Bonjour à tous et a toutes,
Nous sommes heureux d'annoncer le nouveau concours de programmation en ligne InterSystems :
🏆 Concours InterSystems sur .Net, Java, Python et JavaScript 🏆
Durée : du 22 septembre au 12 octobre 2025
Prix : 12 000 $
(3).jpg)
Java est un langage de programmation informatique polyvalent, concurrent, basé sur des classes, orienté objet et spécifiquement conçu pour avoir le moins de dépendances d'implémentation possible.
Bonjour à tous et a toutes,
Nous sommes heureux d'annoncer le nouveau concours de programmation en ligne InterSystems :
🏆 Concours InterSystems sur .Net, Java, Python et JavaScript 🏆
Durée : du 22 septembre au 12 octobre 2025
Prix : 12 000 $
Si vous aimez Java et que vous avez un écosystème Java florissant au travail dans lequel vous devez incorporer IRIS, ce n'est pas un problème. La passerelle Java External Language Gateway le fera de manière transparente, ou presque. Cette passerelle sert de pont entre Java et Object Script dans IRIS. Vous pouvez créer des objets de classes Java dans IRIS et appeler leurs méthodes. Pour ce faire, il vous suffit de disposer d'un fichier jar.
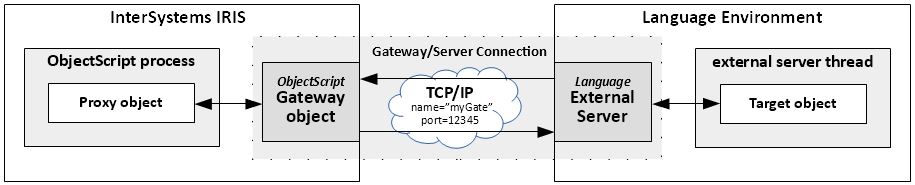
L'accès à un stockage cloud Azure pour charger/télécharger des blobs est assez simple à l'aide des méthodes API de classe %Net.Cloud.Storage.Client désignées ou des adaptateurs entrants/sortants EnsLib.CloudStorage.*.
Notez que vous devez avoir le serveur de %JavaServer External Language opérationnel pour utiliser l'API ou les adaptateurs de stockage cloud, car ils utilisent tous deux le framework PEX à l'aide du serveur Java.
Voici un bref résumé :
L'accès à Azure Blob Storage s'effectue à l'aide d'une chaîne de connexion qui ressemble à celle-ci :

La mise en œuvre de Databricks en SQL d'InterSystems Cloud se compose de quatre parties.
Naviguez vers la page d'aperçu de votre déploiement, si vous n'avez pas activé de connexions externes, faites-le et téléchargez votre certificat et le pilote jdbc depuis la page d'aperçu.
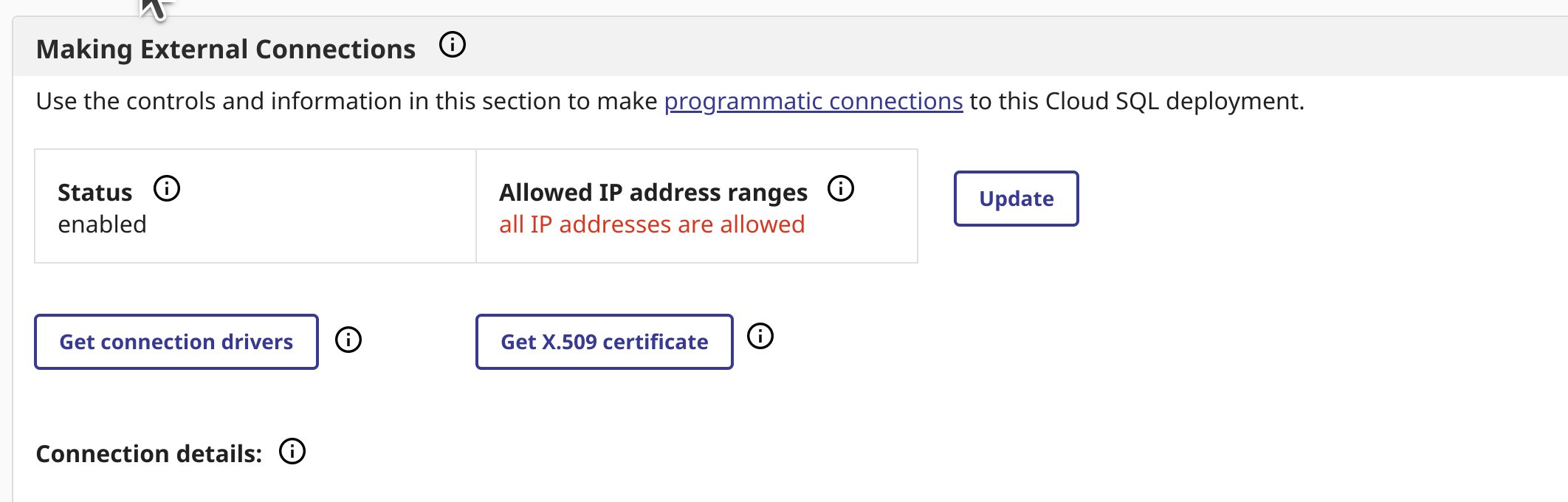
J'ai utilisé intersystems-jdbc-3.8.4.jar et intersystems-jdbc-3.7.1.jar avec succès dans Databricks à partir de la distribution de pilotes Driver Distribution.
La façon la plus simple d'importer un ou plusieurs certificats CA personnalisés dans votre cluster Databricks est de créer un script d'initialisation qui ajoute la chaîne complète de certificats CA aux magasins de certificats par défaut SSL et Java de Linux, et définit la propriété REQUESTS_CA_BUNDLE. Collez le contenu du certificat X.509 que vous avez téléchargé dans le bloc supérieur du script suivant:
import_cloudsql_certficiate.sh
#!/bin/bash
cat << 'EOF' > /usr/local/share/ca-certificates/cloudsql.crt
-----BEGIN CERTIFICATE-----
<PASTE>
-----END CERTIFICATE-----
EOF
update-ca-certificates
PEM_FILE="/etc/ssl/certs/cloudsql.pem"
PASSWORD="changeit"
JAVA_HOME=$(readlink -f /usr/bin/java | sed "s:bin/java::")
KEYSTORE="$JAVA_HOME/lib/security/cacerts"
CERTS=$(grep 'END CERTIFICATE'$PEM_FILE| wc -l)
# Pour traiter plusieurs certificats avec keytool, vous devez extraire# chacun d'eux du fichier PEM et l'importer dans le KeyStore Java.for N in $(seq 0 $(($CERTS - 1))); do
ALIAS="$(basename $PEM_FILE)-$N"echo"Adding to keystore with alias:$ALIAS"
cat $PEM_FILE |
awk "n==$N { print }; /END CERTIFICATE/ { n++ }" |
keytool -noprompt -import -trustcacerts
-alias$ALIAS -keystore $KEYSTORE -storepass $PASSWORDdoneecho"export REQUESTS_CA_BUNDLE=/etc/ssl/certs/ca-certificates.crt" >> /databricks/spark/conf/spark-env.sh
echo"export SSL_CERT_FILE=/etc/ssl/certs/ca-certificates.crt" >> /databricks/spark/conf/spark-env.sh
Maintenant vous avez le script initial, téléchargez-le dans le catalogue Unity sur un Volume.

Une fois que le script est sur un volume, vous pouvez ajouter le script initial au cluster à partir du volume dans les propriétés avancées de votre cluster.

Ensuite, ajoutez le pilote/la bibliothèque intersystems jdbc au cluster...

...et démarrez ou redémarrez votre calcul.

Créez un Notebook Python dans votre espace de travail, attachez-le à votre cluster et testez le glissement de données vers Databricks. Sous le capot, Databricks va utiliser pySpark, si cela n'est pas immédiatement évident.
La construction du Dataframe Spark suivant est tout ce qu'il vous faut, vous pouvez récupérer vos informations de connexion à partir de la page d'aperçu comme auparavant.

df = (spark.read
.format("jdbc")
.option("url", "jdbc:IRIS://k8s-05868f04-a4909631-ac5e3e28ef-6d9f5cd5b3f7f100.elb.us-east-1.amazonaws.com:443/USER")
.option("driver", "com.intersystems.jdbc.IRISDriver")
.option("dbtable", "(SELECT name,category,review_point FROM SQLUser.scotch_reviews) AS temp_table;")
.option("user", "SQLAdmin")
.option("password", "REDACTED")
.option("driver", "com.intersystems.jdbc.IRISDriver")\
.option("connection security level","10")\
.option("sslConnection","true")\
.load())
df.show()
Illustration de la production d'un dataframe à partir de données dans Cloud SQL... boom!


Prenons maintenant ce que nous avons lu dans IRIS et écrivons-le avec Databricks. Si vous vous souvenez bien, nous n'avons lu que 3 champs dans notre cadre de données, nous allons donc les réécrire immédiatement et spécifier un mode "écraser".
df = (spark.read
.format("jdbc")
.option("url", "jdbc:IRIS://k8s-05868f04-a4909631-ac5e3e28ef-6d9f5cd5b3f7f100.elb.us-east-1.amazonaws.com:443/USER")
.option("driver", "com.intersystems.jdbc.IRISDriver")
.option("dbtable", "(SELECT TOP 3 name,category,review_point FROM SQLUser.scotch_reviews) AS temp_table;")
.option("user", "SQLAdmin")
.option("password", "REDACTED")
.option("driver", "com.intersystems.jdbc.IRISDriver")\
.option("connection security level","10")\
.option("sslConnection","true")\
.load())
df.show()
mode = "overwrite"
properties = {
"user": "SQLAdmin",
"password": "REDACTED",
"driver": "com.intersystems.jdbc.IRISDriver",
"sslConnection": "true",
"connection security level": "10",
}
df.write.jdbc(url="jdbc:IRIS://k8s-05868f04-a4909631-ac5e3e28ef-6d9f5cd5b3f7f100.elb.us-east-1.amazonaws.com:443/USER", table="databricks_scotch_reviews", mode=mode, properties=properties)
Exécution du Notebook
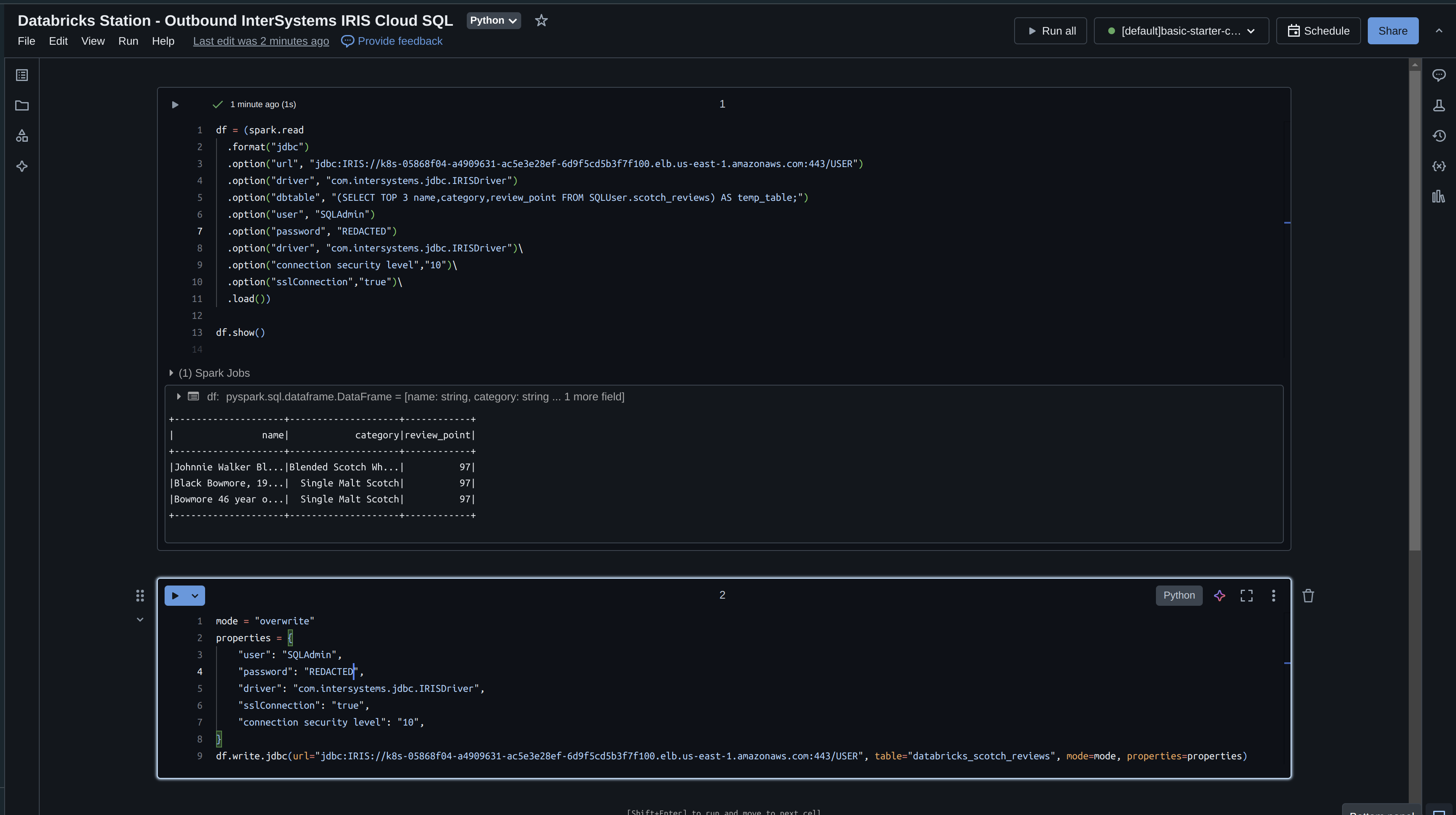
Illustration des données dans le Cloud SQL d'InterSystems!

