1. Fhir-client-python
Ceci est un client fhir simple en python pour s'exercer avec les ressources fhir et les requêtes CRUD vers un serveur FHIR.
Notez que pour la plupart, l'autocomplétion est activée, c'est la principale raison d'utiliser fhir.resources.
GitHub
2. Préalables
Assurez-vous que git et Docker desktop sont installé.
Si vous travaillez à l'intérieur du conteneur, comme il est montré dans 3.3., vous n'avez pas besoin d'installer fhirpy et fhir.resources.
Si vous n'êtes pas dans le conteneur, vous pouvez utiliser pip pour installer fhirpy et fhir.resources.
Vérifiez fhirpy et fhir.resources pour plus d'information.
3. Installation
3.1. Installation pour le développement
Clone/git tire le repo dans n'importe quel répertoire local, par exemple comme indiqué ci-dessous :
git clone https://github.com/LucasEnard/fhir-client-python.git
Ouvrez le terminal dans ce répertoire et lancez :
docker build.
3.2. Portail de gestion et VSCode
Ce référentiel est prêt pour VS Code.
Ouvrez le dossier fhir-client-python cloné localement dans VS Code.
Si vous y êtes invité (coin inférieur droit), installez les extensions recommandées.
3.3. Avoir le dossier ouvert à l'intérieur du conteneur
Vous pouvez être à l'intérieur du conteneur avant de coder si vous le souhaitez.
Pour cela, il faut que docker soit activé avant d'ouvrir VSCode.
Ensuite, dans VSCode, lorsque vous y êtes invité ( coin inférieur droit ), rouvrez le dossier à l'intérieur du conteneur afin de pouvoir utiliser les composants python qu'il contient.
La première fois que vous effectuez cette opération, cela peut prendre plusieurs minutes, le temps que le conteneur soit préparé.
Si vous n'avez pas cette option, vous pouvez cliquer dans le coin inférieur gauche et cliquer sur Ouvrir à nouveau dans le conteneur puis sélectionner De Dockerfile
Plus d'informations ici

En ouvrant le dossier à distance, vous permettez à VS Code et à tous les terminaux que vous ouvrez dans ce dossier d'utiliser les composants python dans le conteneur.
