s'appelle insertBlobRecords et se trouve dans le fichier PerformanceController.java situé dans /src/main/java/com/performance/controller/, vous pouvez vérifier qu'il s'agit d'une insertion similaire à la précédente à l'exception du fait d'introduire le fichier dans l'insertion:
INSERTINTO test.patient (Name, Lastname, Photo, Phone, Address, City) VALUES (?, ?, ?, ?, ?, ?)
Modifions un peu le nombre d'insertions ci-dessus pour éviter que le test ne prenne une éternité, puis nettoyons le Docker des images pour recommencer à zéro avec une égalité totale des chances.
Examinons le graphe:
.png)
Selection
Testons les performances avec une simple requête qui récupère tous les enregistrements de la table Patient.
Appel REST: GET http://localhost:8080/performance/tests/select/{database}
La variable {database} peut avoir les valeurs suivantes:
La méthode qui sera invoquée s'appelle selectRecords et se trouve dans le fichier PerformanceController.java situé dans /src/main/java/com/performance/controller/, la requête est extrêmement simple:
SELECT * FROM test.patient
Nous allons tester la requête avec le même ensemble d'éléments que nous avons utilisé pour notre premier test d'insertion.
Et graphiquement:
.png)
Sélection d'un groupe par
Testons les performances avec une requête incluant une jointure gauche ainsi que des fonctions d'agrégation.
Appel REST: GET http://localhost:8080/performance/tests/selectGroupBy/{database}
La variable {database} peut avoir les valeurs suivantes:
La méthode qui sera invoquée s'appelle selectGroupBy et se trouve dans le fichier PerformanceController.java situé dans /src/main/java/com/performance/controller/, examinons donc la requête:
SELECTcount(p.Name), c.Name FROM test.patient p leftjoin test.city c on p.City = c.Id GROUPBY c.Name
Nous allons tester la requête encore une fois avec le même ensemble d'éléments que nous avons utilisé pour notre premier test d'insertion.
Et graphiquement:
.png)
Mise à jour
Pour la mise à jour, nous allons lancer une requête associée à une sous-requête dans le cadre de ses conditions.
Appel REST: GET http://localhost:8080/performance/tests/update/{database}
La variable {database} peut avoir les valeurs suivantes:
La méthode qui sera invoquée s'appelle UpdateRecords et se trouve dans le fichier PerformanceController.java situé dans /src/main/java/com/performance/controller/, examinons donc la requête:
UPDATE test.patient SET Phone = '+15553535301'WHERENamein (SELECTNameFROM test.patient whereNamelike'%12')
Lançons la requête et examinons les résultats.
Nous constatons que MySQL ne permet pas ce type de sous-requêtes dans la même table que celle que nous allons mettre à jour, de sorte que nous ne pouvons pas mesurer leurs durées dans des conditions égales. Ici, nous n'utiliserons pas le graphe, car il est très simple.
Suppression
Pour la suppression, nous allons lancer une requête associée à une sous-requête dans le cadre de ses conditions.
Appel REST: GET http://localhost:8080/performance/tests/delete/{database}
The variable {database} may have the following values:
La méthode qui sera invoquée s'appelle DeleteRecords et se trouve dans le fichier PerformanceController.java situé dans /src/main/java/com/performance/controller/, examinons donc la requête:
DELETE test.patient WHERENamein (SELECTNameFROM test.patient whereNamelike'%12')
Lançons la requête et examinons les résultats.
Nous constatons encore une fois que MySQL ne permet pas ce type de sous-requêtes dans la même table que nous allons supprimer, de sorte que nous ne pouvons pas mesurer leurs durées dans des conditions égales.
Conclusions
Nous pouvons affirmer qu'ils sont tous très au point en ce qui concerne les requêtes de données, ainsi que la mise à jour et la suppression d'enregistrements (à l'exception de MySQL). La plus grande différence se trouve dans la gestion des insertions. IRIS est en effet le meilleur parmi les trois, étant 6 fois plus rapide que PostgreSQL et jusqu'à 20 fois plus rapide que MySQL lors de l'ingestion de données.
Pour travailler avec de grands ensembles de données, c'est IRIS qui est sans aucun doute la meilleure option dans les tests effectués.
Alors... nous avons déjà un champion! IRIS A GAGNÉ!
PS: Il ne s'agit que de quelques exemples de tests que vous pouvez effectuer, n'hésitez pas à modifier le code comme vous le souhaitez.










.png)