En tant qu'ancien développeur de JAVA, j'ai toujours eu du mal à décider quelle base de données était la plus appropriée pour le projet à développer. L'un des principaux critères que j'utilisais était la performance, ainsi que les capacités de configuration de HA (haute disponibilité). Eh bien, il est maintenant temps de mettre IRIS à l'épreuve en ce qui concerne certaines bases de données les plus couramment utilisées, j'ai donc décidé de créer un petit projet Java basé sur SpringBoot qui se connecte via JDBC avec une base de données MySQL, avec une autre base de données PostgreSQL et enfin avec une base de données IRIS.
Nous allons profiter du fait de disposer d'images Docker de ces bases de données pour les utiliser dans notre projet et vous permettre de l'essayer vous-même sans avoir à procéder à une quelconque installation. Nous pouvons vérifier la configuration du docker dans notre fichier docker-compose.yml
version:"2.2"services:# mysql mysql: build: context:mysql container_name:mysql restart:always command:--default-authentication-plugin=mysql_native_password environment: MYSQL_ROOT_PASSWORD:SYS MYSQL_USER:testuser MYSQL_PASSWORD:testpassword MYSQL_DATABASE:test volumes: -./mysql/sql/dump.sql:/docker-entrypoint-initdb.d/dump.sql ports: -3306:3306# postgres postgres: build: context:postgres container_name:postgres restart:always environment: POSTGRES_USER:testuser POSTGRES_PASSWORD:testpassword volumes: -./postgres/sql/dump.sql:/docker-entrypoint-initdb.d/dump.sql ports: -5432:5432 adminer: container_name:adminer image:adminer restart:always depends_on: -mysql -postgres ports: -8081:8080# iris iris: init:true container_name:iris build: context:. dockerfile:iris/Dockerfile ports: -52773:52773 -1972:1972 command:--check-capsfalse# tomcat tomcat: init:true container_name:tomcat build: context:. dockerfile:tomcat/Dockerfile volumes: -./tomcat/performance.war:/usr/local/tomcat/webapps/performance.war ports: -8080:8080D'un coup d'œil rapide, nous constatons que nous utilisons les images suivantes :
Comme vous pouvez le voir, nous avons configuré les ports de listening de manière à ce qu'ils soient également mappés sur notre ordinateur, et pas seulement au sein de Docker. Pour les bases de données, ce n'est pas nécessaire, car la connexion se fait dans les conteneurs Docker, donc si vous avez des problèmes avec les ports, vous pouvez supprimer la ligne de prots de votre fichier docker-compose.yml.
Chaque image de base de données exécute un pré-script qui créera les tables nécessaires aux tests de performance. Examinons l'un des fichiers dump.sql
CREATESCHEMAtest;
DROPTABLEIFEXISTS test.patient;
CREATETABLE test.country (
idINT PRIMARY KEY,
nameVARCHAR(225)
);
CREATETABLE test.city (
idINT PRIMARY KEY,
nameVARCHAR(225),
lastname VARCHAR(225),
photo BYTEA,
phone VARCHAR(14),
address VARCHAR(225),
country INT,
CONSTRAINT fk_country
FOREIGN KEY(country)
REFERENCES test.country(id)
);
CREATETABLE test.patient (
idINTGENERATEDBYDEFAULTASIDENTITY PRIMARY KEY,
nameVARCHAR(225),
lastname VARCHAR(225),
photo BYTEA,
phone VARCHAR(14),
address VARCHAR(225),
city INT,
CONSTRAINT fk_city
FOREIGN KEY(city)
REFERENCES test.city(id)
);
INSERTINTO test.country VALUES (1,'Spain'), (2,'France'), (3,'Portugal'), (4,'Germany');
INSERTINTO test.city VALUES (1,'Madrid',1), (2,'Valencia',1), (3,'Paris',2), (4,'Bordeaux',2), (5,'Lisbon',3), (6,'Porto',3), (7,'Berlin',4), (8,'Frankfurt',4);
Nous allons créer 3 tables pour nos tests: patient, ville et pqys, ces deux dernières vont avoir des données préchargées de villes et de pays.
Parfait, maintenant nous allons étudier comment établir les connexions avec la base de données.
Pour ce faire, nous avons créé notre projet Java à partir d'un projet Spring Boot préconfiguré disponible dans Visual Studio Code qui nous fournit la structure de base.
.png)
Ne vous inquiétez pas si vous ne comprenez pas immédiatement la structure du projet, le but n'est pas d'apprendre Java, mais nous allons tout de même expliquer un peu plus en détail les documents principaux.
Cette classe Java permet d'ouvrir les connexions aux différentes bases de données.
Contrôleur chargé de publier les endpoints que nous appellerons depuis Postman.
Fichier de configuration avec les différentes connexions aux bases de données déployées dans notre Docker.
.png)
Comme vous pouvez le constater, les URL de connexion utilisent le nom du conteneur puisque, lorsqu'elles sont déployées dans un conteneur Tomcat, les bases de données ne seront accessibles par notre application Java qu'avec le nom du conteneur correspondant. Nous pouvons également vérifier la manière dont l'URL établit une connexion via JDBC à nos bases de données. Les bibliothèques Java utilisées dans le projet sont définies dans le fichier pom.xml.
Si vous modifiez le code source, il vous suffit d'exécuter la commande suivante :
mvn packageCela va générer un fichier performance-0.0.1-SNAPSHOT.war, renommez-le en performance.war et déplacez-le dans le répertoire /tomcat, en remplaçant le fichier existant.
Puisque le projet est sur GitHub, il suffit de le cloner sur notre ordinateur depuis Visual Studio et d'exécuter les commandes suivantes dans le terminal:
docker-compose build
docker-compose up -dVérifions le portail Docker:
.png)
Génial! Les conteneurs Docker fonctionnent. Vérifions maintenant depuis notre Adminer et le portail de gestion IRIS que nos tables sont correctement créées.
.png) Accédons d'abord à la base de données MySQL. Si vous consultez le fichier docker-compose.yml vous verrez que le nom d'utilisateur et le mot de passe définis pour MySQL et PostgreSQL sont les mêmes: testuser/testpassword
Accédons d'abord à la base de données MySQL. Si vous consultez le fichier docker-compose.yml vous verrez que le nom d'utilisateur et le mot de passe définis pour MySQL et PostgreSQL sont les mêmes: testuser/testpassword
.png) Les trois tables se trouvent dans notre base de données Test, regardons notre base de données PostgreSQL:
Les trois tables se trouvent dans notre base de données Test, regardons notre base de données PostgreSQL:
.png)
Sélectionnons la base de données testuser et le schéma test:
.png)
Nous avons ici nos tables parfaitement créées dans PostgreSQL. Vérifions enfin si tout est bien configuré dans IRIS:
.png)
Tout est correct, nous avons créé nos tables dans l'espace de noms USER Namespace sous le schéma Test.
Très bien, une fois les vérifications effectuées, c'est parti ! Pour ce faire, nous utiliserons Postman, dans lequel nous chargerons le fichier attaché au projet: performance.postman_collection.json
.png)
Voici les différents tests que nous allons lancer, nous commencerons par des insertions et nous continuerons par des requêtes sur la base de données. Je n'ai inclus aucun type d'index autre que ceux qui sont créés automatiquement avec la définition des clés primaires dans les différentes bases de données.
Appel REST: GET http://localhost:8080/performance/tests/insert/{database}?total=1000
La variable {database} peut avoir les valeurs suivantes:
Et l'attribut total sera celui que nous modifierons pour indiquer le nombre total d'insertions que nous voulons faire.
La méthode qui sera invoquée s'appelle insertRecords et se trouve dans le fichier PerformanceController.java situé dans /src/main/java/com/performance/controller/, vous pouvez voir qu'il s'agit d'une insertion extrêmement simple:
INSERTINTO test.patient VALUES (null, ?, ?, null, ?, ?, ?)La première valeur est nulle car il s'agit de la clé primaire autogénérée et la deuxième valeur nulle correspond à un champ de type BLOB/BYTEA/LONGVARBINARY dans lequel nous enregistrerons une photo ultérieurement.
Nous allons lancer les lots de commandes type push suivants : 100, 1000, 10000, 20000 et nous allons vérifier les temps de réponse que nous recevons dans Postman. Pour chaque mesure, nous effectuerons 3 tests et nous calculerons la moyenne des 3 valeurs obtenues.
| 100 | 1000 | 10000 | 20000 | |
| MySQL | 0.754 | 8.91 s | 88 s | 192 s |
| PostgreSQL | 0.23 s | 2.24 s | 20.92 s | 40.35 s |
| IRIS | 0.07 s | 0.33 s | 2.6 s | 5 s |
Représentons-le graphiquement.
.png)
Dans l'exemple précédent, nous avons fait des insertions simples, allons donc accélérer les choses en incluant dans notre insertion une image de 50 kB qui servira de photo pour nos patients.
Appel REST: GET http://localhost:8080/performance/tests/insertBlob/{database}?total=1000
La variable {database} peut avoir les valeurs suivantes:
Et l'attribut total sera celui que nous modifierons pour indiquer le nombre total d'insertions que nous voulons faire.
La méthode qui sera invoquée s'appelle insertBlobRecords et se trouve dans le fichier PerformanceController.java situé dans /src/main/java/com/performance/controller/, vous pouvez vérifier qu'il s'agit d'une insertion similaire à la précédente à l'exception du fait d'introduire le fichier dans l'insertion:
INSERTINTO test.patient (Name, Lastname, Photo, Phone, Address, City) VALUES (?, ?, ?, ?, ?, ?)Modifions un peu le nombre d'insertions ci-dessus pour éviter que le test ne prenne une éternité, puis nettoyons le Docker des images pour recommencer à zéro avec une égalité totale des chances.
| 100 | 1000 | 5000 | 10000 | |
| MySQL | 1.87 s | 17 s | 149 s | 234 s |
| PostgreSQL | 0.6 s | 5.22 s | 23.93 s | 60.43 s |
| IRIS | 0.13 s | 0.88 s | 4.58 s | 12.57 s |
Examinons le graphe:
.png)
Testons les performances avec une simple requête qui récupère tous les enregistrements de la table Patient.