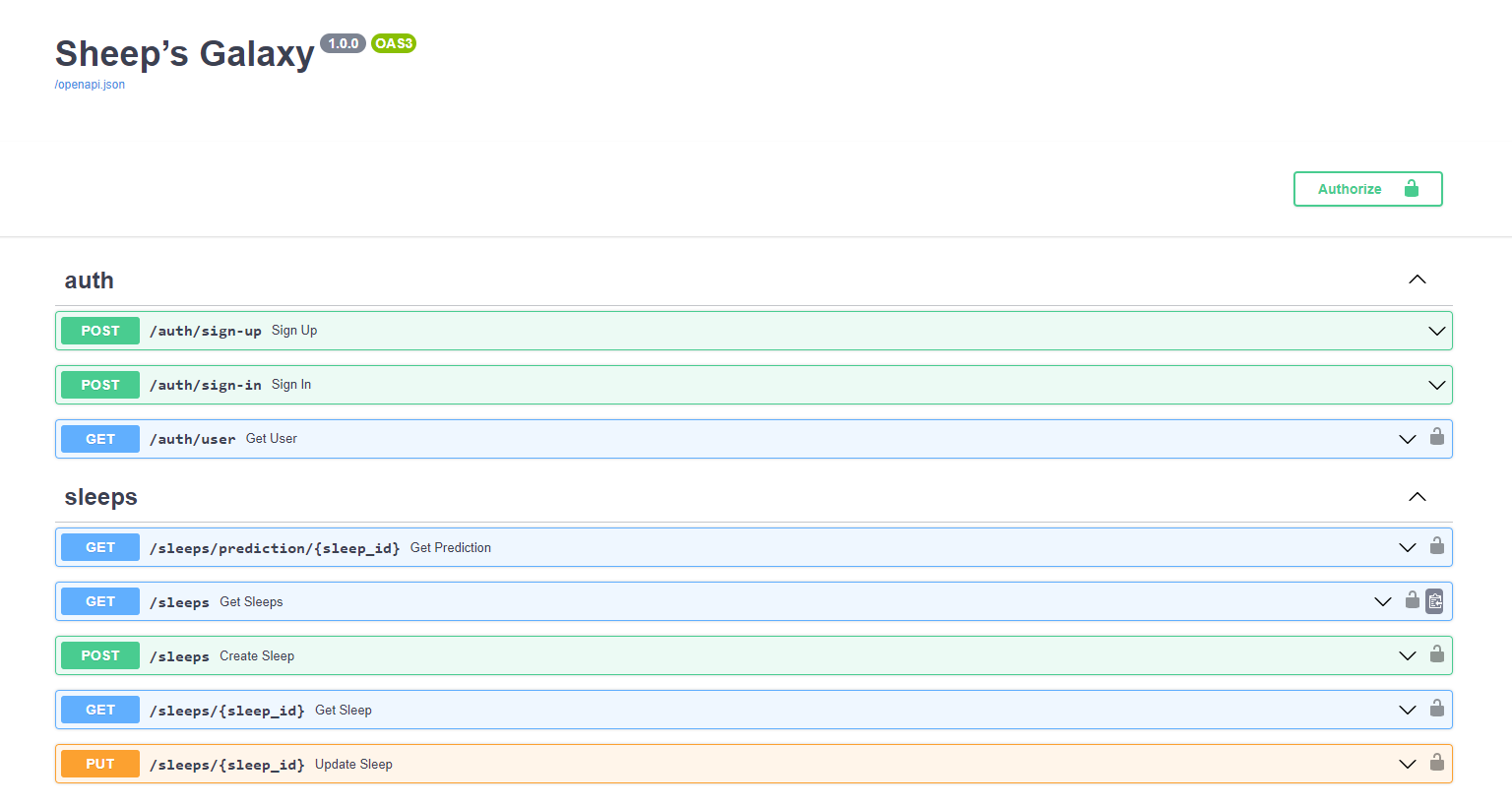
4. Serveur FHIR
Pour réaliser cette présentation, vous aurez besoin d'un serveur FHIR.
Vous pouvez soit utiliser le vôtre, soit vous rendre sur le site InterSystems free FHIR trial et suivre les étapes suivantes pour le configurer.
En utilisant notre essai gratuit, il suffit de créer un compte et de commencer un déploiement, puis dans l'onglet Overview vous aurez accès à un endpoint comme https://fhir.000000000.static-test-account.isccloud.io que nous utiliserons plus tard.
Ensuite, en allant dans l'onglet d'informations d'identification Credentials, créez une clé api et enregistrez-la quelque part.
C'est maintenant terminé, vous avez votre propre serveur fhir pouvant contenir jusqu'à 20 Go de données avec une mémoire de 8 Go.
5. Présentation pas à pas
La présentation pas à pas du client se trouve à src/client.py.
Le code est divisé en plusieurs parties, et nous allons couvrir chacune d'entre elles ci-dessous.
5.1. Partie 1
Dans cette partie, nous connectons notre client à notre serveur en utilisant fhirpy et nous obtenons nos ressources Patient à l'intérieur de la variable patients_resources.
A partir de cette variable nous pourrons fecth n'importe quel Patient et même les trier ou obtenir un Patient en utilisant certaines conditions.
#Partie 1----------------------------------------------------------------------------------------------------------------------------------------------------
#Créer notre client connecté à notre serveur
client = SyncFHIRClient(url='url', extra_headers={"x-api-key":"api-key"})
#Obtenir les ressources de notre patient dans lesquelles nous pourrons aller chercher et rechercher
patients_resources = client.resources('Patient')
Afin de vous connecter à votre serveur, vous devez modifier la ligne :
client = SyncFHIRClient(url='url', extra_headers={"x-api-key":"api-key"})
L'url' est un point de terminaison tandis que l'"api-key" est la clé d'api pour accéder à votre serveur.