Appel REST: GET http://localhost:8080/performance/tests/select/{database}
La variable {database} peut avoir les valeurs suivantes:
La méthode qui sera invoquée s'appelle selectRecords et se trouve dans le fichier PerformanceController.java situé dans /src/main/java/com/performance/controller/, la requête est extrêmement simple:
SELECT * FROM test.patientNous allons tester la requête avec le même ensemble d'éléments que nous avons utilisé pour notre premier test d'insertion.
| 100 | 1000 | 10000 | 20000 | |
| MySQL | 0.03 s | 0,02 s | 0.03 s | 0.04 s |
| PostgreSQL | 0.03 s | 0.02 s | 0.04 s | 0.03 s |
| IRIS | 0.02 s | 0.02 s | 0.04 s | 0.05 s |
Et graphiquement:
.png)
Testons les performances avec une requête incluant une jointure gauche ainsi que des fonctions d'agrégation.
Appel REST: GET http://localhost:8080/performance/tests/selectGroupBy/{database}
La variable {database} peut avoir les valeurs suivantes:
La méthode qui sera invoquée s'appelle selectGroupBy et se trouve dans le fichier PerformanceController.java situé dans /src/main/java/com/performance/controller/, examinons donc la requête:
SELECTcount(p.Name), c.Name FROM test.patient p leftjoin test.city c on p.City = c.Id GROUPBY c.NameNous allons tester la requête encore une fois avec le même ensemble d'éléments que nous avons utilisé pour notre premier test d'insertion.
| 100 | 1000 | 10000 | 20000 | |
| MySQL | 0.02 s | 0.02 s | 0.03 s | 0.03 s |
| PostgreSQL | 0.02 s | 0.02 s | 0.02 s | 0.02 s |
| IRIS | 0.02 s | 0.02 | 0.03 s | 0.04 s |
Et graphiquement:
.png)
Pour la mise à jour, nous allons lancer une requête associée à une sous-requête dans le cadre de ses conditions.
Appel REST: GET http://localhost:8080/performance/tests/update/{database}
La variable {database} peut avoir les valeurs suivantes:
La méthode qui sera invoquée s'appelle UpdateRecords et se trouve dans le fichier PerformanceController.java situé dans /src/main/java/com/performance/controller/, examinons donc la requête:
UPDATE test.patient SET Phone = '+15553535301'WHERENamein (SELECTNameFROM test.patient whereNamelike'%12')Lançons la requête et examinons les résultats.
| 100 | 1000 | 10000 | 20000 | |
| MySQL | X | X | X | X |
| PostgreSQL | 0.02 s | 0.02 s | 0.02 s | 0.03 s |
| IRIS | 0.02 s | 0.02 s | 0.02 s | 0.04 s |
Nous constatons que MySQL ne permet pas ce type de sous-requêtes dans la même table que celle que nous allons mettre à jour, de sorte que nous ne pouvons pas mesurer leurs durées dans des conditions égales. Ici, nous n'utiliserons pas le graphe, car il est très simple.
Pour la suppression, nous allons lancer une requête associée à une sous-requête dans le cadre de ses conditions.
Appel REST: GET http://localhost:8080/performance/tests/delete/{database}
The variable {database} may have the following values:
La méthode qui sera invoquée s'appelle DeleteRecords et se trouve dans le fichier PerformanceController.java situé dans /src/main/java/com/performance/controller/, examinons donc la requête:
DELETE test.patient WHERENamein (SELECTNameFROM test.patient whereNamelike'%12')Lançons la requête et examinons les résultats.
| 100 | 1000 | 10000 | 20000 | |
| MySQL | X | X | X | X |
| PostgreSQL | 0.01 s | 0.02 s | 0.02 s | 0.03 s |
| IRIS | 0.02 s | 0.02 s | 0.02 s | 0.04 s |
Nous constatons encore une fois que MySQL ne permet pas ce type de sous-requêtes dans la même table que nous allons supprimer, de sorte que nous ne pouvons pas mesurer leurs durées dans des conditions égales.
Nous pouvons affirmer qu'ils sont tous très au point en ce qui concerne les requêtes de données, ainsi que la mise à jour et la suppression d'enregistrements (à l'exception de MySQL). La plus grande différence se trouve dans la gestion des insertions. IRIS est en effet le meilleur parmi les trois, étant 6 fois plus rapide que PostgreSQL et jusqu'à 20 fois plus rapide que MySQL lors de l'ingestion de données.
Pour travailler avec de grands ensembles de données, c'est IRIS qui est sans aucun doute la meilleure option dans les tests effectués.
Alors... nous avons déjà un champion! IRIS A GAGNÉ!
PS: Il ne s'agit que de quelques exemples de tests que vous pouvez effectuer, n'hésitez pas à modifier le code comme vous le souhaitez.
Cet article vise à explorer le fonctionnement du système FHIR-PEX et a été développé, en tirant parti des capacités d'InterSystems IRIS.
En rationalisant l'identification et le traitement des examens médicaux dans les centres de diagnostic clinique, notre système vise à améliorer l'efficacité et la précision des flux de travail de soins de santé. En intégrant les normes FHIR à la base de données InterSystems IRIS Java-PEX, le système aide les professionnels de santé avec des capacités de validation et de routage, contribuant ainsi à améliorer la prise de décision et les soins aux patients.
Interopérabilité IRIS : Reçoit les messages au standard FHIR, garantissant l'intégration et la compatibilité avec les données de santé.
Traitement de l'information avec 'PEX Java' : Traite les messages au format FHIR et les dirige vers des sujets Kafka en fonction de règles configurées globalement dans la base de données, facilitant ainsi le traitement et le routage efficaces des données, en particulier pour les examens dirigés vers la quarantaine.
Gestion des retours Kafka via un backend Java externe : Interprète uniquement les examens dirigés vers la quarantaine, permettant au système de gérer les retours de Kafka via un backend Java externe. Il facilite la génération d'informations pronostiques pour les professionnels de la santé grâce à l'IA générative, en s'appuyant sur les consultations des résultats d'examens précédents pour les patients respectifs.
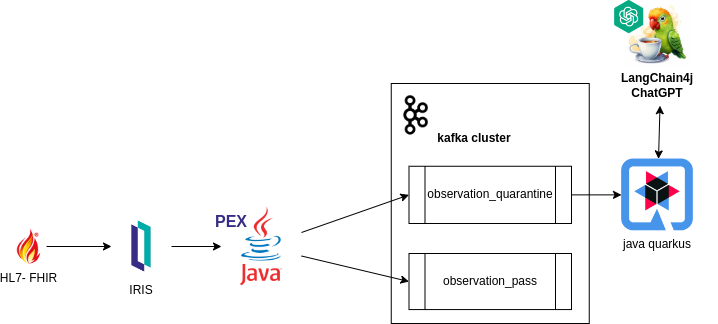
Grâce au PEX (Production EXtension) d'InterSystems, un outil d'extensibilité permettant d'améliorer et de personnaliser le comportement du système, nous avons élaboré une Opération Métier. Ce composant est chargé de traiter les messages entrants au format FHIR au sein du système. Comme exemple suivant :
import com.intersystems.enslib.pex.*;
import com.intersystems.jdbc.IRISObject;
import com.intersystems.jdbc.IRIS;
import com.intersystems.jdbc.IRISList;
import com.intersystems.gateway.GatewayContext;
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.serialization.*;
import com.fasterxml.jackson.databind.JsonNode;
import com.fasterxml.jackson.databind.ObjectMapper;
import java.io.FileInputStream;
import java.io.IOException;
import java.util.Properties;
public class KafkaOperation extends BusinessOperation {
// Connection to InterSystems IRIS
private IRIS iris;
// Connection to Kafka
private Producer<Long, String> producer;
// Kafka server address (comma separated if several)
public String SERVERS;
// Name of our Producer
public String CLIENTID;
/// Path to Config File
public String CONFIG;
public void OnInit() throws Exception {
[...]
}
public void OnTearDown() throws Exception {
[...]
}
public Object OnMessage(Object request) throws Exception {
IRISObject req = (IRISObject) request;
LOGINFO("Received object: " + req.invokeString("%ClassName", 1));
// Create record
String value = req.getString("Text");
String topic = getTopicPush(req);
final ProducerRecord<Long, String> record = new ProducerRecord<>(topic, value);
// Send new record
RecordMetadata metadata = producer.send(record).get();
// Return record info
IRISObject response = (IRISObject)(iris.classMethodObject("Ens.StringContainer","%New",topic+"|"+metadata.offset()));
return response;
}
private Producer<Long, String> createProducer() throws IOException {
[...]
}
private String getTopicPush(IRISObject req) {
[...]
}
[...]
}
`
Au sein de l'application, la méthode getTopicPush se charge d'identifier le sujet auquel le message sera envoyé.
La détermination du sujet auquel le message sera envoyé dépend de l'existence d'une règle dans la globale "quarantineRule", telle que lue dans IRIS.
String code = FHIRcoding.path("code").asText();
String system = FHIRcoding.path("system").asText();
IRISList quarantineRule = iris.getIRISList("quarantineRule",code,system);
String reference = quarantineRule.getString(1);
String value = quarantineRule.getString(2);
String observationValue = fhir.path("valueQuantity").path("value").asText()
When the global ^quarantineRule exists, validation of the FHIR object can be validated.
private boolean quarantineValueQuantity(String reference, String value, String observationValue) {
LOGINFO("quarantine rule reference/value: " + reference + "/" + value);
double numericValue = Double.parseDouble(value);
double numericObservationValue = Double.parseDouble(observationValue);
if ("<".equals(reference)) {
return numericObservationValue < numericValue;
}
else if (">".equals(reference)) {
return numericObservationValue > numericValue;
}
else if ("<=".equals(reference)) {
return numericObservationValue <= numericValue;
}
else if (">=".equals(reference)) {
return numericObservationValue >= numericValue;
}
return false;
}
Exemple pratique :
Lors de la définition d'une globale, telle que :
Set ^quarantineRule("59462-2","http://loinc.org") = $LB(">","500")
Ceci établit une règle pour le code "59462-2" et le système ""http://loinc.org"" dans la globale ^quarantineRule , spécifiant une condition dans laquelle la valeur supérieure à 500 est définie comme quarantaine. Dans l'application, la méthode getTopicPush peut ensuite utiliser cette règle pour déterminer le sujet approprié pour envoyer le message en fonction du résultat de la validation.
Compte tenu de l'affectation, le JSON ci-dessous serait envoyé en quarantaine car il correspond à la condition spécifiée en ayant :
{
"system": "http://loinc.org",
"code": "59462-2",
"display": "Testosterone"
}
"valueQuantity": { "value": 550, "unit": "ng/dL", "system": "http://unitsofmeasure.org", "code": "ng/dL" }
FHIR Observation:
{
"resourceType": "Observation",
"id": "3a8c7d54-1a2b-4c8f-b54a-3d2a7efc98c9",
"status": "final",
"category": [
{
"coding": [
{
"system": "http://terminology.hl7.org/CodeSystem/observation-category",
"code": "laboratory",
"display": "laboratory"
}
]
}
],
"code": {
"coding": [
{
"system": "http://loinc.org",
"code": "59462-2",
"display": "Testosterone"
}
],
"text": "Testosterone"
},
"subject": {
"reference": "urn:uuid:274f5452-2a39-44c4-a7cb-f36de467762e"
},
"encounter": {
"reference": "urn:uuid:100b4a8f-5c14-4192-a78f-7276abdc4bc3"
},
"effectiveDateTime": "2022-05-15T08:45:00+00:00",
"issued": "2022-05-15T08:45:00.123+00:00",
"valueQuantity": {
"value": 550,
"unit": "ng/dL",
"system": "http://unitsofmeasure.org",
"code": "ng/dL"
}
}
Après envoi sur le sujet souhaité, une application Quarkus Java a été construite pour recevoir les examens en quarantaine. @ApplicationScoped public class QuarentineObservationEventListener {
@Inject
PatientService patientService;
@Inject
EventBus eventBus;
@Transactional
@Incoming("observation_quarantine")
public CompletionStage<Void> onIncomingMessage(Message<QuarentineObservation> quarentineObservationMessage) {
var quarentineObservation = quarentineObservationMessage.getPayload();
var patientId = quarentineObservation.getSubject()
.getReference();
var patient = patientService.addObservation(patientId, quarentineObservation);
publishSockJsEvent(patient.getId(), quarentineObservation.getCode()
.getText());
return quarentineObservationMessage.ack();
}
private void publishSockJsEvent(Long patientId, String text) {
eventBus.publish("monitor", MonitorEventDto.builder()
.id(patientId)
.message(" is on quarentine list by observation ." + text)
.build());
}
}
Ce segment du système est chargé de conserver les informations reçues de Kafka, de les stocker dans les observations du patient dans la base de données et de notifier l'événement au moniteur.
Enfin, le moniteur du système est chargé de fournir une visualisation frontale simple. Cela permet aux professionnels de la santé d’examiner les données des patients/examens et de prendre les mesures nécessaires.
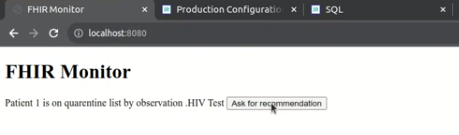
Grâce au moniteur, le système permet aux professionnels de la santé de demander des recommandations à l'IA générative.
@Unremovable
@Slf4j
@ApplicationScoped
public class PatientRepository {
@Tool("Get anamnesis information for a given patient id")
public Patient getAnamenisis(Long patientId) {
log.info("getAnamenisis called with id " + patientId);
Patient patient = Patient.findById(patientId);
return patient;
}
@Tool("Get the last clinical results for a given patient id")
public List<Observation> getObservations(Long patientId) {
log.info("getObservations called with id " + patientId);
Patient patient = Patient.findById(patientId);
return patient.getObservationList();
}
}
suivre la mise en œuvre de Langchain4j
@RegisterAiService(chatMemoryProviderSupplier = RegisterAiService.BeanChatMemoryProviderSupplier.class, tools = {PatientRepository.class})
public interface PatientAI {
@SystemMessage("""
You are a health care assistant AI. You have to recommend exams for patients based on history information.
""")
@UserMessage("""
Your task is to recommend clinical exams for the patient id {patientId}.
To complete this task, perform the following actions:
1 - Retrieve anamnesis information for patient id {patientId}.
2 - Retrieve the last clinical results for patient id {patientId}, using the property 'name' as the name of exam and 'value' as the value.
3 - Analyse results against well known conditions of health care.
Answer with a **single** JSON document containing:
- the patient id in the 'patientId' key
- the patient weight in the 'weight' key
- the exam recommendation list in the 'recommendations' key, with properties exam, reason and condition.
- the 'explanation' key containing an explanation of your answer, especially about well known diseases.
Your response must be just the raw JSON document, without ```json, ``` or anything else.
""")
String recommendExams(Long patientId);
}
Le système peut ainsi aider les professionnels de santé à prendre des décisions et à mener des actions.
NOTE:
L'application https://openexchange.intersystems.com/package/fhir-pex participe actuellement au concours InterSystems Java 2023. N'hésitez pas à explorer davantage la solution et n'hésitez pas à nous contacter si vous avez des questions ou avez besoin d'informations supplémentaires. Nous vous recommandons d'exécuter l'application dans votre environnement local pour une expérience pratique. Merci pour l'opportunité 😀!
Salut la Communauté!
Profitez de regarder la nouvelle vidéo sur le moyen de se connecter aux InterSystems Cloud Services à partir de votre application Java à l'aide du pilote JDBC InterSystems.
À l’ère du numérique en évolution rapide, une communication efficace est cruciale. Cet article présente un projet de chat basé sur Java, combinant la force de la base de données IRIS et l'intelligence artificielle de ChatGPT. Construit sur Java, il va au-delà de la messagerie en temps réel, en tirant parti d'IRIS et de ChatGPT pour une expérience de chat améliorée. De plus, le nom du projet fait référence au classique culturel – Star Wars.
Si vous appréciez mon application, n'oubliez pas de la soutenir lors du concours.
GmOwl est une solution qui offre une plateforme d'apprentissage organisée et engageante. Il a été développé pour répondre au besoin croissant d'outils d'apprentissage offrant un environnement de quiz polyvalent qui répond aux exigences des utilisateurs.
L'objectif principal de GmOwl est d'offrir une expérience utilisateur aux personnes participant à des quiz tout en donnant aux administrateurs un contrôle complet sur le contenu et l'engagement des utilisateurs.
Si vous appréciez mon application, n'oubliez pas de la soutenir lors du concours.
Salut les développeurs,
Nous sommes très heureux de vous inviter tous au nouveau concours de programmation en ligne InterSystems sur Java et ses dérivés !
🏆 Concours de programmation d'InterSystems sur Java 🏆
La durée : 13 novembre - 3 décembre, 2023
Le prix : $14,000
.jpg)
Hibernate est le framework le plus populaire pour réaliser des projets ORM (Mapping Objet-Relationnel). Avec Hibernate, un logiciel peut utiliser les principaux SGBD du marché, et même changer de fournisseur de base de données à tout moment, sans impact sur le code source. Cela est possible car Hibernate prend en charge les dialectes. Chaque produit de base de données a un dialecte différent qui peut être assigné dans un fichier de configuration. Ainsi, si un logiciel utilise Oracle et souhaite évoluer vers InterSystems IRIS, il suffit de modifier le fichier de configuration avec les informations relatives à la connexion et au dialecte. Si votre logiciel nécessite une préparation à l'utilisation de la base de données indiquée par votre client, Hibernate est la solution qu'il vous faut.
Actuellement, il n'existe pas de dialecte officiel pour utiliser IRIS avec le nouveau Hibernate 6. Pour résoudre ce problème, Dmitry Maslennikov a proposé une idée dans l'excellent portail d'idées (https://ideas.intersystems.com/ideas/DPI-I-372) et je l'ai mise en œuvre.
Si vous suivez ce tutoriel, vous verrez l'idée et ce nouveau dialecte d'IRIS en action et en fonctionnement.
Pour réaliser ce tutoriel, vous avez besoin de :
1. Ouvrez Spring Tool Suite (STS) et choisissez un chemin d'accès valide à l'espace de travail (n'importe quel dossier) et cliquez sur Launch ("lancement") :
.png)
2. Cliquez sur le lien Créer un nouveau Projet Spring Starter :
.png)
3. Cet assistant créera un nouveau projet Spring. Remplissez les champs avec les valeurs suivantes :
• Service URL: https://start.spring.io
• Type : Maven (c'est un gestionnaire de paquets comme NPM, ZPM ou IPM)
• Emballage : Jar (type d'exécutable pour le projet compilé)
• Version de Java : 17 ou 20 (pour ce tutoriel, j'ai choisi la version 17)
• Langage : Java
• Groupe : com.tutorial (domaine du projet pour Maven)
• Artifact : iris-tutorial (nom du projet pour Maven)
• Version : 0.0.1-SNAPSHOT (version du projet pour Maven)
• Description : Tutoriel IRIS
• Paquet : com.tutorial.iris (paquet roott pour le projet)
.png)
4. Cliquez sur Next (Suivant). 5. Choisissez les dépendances suivantes pour votre projet :
.png)
6. Cliquez sur Finish (Terminer) pour créer votre projet.
7. Ouvrez votre fichier pom.xml et incluez 2 nouvelles dépendances (pour le dialecte IRIS et pour le pilote IRIS JDBC), ainsi qu'un dépôt (ce qui est nécessaire car le pilote IRIS JDBC d'InterSystems n'est pas publié dans un dépôt maven public).
<?xml version="1.0" encoding="UTF-8"?><projectxmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>3.1.1</version><relativePath /><!-- lookup parent from repository --></parent><groupId>com.tutorial</groupId><artifactId>tutorial-dialect</artifactId><version>0.0.1-SNAPSHOT</version><name>tutorial-dialect</name><description>Tutorial for IRIS Hibernate 6 Dialect</description><properties><java.version>17</java.version></properties><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-jpa</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-rest</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-hateoas</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.data</groupId><artifactId>spring-data-rest-hal-explorer</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-devtools</artifactId><scope>runtime</scope><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-configuration-processor</artifactId><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><dependency><groupId>io.github.yurimarx</groupId><artifactId>hibernateirisdialect</artifactId><version>1.0.0</version></dependency><dependency><groupId>com.intersystems</groupId><artifactId>intersystems-jdbc</artifactId><version>3.7.1</version></dependency></dependencies><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId></plugin></plugins></build><repositories><repository><id>InterSystems IRIS DC Git Repository</id><url>
https://github.com/intersystems-community/iris-driver-distribution/blob/main/JDBC/JDK18</url><snapshots><enabled>true</enabled><updatePolicy>always</updatePolicy></snapshots></repository></repositories></project>8. Allez dans le fichier application.properties (src > main > java > dossier resources) et définissez les propriétés connection et dialect avec ces valeurs :
spring.datasource.username=_SYSTEMspring.datasource.url=jdbc:IRIS://localhost:1972/USERspring.datasource.password=SYSspring.jpa.properties.hibernate.default_schema=Examplespring.jpa.hibernate.ddl-auto=updatespring.datasource.driver-class-name=com.intersystems.jdbc.IRISDriverspring.jpa.properties.hibernate.temp.use_jdbc_metadata_defaults=falsespring.jpa.database-platform=io.github.yurimarx.hibernateirisdialect.InterSystemsIRISDialectspring.jpa.show-sql=truespring.jpa.properties.hibernate.format_sql=true.png)
9. Créez une nouvelle classe persistante (cliquez sur le bouton droit de la souris sur le projet > Nouveau > Classe) :
.png)
10. Remplissez les champs suivants pour créer la classe :
• Paquet: com.tutorial.iris.model
• Nom: Product (Produit)
.png)
11. Cliquez sur Finish (Terminer) pour créer la classe. 12. Développez la classe persistante Produit (classe dont les valeurs sont conservées dans un tableau SQL) à l'aide de ce code source :
package com.tutorial.dialect.model;
import java.util.Date;
import com.fasterxml.jackson.annotation.JsonFormat;
import jakarta.persistence.Column;
import jakarta.persistence.Entity;
import jakarta.persistence.GeneratedValue;
import jakarta.persistence.GenerationType;
import jakarta.persistence.Id;
import jakarta.persistence.Table;
import jakarta.persistence.Temporal;
import jakarta.persistence.TemporalType;
@Entity@Table(name = "Product")
publicclassProduct{
@Id@GeneratedValue (strategy = GenerationType.IDENTITY)
private Long id;
private String name;
private String description;
private Double height;
private Double width;
private Double weight;
@Column(name="releasedate")
@Temporal(TemporalType.DATE)
@JsonFormat(pattern = "yyyy-MM-dd")
private Date releaseDate;
public Long getId(){
return id;
}
publicvoidsetId(Long id){
this.id = id;
}
public String getName(){
return name;
}
publicvoidsetName(String name){
this.name = name;
}
public String getDescription(){
return description;
}
publicvoidsetDescription(String description){
this.description = description;
}
public Double getHeight(){
return height;
}
publicvoidsetHeight(Double height){
this.height = height;
}
public Double getWidth(){
return width;
}
publicvoidsetWidth(Double width){
this.width = width;
}
public Double getWeight(){
return weight;
}
publicvoidsetWeight(Double weight){
this.weight = weight;
}
public Date getReleaseDate(){
return releaseDate;
}
publicvoidsetReleaseDate(Date releaseDate){
this.releaseDate = releaseDate;
}
}
13. Créez un référentiel d'interface pour les opérations CRUD sur la classe Produit (cliquez sur le bouton droit de la souris dans le projet > Nouveau > Interface) :
.png)
14. Saisissez les valeurs de l'interface et cliquez sur Finish (Terminer) :
• Paquet: com.tutorial.iris.repository
• Nom: ProductRepository
.png)
15. Cliquez sur Finish (Terminer) pour créer l'interface.
16. Développez l'interface ProductRepository (un référentiel CRUD implémentant les fonctions de sauvegarde, de suppression, de recherche, de recherche unique et de mise à jour) (src > main > java > com > tutoriel > dialecte > dossier référentiel) à l'aide de ce code source :
package com.tutorial.dialect.repository;
import org.springframework.data.repository.CrudRepository;
import org.springframework.stereotype.Repository;
import com.tutorial.dialect.model.Product;
@RepositorypublicinterfaceProductRepositoryextendsCrudRepository<Product, Long> {
}17. Maintenant, en utilisant le navigateur HAL de Springboot, vous pouvez tester les fonctions CRUD dans un écran web.
18. Assurez-vous d'exécuter une instance IRIS sur localhost, port 1972 avec l'utilisateur _SYSTEM et le mot de passe SYS (ou modifiez l'application.properties pour d'autres valeurs de connexion).
19. Exécutez l'application (cliquez avec le bouton droit de la souris sur le projet > Exécuter en tant que > Spring boot app).
20. Sur la console, vous verrez le journal indiquant le démarrage de l'application :
.png)
21. Allez dans votre navigateur et tapez http://localhost:8080. Découvrez le navigateur HAL :
.png)
22. Cliquez sur le bouton "plus" de produits endpoint pour créer un nouveau produit :
23. Remplissez les valeurs suivantes pour créer un nouveau produit et cliquez sur le bouton "Go" (aller) pour confirmer :
.png)
24. Un nouveau produit a été lancé :
.png)
.png)
Testez d'autres opérations, vérifiez la base de données et amusez-vous !
À titre d'exemple d'application en Java fonctionnant avec le dialecte Hibernate pour IRIS, je souhaitais utiliser l'application RealWorld et j'ai trouvé une réalisation pour Quarkus. L'application RealWorld est un exemple d'application proche d'une application réelle, avec des tests déjà préparés pour le backend. La plupart des exemples de réalisations sont à retrouver ici
![]()
L'exemple d'application RealWorld est souvent appelé « Wikipédia pour la création d'applications full-stack ». Il sert de prototype standardisé que les développeurs peuvent utiliser pour créer des applications à l'aide de divers langages et frameworks de programmation. L'application fournit un cas d'utilisation réel en imitant une plate-forme de blogs, avec des fonctionnalités telles que l'authentification des utilisateurs, la gestion des profils, la publication d'articles et les commentaires. Avec un ensemble complet de spécifications, y compris une documentation d'API backend prête à l'emploi et des conceptions frontend, il permet aux développeurs de voir comment les mêmes exigences fonctionnelles sont mises en œuvre dans différentes piles technologiques. L'exemple RealWorld est largement utilisé comme outil d'apprentissage et comme référence pour comparer diverses technologies.
Quarkus est un framework Java open source natif de Kubernetes, conçu pour GraalVM et HotSpot. Créé dans le but d'améliorer l'environnement cloud natif moderne, il réduit considérablement l'empreinte et le temps de démarrage des applications Java. Quarkus est connu pour sa philosophie « privilégiant le conteneur », permettant aux développeurs de créer des applications légères et performantes en mettant l'accent sur l'architecture des microservices. Cette flexibilité en a fait un choix populaire pour les organisations cherchant à passer à des plates-formes sans serveur ou basées sur le cloud, combinant des modèles de programmation impératifs et réactifs. Qu'il s'agisse d'une application Web traditionnelle ou d'un système complexe de microservices, Quarkus fournit une plate-forme robuste pour créer des logiciels évolutifs et maintenables.
Il existe encore des systèmes dans le secteur de la santé qui utilisent PB9, Delphi7 et d'autres langages. Pour accélérer le processus de développement et permettre aux applications tierces d'invoquer built-in le service web HL7 V2 intégré fourni par Ensemble ou IRIS, nous présentons ici plusieurs exemples d'invocations de l'interface SOAP HL7 V2 d'Ensemble en utilisant Java, PB9 et Delphi7.
Ceci est un client fhir simple en java pour s'exercer avec les ressources fhir et les requêtes CRUD vers un serveur fhir.
Notez que pour la majeure partie, l'autocomplétion est activée.
Assurez-vous que git et Docker desktop sont installé.
Déjà installé dans le conteneur :
Hapi Fhir modèle et client
Clone/git tire le repo dans n'importe quel répertoire local, par exemple comme indiqué ci-dessous :
git clone https://github.com/LucasEnard/fhir-client-java.git
Ouvrez le terminal dans ce répertoire et exécutez :
docker build .
Ce référentiel est prêt pour CodeVS.
Ouvrez le dossier fhir-client-java cloné localement dans VS Code.
Si vous y êtes invité (coin inférieur droit), installez les extensions recommandées.
Vous pouvez être à l'intérieur du conteneur avant de coder si vous le souhaitez.
Pour cela, il faut que docker soit activé avant d'ouvrir VSCode.
Ensuite, dans VSCode, lorsque vous y êtes invité ( coin inférieur droit ), rouvrez le dossier à l'intérieur du conteneur afin de pouvoir utiliser les composants python qu'il contient.
La première fois que vous effectuez cette opération, cela peut prendre plusieurs minutes, le temps que le conteneur soit préparé.
Si vous n'avez pas cette option, vous pouvez cliquer dans le coin inférieur gauche et cliquer sur Ouvrir à nouveau dans le conteneur puis sélectionner De Dockerfile

En ouvrant le dossier à distance, vous permettez à VS Code et à tous les terminaux que vous ouvrez dans ce dossier d'utiliser les composants java dans le conteneur.
Pour réaliser cette présentation, vous aurez besoin d'un serveur FHIR.
Vous pouvez soit utiliser le vôtre, soit vous rendre sur le site Essai FHIR gratuit d'InterSystems et suivre les étapes suivantes pour le configurer.
En utilisant notre essai gratuit, il suffit de créer un compte et de commencer un déploiement, puis dans l'onglet Overview vous aurez accès à un endpoint comme https://fhir.000000000.static-test-account.isccloud.io que nous utiliserons plus tard.
Ensuite, en allant dans l'onglet d'informations d'identification Credentials, créez une clé api et enregistrez-la quelque part.
C'est maintenant terminé, vous avez votre propre serveur fhir pouvant contenir jusqu'à 20 Go de données avec une mémoire de 8 Go.
La présentation pas à pas du client se trouve à src/java/test/Client.java.
Le code est divisé en plusieurs parties, et nous allons couvrir chacune d'entre elles ci-dessous.
Dans cette partie, nous connectons notre client à notre serveur en utilisant Fhir.Rest.
// Partie 1
// Créer un contexte en utilisant FHIR R4
FhirContext ctx = FhirContext.forR4();
// créer un en-tête contenant la clé api pour le httpClient
Header header = new BasicHeader("x-api-key", "api-key");
ArrayList<Header> headers = new ArrayList<Header>();
headers.add(header);
// créer un constructeur httpClient et lui ajouter l'en-tête
HttpClientBuilder builder = HttpClientBuilder.create();
builder.setDefaultHeaders(headers);
// créer un httpClient à l'aide du constructeur
CloseableHttpClient httpClient = builder.build();
// Configurer le httpClient au contexte en utilisant la fabrique
ctx.getRestfulClientFactory().setHttpClient(httpClient);
// Créer un client
IGenericClient client = ctx.newRestfulGenericClient("url");
Afin de vous connecter à votre serveur, vous devez modifier la ligne :
Header header = new BasicHeader("x-api-key", "api-key");
Et cette ligne aussi :
IGenericClient client = ctx.newRestfulGenericClient("url");
L'url' est un point de terminaison tandis que l'"api-key" est la clé d'api pour accéder à votre serveur.
Notez que si vous n'utilisez pas un serveur InterSystems, vous pouvez vérifier comment autoriser vos accès si nécessaire.
Comme ça, nous avons un client FHIR capable d'échanger directement avec notre serveur.
Dans cette partie, nous créons un Patient en utilisant Fhir.Model et nous le complétons avec un HumanName, en suivant la convention FHIR, use et family sont des chaînes et given est une liste de chaînes. De la même manière, un patient peut avoir plusieurs HumanNames, donc nous devons mettre notre HumanName dans une liste avant de le mettre dans notre patient nouvellement créé.
// Partie 2
// Créer un patient et lui ajouter un nom
Patient patient = new Patient();
patient.addName()
.setFamily("FamilyName")
.addGiven("GivenName1")
.addGiven("GivenName2");
// Voir aussi patient.setGender ou setBirthDateElement
// Créer le patient ressource sur le serveur
MethodOutcome outcome = client.create()
.resource(patient)
.execute();
// Enregistrez l'ID que le serveur a attribué
IIdType id = outcome.getId();
System.out.println("");
System.out.println("Created patient, got ID: " + id);
System.out.println("");
Après cela, nous devons sauvegarder notre nouveau Patient sur notre serveur en utilisant notre client.
Notez que si vous lancez Client.java plusieurs fois, plusieurs Patients ayant le nom que nous avons choisi seront créés.
C'est parce que, suivant la convention FHIR, vous pouvez avoir plusieurs Patients avec le même nom, seul l' id est unique sur le serveur.
Vérifier the doc pour avoir plus d'information.
Nous conseillons donc de commenter la ligne après le premier lancement.
Dans cette partie, nous avons un client qui recherche un patient nommé d'après celui que nous avons créé précédemment.
// Partie 3
// Rechercher un patient unique avec le nom de famille exact "NomDeFamille" et le prénom exact "Prénom1"
patient = (Patient) client.search()
.forResource(Patient.class)
.where(Patient.FAMILY.matchesExactly().value("FamilyName"))
.and(Patient.GIVEN.matchesExactly().value("GivenName1"))
.returnBundle(Bundle.class)
.execute()
.getEntryFirstRep()
.getResource();
// Créer une télécommunication pour le patient
patient.addTelecom()
.setSystem(ContactPointSystem.PHONE)
.setUse(ContactPointUse.HOME)
.setValue("555-555-5555");
// Changer le prénom du patient en un autre
patient.getName().get(0).getGiven().set(0, new StringType("AnotherGivenName"));
// Mettre à jour le patient de ressource sur le serveur
MethodOutcome outcome2 = client.update()
.resource(patient)
.execute();
Une fois que nous l'avons trouvé, nous ajoutons un numéro de téléphone à son profil et nous changeons son prénom en un autre.
Maintenant nous pouvons utiliser la fonction de mise à jour de notre client pour mettre à jour notre patient sur le serveur.
Dans cette section, nous voulons créer une observation pour notre patient. Pour ce faire, nous avons besoin de son identifiant, qui est son identifiant unique.
A partir de là, nous remplissons notre observation et ajoutons comme sujet, l'identifiant de notre Patient.
// Partie 4
// Créer un CodeableConcept et le remplir
CodeableConcept codeableConcept = new CodeableConcept();
codeableConcept.addCoding()
.setSystem("http://snomed.info/sct")
.setCode("1234")
.setDisplay("CodeableConceptDisplay");
// Créer une quantité et la remplir
Quantity quantity = new Quantity();
quantity.setValue(1.0);
quantity.setUnit("kg");
// Créer une catégorie et la remplir
CodeableConcept category = new CodeableConcept();
category.addCoding()
.setSystem("http://snomed.info/sct")
.setCode("1234")
.setDisplay("CategoryDisplay");
// Créer une liste de CodeableConcepts et y placer des catégories
ArrayList<CodeableConcept> codeableConcepts = new ArrayList<CodeableConcept>();
codeableConcepts.add(category);
// Créer une observation
Observation observation = new Observation();
observation.setStatus(Observation.ObservationStatus.FINAL);
observation.setCode(codeableConcept);
observation.setSubject(new Reference().setReference("Patient/" + ((IIdType) outcome2.getId()).getIdPart()));
observation.setCategory(codeableConcepts);
observation.setValue(quantity);
System.out.println("");
System.out.println("Created observation, reference : " + observation.getSubject().getReference());
System.out.println("");
// Créer l'observation de ressource sur le serveur
MethodOutcome outcome3 = client.create()
.resource(observation)
.execute();
// Imprimer la réponse du serveur
System.out.println("");
System.out.println("Created observation, got ID: " + outcome3.getId());
System.out.println("");
Ensuite, nous enregistrons notre observation à l'aide de la fonction de création.
Si vous avez suivi ce parcours, vous savez maintenant exactement ce que fait Client.java, vous pouvez le lancer et vérifier votre Patient et votre Observation nouvellement créés sur votre serveur.
Pour le lancer, ouvrez un terminal VSCode et entrez :
dotnet run
Vous devriez voir des informations sur le Patient créé et son observation.
Si vous utilisez un serveur Intersystems, allez à API Deployement, autorisez-vous avec la clé api et d'ici vous pouvez OBTENIR par id le patient et l'observation que nous venons de créer.
Ce référentiel est prêt à être codé dans VSCode avec les plugins InterSystems.
Ouvrez Client.java pour commencer à coder ou utiliser l'autocomplétion.
Un dockerfile pour créer un dot net env pour que vous puissiez travailler.
Utilisez docker build . pour construire et rouvrir votre fichier dans le conteneur pour travailler à l'intérieur de celui-ci.
Fichier de paramètres.
Fichier de configuration si vous voulez déboguer
Comme nous le savons tous, Caché est une excellente base de données qui accomplit de nombreuses tâches en son sein. Cependant, que faites-vous lorsque vous avez besoin d'accéder à une base de données externe ? Une façon de le faire est d'utiliser la passerelle Caché SQL Gateway via JDBC. Dans cet article, mon objectif est de répondre aux questions suivantes pour vous aider à vous familiariser avec cette technologie et à déboguer certains problèmes courants.
Avant de se plonger dans ces questions, discutons rapidement de l'architecture de la passerelle JDBC SQL Gateway. Pour simplifier, vous pouvez considérer que l'architecture est la suivante : Cache établit une connexion TCP avec un processus Java, appelé processus de passerelle. Le processus de passerelle se connecte ensuite à une base de données distante, telle que Caché, Oracle ou SQL Server, en utilisant le pilote spécifié pour cette base de données. Pour plus d'informations sur l'architecture de la passerelle SQL Gateway, veuillez consulter la documentation sur Utilisation de la passerelle Caché SQL Gateway.
Lorsque vous vous connectez à une base de données distante, vous devez fournir les paramètres suivants :
Par exemple, si vous avez besoin de vous connecter à une instance de Caché en utilisant la passerelle SQL Gateway via JDBC, vous devez naviguer vers [System Administration] -> [Configuration] -> [Connectivity] -> [SQL Gateway Connections] dans le portail de gestion du système (SMP). Cliquez ensuite sur "Créer une nouvelle connexion" et spécifiez "JDBC" comme type de connexion.
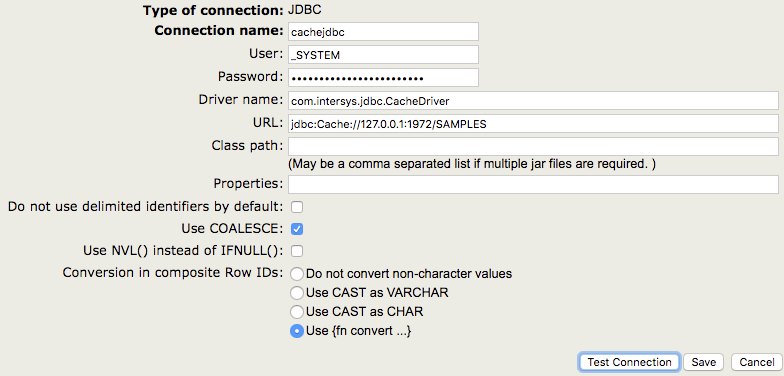
Lors de la connexion à un système Caché, le nom du pilote doit toujours être com.intersys.jdbc.CacheDriver, comme indiqué dans la capture d'écran. Si vous vous connectez à une base de données tierce, vous devrez utiliser un nom de pilote différent (voir Connexion à des bases de données tierces ci-dessous).
Lorsque vous vous connectez aux bases de données Caché, vous n'avez pas besoin de spécifier un chemin de classe car le fichier JAR est téléchargé automatiquement.
Le paramètre URL varie également en fonction de la base de données à laquelle vous vous connectez. Pour les bases de données Caché, vous devez utiliser une URL de la forme suivante
jdbc:Cache://[server_address]:[superserver_port]/[namespace]
Une base de données tierce courante est Oracle. Un exemple de configuration est présenté ci-dessous.
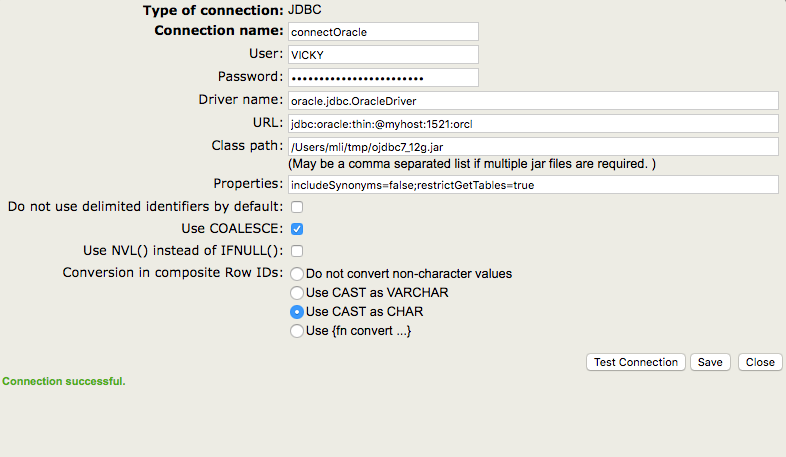
Comme vous pouvez le constater, le nom du pilote et l'URL ont des caractéristiques différentes de celles que nous avons utilisées pour la connexion précédente. En outre, j'ai spécifié un chemin de classe dans cet exemple, car je dois utiliser le pilote d'Oracle pour me connecter à leur base de données.
Comme vous pouvez l'imaginer, SQL Server utilise différents modèles d'URL et de noms de pilotes.
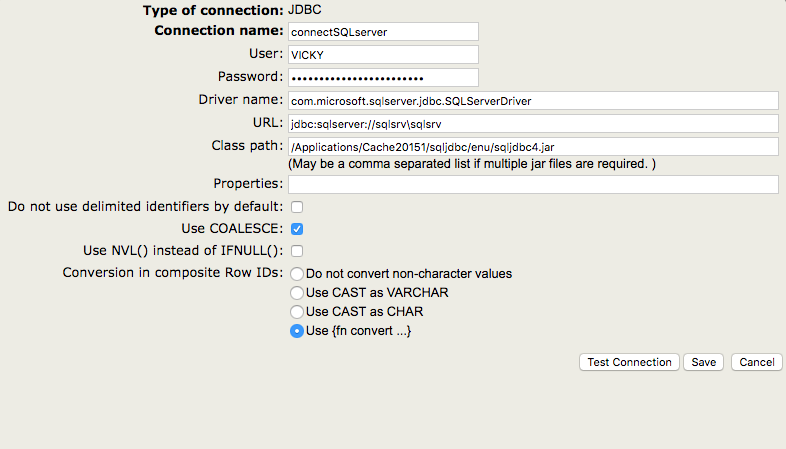
Vous pouvez tester si les valeurs sont valides en cliquant sur le bouton " Testez la connexion ". Pour créer la connexion, cliquez sur "Enregistrer".
Tout d'abord, la passerelle JDBC et le service de passerelle Java sont complètement indépendants l'un de l'autre. La passerelle JDBC peut être utilisée sur tous les systèmes basés sur Caché, alors que le service de passerelle Java n'existe que dans le cadre d'Ensemble. En outre, le service de passerelle Java utilise un processus différent de celui utilisé par la passerelle JDBC. Pour plus de détails sur le service commercial de passerelle Java, veuillez consulter Le service commercial de passerelle Java.
Vous trouverez ci-dessous 5 outils et méthodes couramment utilisés pour résoudre des problèmes avec la passerelle JDBC SQL Gateway. Je vais d'abord parler de ces outils et vous montrer quelques exemples de leur utilisation dans la section suivante.
Lorsque vous utilisez la passerelle JDBC, le journal correspondant est le journal de la passerelle JDBC SQL. Comme nous l'avons vu précédemment, la passerelle JDBC est utilisée lorsque Caché doit accéder à des bases de données externes, ce qui signifie que Caché est le client. Le journal du pilote, par contre, correspond à l'utilisation du pilote JDBC d'InterSystems pour accéder à une base de données Caché à partir d'une application externe, ce qui signifie que Caché est le serveur. Si vous avez une connexion d'une base de données Caché à une autre base de données Caché, les deux types de journaux peuvent être utiles.
Dans notre documentation la section relative à l'activation du journal du pilote est intitulée "Activation de la journalisation pour JDBC", et la section relative à l'activation du journal de la passerelle est intitulée "Activation de la journalisation pour la passerelle SQL JDBC".
Même si les deux journaux comportent le mot "JDBC", ils sont totalement indépendants. L'objet de cet article est la passerelle JDBC, c'est pourquoi j'aborderai plus en détail le journal de la passerelle. Pour plus d'informations sur le journal du pilote, veuillez vous reporter à la section Activation du journal du pilote.
Si vous utilisez la passerelle Caché JDBC SQL Gateway, vous devez effectuer les opérations suivantes pour activer la journalisation : dans le portail de gestion, allez dans [System Administration] > [Configuration] > [Connectivity] > [JDBC Gateway Settings]. Indiquez une valeur pour le journal de la passerelle JDBC. Ce doit être le chemin complet et le nom d'un fichier journal (par exemple, /tmp/jdbcGateway.log). Le fichier sera automatiquement créé s'il n'existe pas, mais le répertoire ne le sera pas. Caché va démarrer la passerelle JDBC SQL Gateway avec journalisation pour vous.
Si vous utilisez le service commercial Java Gateway dans Ensemble, veuillez consulter Activation de la journalisation de la passerelle Java Gateway dans Ensemble pour savoir comment activer la journalisation.
Maintenant que vous avez collecté un journal de passerelle, vous vous posez peut-être la question suivante : quelle est la structure du journal et comment le lire ? Bonne question ! Je vais vous fournir ici quelques informations de base pour vous aider à démarrer. Malheureusement, il n'est pas toujours possible d'interpréter complètement le journal sans avoir accès au code source. Pour les situations complexes, n'hésitez pas à contacter le WRC (Centre de réponse global d'InterSystems) !
Pour démystifier la structure du journal, rappelez-vous qu'il s'agit toujours d'un morceau de données suivi d'une description de ce qu'il fait. Par exemple, voyez cette image avec une coloration syntaxique de base :

Afin de comprendre ce que Received signifie ici, vous devez vous rappeler que le journal de la passerelle enregistre les interactions entre la passerelle et la base de données descendante. Ainsi, Received signifie que la passerelle a reçu l'information de Caché/Ensemble. Dans l'exemple ci-dessus, la passerelle a reçu le texte d'une requête SELECT. Les significations des différentes valeurs de msgId peuvent être trouvées dans le code interne. Le 33 que nous voyons ici signifie " Preparer l'instruction ".
Le journal lui-même fournit également des informations sur le pilote, ce qui est intéressant à vérifier lors du débogage des problèmes. Voici un exemple,
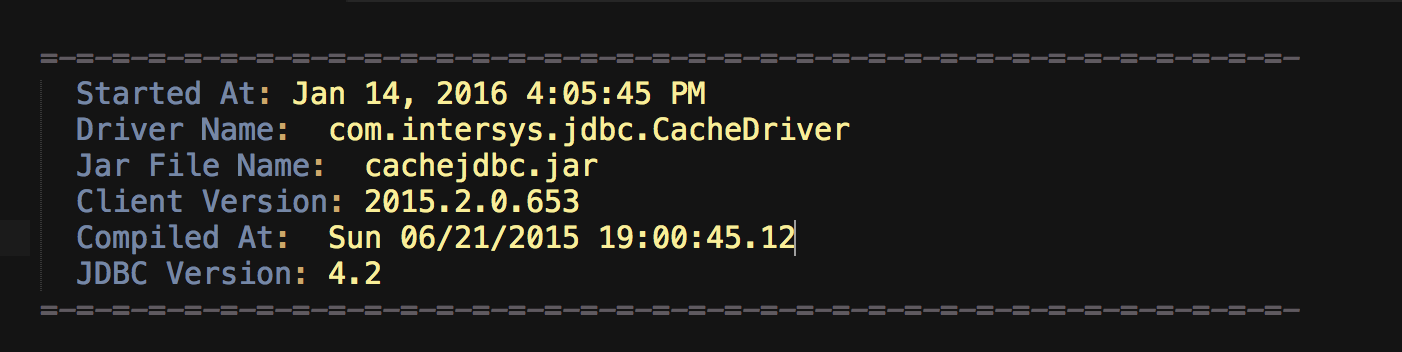
Comme nous pouvons le voir, le Driver Name est com.intersys.jdbc.CacheDriver, ce qui est le nom du pilote utilisé pour se connecter au processus de passerelle. Le Jar File Name est cachejdbc.jar, ce qui est le nom du fichier jar situé dans <cache_install_directory>\lib\.
Pour trouver le processus de passerelle, vous pouvez exécuter la commande ps. Par exemple,
ps -ef | grep java
Cette commande ps affiche des informations sur le processus Java, notamment le numéro de port, le fichier jar, le fichier journal, l'ID du processus Java et la commande qui a lancé le processus Java.
Voici un exemple du résultat de la commande :
mlimbpr15:~ mli$ ps -ef | grep java
17182 45402 26852 0 12:12PM ?? 0:00.00 sh -c java -Xrs -classpath /Applications/Cache20151/lib/cachegateway.jar:/Applications/Cache20151/lib/cachejdbc.jar com.intersys.gateway.JavaGateway 62972 /Applications/Cache20151/mgr/JDBC.log 2>&1
17182 45403 45402 0 12:12PM ?? 0:00.22 /usr/bin/java -Xrs -classpath /Applications/Cache20151/lib/cachegateway.jar:/Applications/Cache20151/lib/cachejdbc.jar com.intersys.gateway.JavaGateway 62972 /Applications/Cache20151/mgr/JDBC.log
502 45412 45365 0 12:12PM ttys000 0:00.00 grep java
Dans Windows, vous pouvez consulter le gestionnaire des tâches pour trouver des informations sur le processus de passerelle.
Il y a deux façons de lancer et d'arrêter la passerelle :
Vous pouvez lancer et arrêter la passerelle dans le SMP en accédant à [System Administration] -> [Configuration] -> [Connectivity] -> [JDBC Gateway Server].

Sur les machines Unix, vous pouvez également démarrer la passerelle depuis le terminal. Comme nous l'avons vu dans la section précédente, le résultat de ps -ef | grep java contient la commande qui a démarré le processus Java, qui dans l'exemple ci-dessus est le suivant:
java -Xrs -classpath /Applications/Cache20151/lib/cachegateway.jar:/Applications/Cache20151/lib/cachejdbc.jar com.intersys.gateway.JavaGateway 62972 /Applications/Cache20151/mgr/JDBC.log
Pour arrêter la passerelle depuis le terminal, vous pouvez tuer le processus. L'ID du processus Java est le deuxième chiffre de la ligne qui contient la commande ci-dessus, dans l'exemple ci-dessus c'est 45402. Ainsi, pour arrêter la passerelle, vous pouvez exécuter :
kill 45402
Exécuter un programme Java pour se connecter à une base de données descendante est un excellent moyen de tester la connexion, de vérifier la requête et d'aider à isoler la cause d'un problème donné. Je joins un exemple de programme Java qui établit une connexion avec SQL Server et imprime une liste de tous les tableaux. J'expliquerai pourquoi cela peut être utile dans la section suivante.
import java.sql.*;
import java.sql.Date;
import java.util.*;
import java.lang.reflect.Method;
import java.io.InputStream;
import java.io.ByteArrayInputStream;
import java.math.BigDecimal;
import javax.sql.*;
// Auteur : Vicky Li
// Ce programme établit une connexion avec le serveur SQL et récupère tous les tableaux. Le résultat est une liste de tableaux.
public class TestConnection {
public static void main(String[] args) {
try {
Class.forName("com.microsoft.sqlserver.jdbc.SQLServerDriver");
//please replace url, username, and password with the correct parameters
Connection conn = DriverManager.getConnection(url,username,password);
System.out.println("connected");
DatabaseMetaData meta = conn.getMetaData();
ResultSet res = meta.getTables(null, null, null, new String[] {"TABLE"});
System.out.println("List of tables: ");
while (res.next()) {
System.out.println(
" " + res.getString("TABLE_CAT") +
", " + res.getString("TABLE_SCHEM") +
", " + res.getString("TABLE_NAME") +
", " + res.getString("TABLE_TYPE")
);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
Pour exécuter ce programme Java (ou tout autre programme Java), vous devez d'abord compiler le fichier .java, qui dans notre cas s'appelle TestConnection.java. Ensuite, un nouveau fichier sera généré au même endroit, que vous pourrez ensuite exécuter avec la commande suivante sur un système UNIX :
java -cp "<path to driver>/sqljdbc4.jar:lib/*:." TestConnection
Dans Windows, vous pouvez exécuter la commande suivante :
java -cp "<path to driver>/sqljdbc4.jar;lib/*;." TestConnection
jstackComme son nom l'indique, jstack imprime l'arborescence des appels de procédure Java. Cet outil peut devenir pratique lorsque vous avez besoin de mieux comprendre ce que fait le processus Java. Par exemple, si vous voyez le processus de la passerelle s'accrocher à un certain message dans le journal des passerelles, vous pourriez vouloir recueillir une trace jstack. Je tiens à souligner que jstack est un outil de bas niveau qui ne devrait être utilisé que lorsque d'autres méthodes, comme l'analyse du journal des passerelles, ne résolvent pas le problème.
Avant de collecter une trace jstack, vous devez vous assurer que le JDK est installé. Voici la commande pour collecter une trace jstack :
jstack -F <pid> > /<path to file>/jstack.txt
où le pid est l'ID du processus de la passerelle, qui peut être obtenu en exécutant la commande ps, telle que ps -ef | grep java. Pour plus d'informations sur la façon de trouver le pid, veuillez consulter Lancement et arrêt de la passerelle.
Maintenant, voici quelques considérations spéciales pour les machines Red Hat. Dans le passé, il y a eu des problèmes pour attacher jstack au processus de la passerelle JDBC (ainsi qu'au processus du service métier de la passerelle Java lancé par Ensemble) sur certaines versions de Red Hat, donc la meilleure façon de collecter une trace jstack sur Red Hat est de lancer le processus de la passerelle manuellement. Pour les instructions, veuillez consulter Collecter une trace jstack sur Red Hat.
Dans cette situation, vérifiez la version de Java et les variables d'environnement.
Pour vérifier la version de Java, vous pouvez exécuter la commande suivante à partir d'un terminal :
java -version
Si vous obtenez l'erreur java : Command not found, cela signifie que le processus Cache ne peut pas trouver l'emplacement des exécutables Java. Cela peut généralement être résolu en plaçant les exécutables Java dans le PATH. Si vous rencontrez des problèmes, n'hésitez pas à contacter le WRC (Centre de réponse global).
Un bon diagnostic des échecs de connexion est la vérification du lancement du processus de la passerelle. Vous pouvez le faire en vérifiant le journal de la passerelle ou le processus de la passerelle. Sur les versions modernes, vous pouvez également aller sur le SMP et visiter [System Administration] -> [Configuration] -> [Connectivity] -> [JDBC Gateway Server], et vérifier si la page affiche "JDBC Gateway is running".
Si le processus de passerelle ne s'exécute pas, il est probable que Java n'est pas installé correctement ou que vous utilisez le mauvais port ; si le processus de passerelle s'exécute, il est probable que les paramètres de connexion sont incorrects.
Dans le premier cas, veuillez vous reporter à la section précédente et vérifiez le numéro de port. Je discuterai plus en détail de la deuxième situation ici.
Il est de la responsabilité du client d'utiliser les paramètres de connexion corrects :
Vous pouvez vérifier si vous avez les bons paramètres de l'une des trois façons suivantes :
Utilisez le bouton "Test Connection" après avoir sélectionné un nom de connexion dans [System Administration] -> [Configuration] -> [Connectivity] -> [SQL Gateway Connections].
Note : pour les systèmes modernes, "Test Connection" donne des messages d'erreur utiles ; pour les systèmes plus anciens, le JDBC gateway log est nécessaire pour trouver plus d'informations sur l'échec.
Exécutez la ligne de commande suivante depuis un terminal Caché pour tester la connexion :
d $SYSTEM.SQLGateway.TestConnection(<connection name>)
Exécutez un programme Java pour établir une connexion. Le programme que vous écrivez peut être similaire à l' example dont nous avons parlé précédemment.
Pour cette catégorie, il est souvent plus utile de travailler avec le WRC (Centre de réponse global). Voici ce que nous faisons souvent pour déterminer si le problème se situe dans notre code interne ou dans la base de données distante (ou dans le pilote) :
Le nom de la classe du Service Métier d' Ensemble est EnsLib.JavaGateway.Service, et la classe de l'adaptateur est EnsLib.JavaGateway.ServiceAdapter. La session Ensemble crée d'abord une connexion avec le serveur Java Gateway, qui est un processus Java. L'architecture est similaire à celle de la passerelle JDBC SQL, sauf que le processus Java est géré par l'opération commerciale. Pour plus de détails, veuillez consulter la documentation.
Pour activer le journal du pilote, vous devez ajouter un nom de fichier journal à la fin de la chaîne de connexion JDBC. Par exemple, si la chaîne de connexion originale ressemble à czci :
jdbc:Cache://127.0.0.1:1972/USER
Pour activer la journalisation, ajoutez un fichier (jdbc.log) à la fin de la chaîne de connexion, de sorte qu'elle ressemble à ceci :
jdbc:Cache://127.0.0.1:1972/USER/jdbc.log
Le fichier journal sera enregistré dans le répertoire de travail de l'application Java.
Si vous utilisez le service métier de la passerelle Java dans Ensemble pour accéder à une autre base de données, vous devez, pour activer la journalisation, spécifier le chemin et le nom d'un fichier journal (par exemple, /tmp/javaGateway.log) dans le champ "Log File" du service de la passerelle Java. Veuillez noter que le chemin d'accès doit exister.
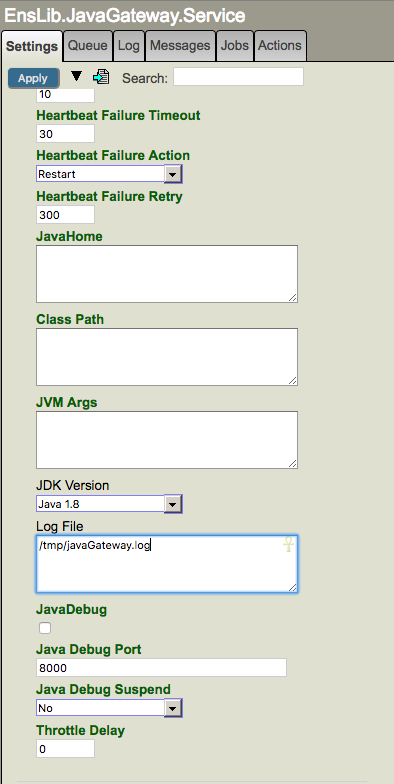
N'oubliez pas que la connexion de la passerelle Java utilisée par la production Ensemble est distincte des connexions utilisées par les tableaux liés ou d'autres productions. Ainsi, si vous utilisez Ensemble, vous devez collecter le journal dans le service de passerelle Java. Le code qui démarre le service de passerelle Java utilise le paramètre "Log File" dans Ensemble, et n'utilise pas le paramètre dans la passerelle Caché SQL dans le SMP comme décrit précédemment.
jstack sur Red HatLa clé ici est de lancer le processus de la passerelle manuellement, et la commande pour lancer la passerelle peut être obtenue en exécutant ps -ef | grep java. Vous trouverez ci-dessous les étapes complètes à suivre pour collecter une trace jstack sur Red Hat lors de l'exécution de la passerelle JDBC ou du service métier de la passerelle Java.
Assurez-vous que le JDK est installé.
Dans un terminal, exécutez ps -ef | grep java. Obtenez les deux informations suivantes à partir du résultat :
a. Copiez la commande qui a lancé la passerelle. Cela devrait ressembler à quelque chose comme ça : java -Xrs -classpath /Applications/Cache20151/lib/cachegateway.jar:/Applications/Cache20151/lib/cachejdbc.jar com.intersys.gateway.JavaGateway 62972 /Applications/Cache20151/mgr/JDBC2.log
b. Obtenez l'ID du processus Java (pid), qui est le deuxième chiffre de la ligne qui contient la commande ci-dessus.
Arrêtez le processus avec kill <pid>.
Exécutez la commande que vous avez copiée à l'étape 2.a. pour lancer manuellement un processus de passerelle.
Jetez un coup d'oeil au journal de la passerelle (dans notre exemple, il est situé dans /Applications/Cache20151/mgr/JDBC2.log) et assurez-vous que vous voyez des entrées comme >> LOAD_JAVA_CLASS: com.intersys.jdbc.CacheDriver. Cette étape est juste pour vérifier qu'un appel à la passerelle est effectué avec succès.
Dans un nouveau terminal, exécutez ps -ef | grep java pour obtenir le pid du processus de la passerelle.
Rassemblez une trace jstack : jstack -F <pid> > /tmp/jstack.txt

Quand on travaille avec les globales, on voit qu’il n’y a pas mantes fonction en ObjectScript (COS) à utiliser. C’est aussi le cas avec Python et Java. Toutefois, toutes ses fonctions sont indispensables quand on travaille directement avec les données sans utilisation des objets, des documents ou des tables.
Dans cet article je voudrais parler de différentes fonctions et commandes qui se servent à travailler avec les globales dans trois langues : ObjectScript, Python et Java (les deux derniers en utilisant Native API).
Dans cet article, je vais vous montrer comment vous pouvez facilement conteneuriser les passerelles .Net/Java.
Pour notre exemple, nous allons développer une intégration avec Apache Kafka.
Et pour interopérer avec le code Java/.Net, nous utiliserons PEX.
Notre solution fonctionnera entièrement dans docker et ressemblera à ceci :
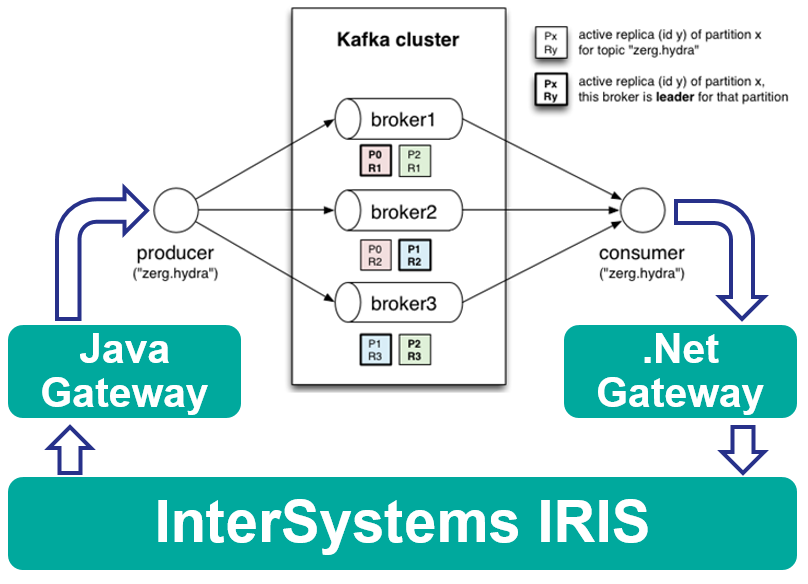
Tout d'abord, nous allons développer l'opération Java pour envoyer des messages dans Kafka. Le code peut être écrit dans l'IDE de votre choix et il peut ressembler à ceci.
En bref :
Maintenant, plaçons-le dans Docker !
Voici notre dockerfile :
FROM openjdk:8 AS builder
ARG APP_HOME=/tmp/app
COPY src $APP_HOME/src
COPY --from=intersystemscommunity/jgw:latest /jgw/*.jar $APP_HOME/jgw/
WORKDIR $APP_HOME/jar/
ADD https://repo1.maven.org/maven2/org/apache/kafka/kafka-clients/2.5.0/kafka-clients-2.5.0.jar .
ADD https://repo1.maven.org/maven2/ch/qos/logback/logback-classic/1.2.3/logback-classic-1.2.3.jar .
ADD https://repo1.maven.org/maven2/ch/qos/logback/logback-core/1.2.3/logback-core-1.2.3.jar .
ADD https://repo1.maven.org/maven2/org/slf4j/slf4j-api/1.7.30/slf4j-api-1.7.30.jar .
WORKDIR $APP_HOME/src
RUN javac -classpath $APP_HOME/jar/*:$APP_HOME/jgw/* dc/rmq/KafkaOperation.java && \
jar -cvf $APP_HOME/jar/KafkaOperation.jar dc/rmq/KafkaOperation.class
FROM intersystemscommunity/jgw:latest
COPY --from=builder /tmp/app/jar/*.jar $GWDIR/
Allons-y ligne par ligne et voyons ce qui se passe ici (je suppose que vous connaissez les constructions docker à plusieurs niveaux) :
FROM openjdk:8 AS builder
Notre image de départ est JDK 8.
ARG APP_HOME=/tmp/app
COPY src $APP_HOME/src
Nous copions nos sources du dossier /src dans le dossier /tmp/app.
COPY --from=intersystemscommunity/jgw:latest /jgw/*.jar $APP_HOME/jgw/
Nous copions les sources de la passerelle Java dans le dossier /tmp/app/jgw.
WORKDIR $APP_HOME/jar/
ADD https://repo1.maven.org/maven2/org/apache/kafka/kafka-clients/2.5.0/kafka-clients-2.5.0.jar .
ADD https://repo1.maven.org/maven2/ch/qos/logback/logback-classic/1.2.3/logback-classic-1.2.3.jar .
ADD https://repo1.maven.org/maven2/ch/qos/logback/logback-core/1.2.3/logback-core-1.2.3.jar .
ADD https://repo1.maven.org/maven2/org/slf4j/slf4j-api/1.7.30/slf4j-api-1.7.30.jar .
WORKDIR $APP_HOME/src
RUN javac -classpath $APP_HOME/jar/*:$APP_HOME/jgw/* dc/rmq/KafkaOperation.java && \
jar -cvf $APP_HOME/jar/KafkaOperation.jar dc/rmq/KafkaOperation.class
Maintenant toutes les dépendances sont ajoutées et javac/jar est appelé pour compiler le fichier jar. Pour un projet concret, il est préférable d'utiliser maven ou gradle.
FROM intersystemscommunity/jgw:latest
COPY --from=builder /tmp/app/jar/*.jar $GWDIR/
Et enfin, les jars sont copiés dans l'image de base jgw (l'image de base se charge également du démarrage de la passerelle et des tâches connexes).
Vient ensuite le service .Net qui recevra les messages de Kafka. Le code peut être écrit dans l'IDE de votre choix et il peut ressembler à ceci.
En bref :
Maintenant, plaçons-le dans Docker !
Voici notre dockerfile :
FROM mcr.microsoft.com/dotnet/core/sdk:2.1 AS build
ENV ISC_PACKAGE_INSTALLDIR /usr/irissys
ENV GWLIBDIR lib
ENV ISC_LIBDIR ${ISC_PACKAGE_INSTALLDIR}/dev/dotnet/bin/Core21
WORKDIR /source
COPY --from=store/intersystems/iris-community:2020.2.0.211.0 $ISC_LIBDIR/*.nupkg $GWLIBDIR/
# copier csproj et restaurer en tant que couches distinctes
COPY *.csproj ./
RUN dotnet restore
# copier et publier l'application et les bibliothèques
COPY . .
RUN dotnet publish -c release -o /app
# étape/image finale
FROM mcr.microsoft.com/dotnet/core/runtime:2.1
WORKDIR /app
COPY --from=build /app ./
# Configurations pour démarrer le serveur passerelle
RUN cp KafkaConsumer.runtimeconfig.json IRISGatewayCore21.runtimeconfig.json && \
cp KafkaConsumer.deps.json IRISGatewayCore21.deps.json
ENV PORT 55556
CMD dotnet IRISGatewayCore21.dll $PORT 0.0.0.0
Allons-y ligne par ligne :
FROM mcr.microsoft.com/dotnet/core/sdk:2.1 AS build
Nous utilisons le SDK complet .Net Core 2.1 pour construire notre application.
ENV ISC_PACKAGE_INSTALLDIR /usr/irissys
ENV GWLIBDIR lib
ENV ISC_LIBDIR ${ISC_PACKAGE_INSTALLDIR}/dev/dotnet/bin/Core21
WORKDIR /source
COPY --from=store/intersystems/iris-community:2020.2.0.211.0 $ISC_LIBDIR/*.nupkg $GWLIBDIR/
Copiez .Net Gateway NuGets de l'image Docker officielle d'InterSystems dans notre image de constructeur
# copier csproj et restaurer comme couches distinctes
COPY *.csproj ./
RUN dotnet restore
# copier et publier l'application et les bibliothèques
COPY . .
RUN dotnet publish -c release -o /app
Construisez notre bibliothèque.
# étape/image finale
FROM mcr.microsoft.com/dotnet/core/runtime:2.1
WORKDIR /app
COPY --from=build /app ./
Copiez les dll de la bibliothèque dans le conteneur final que nous exécuterons réellement.
# Configurats pour démarrer le serveur Gateway
RUN cp KafkaConsumer.runtimeconfig.json IRISGatewayCore21.runtimeconfig.json && \
cp KafkaConsumer.deps.json IRISGatewayCore21.deps.json
Actuellement, la passerelle .Net doit charger toutes les dépendances au démarrage, nous lui faisons donc connaître toutes les dépendances possibles.
ENV PORT 55556
CMD dotnet IRISGatewayCore21.dll $PORT 0.0.0.0
Démarrez la passerelle sur le port 55556 en écoutant sur toutes les interfaces.
Et voilà, c'est tout !
Voici un docker-compose complet pour que tout fonctionne (y compris Kafka et Kafka UI pour voir les messages).
Pour exécuter la démo, vous dever :
git clone https://github.com/intersystems-community/pex-demo.git cd pex-demo docker-compose pull docker-compose up -d
Avis important : Les bibliothèques Java Gateway et .Net Gateway DOIVENT provenir de la même version que le client InterSystems IRIS.