Notez que si vous n'utilisez pas un serveur InterSystems, vous pouvez vérifier comment changer extra_headers={"x-api-key":"api-key"} en authorization = "api-key".
Comme ça, nous avons un client FHIR capable d'échanger directement avec notre serveur.
5.2. Partie 2
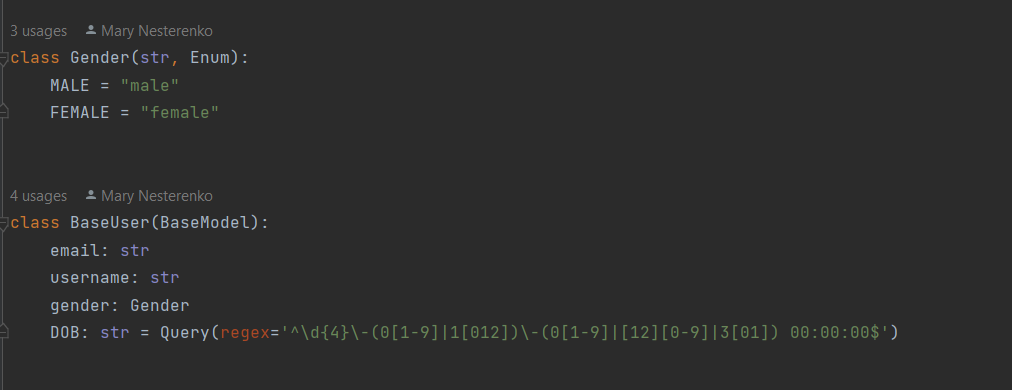
Dans cette partie, nous créons un Patient en utilisant Fhir.Model et nous le complétons avec un HumanName, en suivant la convention FHIR, use et family sont des chaînes et given est une liste de chaînes. e la même manière, un patient peut avoir plusieurs HumanNames, donc nous devons mettre notre HumanName dans une liste avant de le mettre dans notre patient nouvellement créé.
#Partie 2----------------------------------------------------------------------------------------------------------------------------------------------------
#Nous voulons créer un patient et l'enregistrer sur notre serveur
#Créer un nouveau patient en utilisant fhir.resources
patient0 = Patient()
#Créer un HumanName et le remplir avec les informations de notre patient
name = HumanName()
name.use = "official"
name.family = "familyname"
name.given = ["givenname1","givenname2"]
patient0.name = [name]
#Vérifier notre patient dans le terminal
print()
print("Our patient : ",patient0)
print()
#Sauvegarder (post) notre patient0, cela va le créer sur notre serveur
client.resource('Patient',**json.loads(patient0.json())).save()
Après cela, nous devons sauvegarder notre nouveau Patient sur notre serveur en utilisant notre client.
Notez que si vous lancez client.py plusieurs fois, plusieurs Patients ayant le nom que nous avons choisi seront créés.
C'est parce que, suivant la convention FHIR, vous pouvez avoir plusieurs Patients avec le même nom, seul l' id est unique sur le serveur.
Alors pourquoi n'avons-nous pas rempli notre Patient avec un id de la même façon que nous avons rempli son nom ?
Parce que si vous mettez un id à l'intérieur de la fonction save(), la sauvegarde agira comme une mise à jour avant d'agir comme un sauveur, et si l'id n'est en fait pas déjà sur le serveur, il le créera comme prévu ici. Mais comme nous avons déjà des patients sue notre serveur, ce n'est pas une bonne idée de créer un nouveau patient et d'allouer à la main un Identifiant puisque la fonction save() et le serveur sont faits pour le faire à votre place.
Nous conseillons donc de commenter la ligne après le premier lancement.
5.3. Partie 3
Dans cette partie, nous avons un client qui cherche dans nos patients_resources un patient nommé d'après celui que nous avons créé précédemment.
#Partie 3----------------------------------------------------------------------------------------------------------------------------------------------------
#Maintenant, nous voulons obtenir un certain patient et ajouter son numéro de téléphone et changer son nom avant de sauvegarder nos changements sur le serveur
#Obtenez le patient en tant que fhir.resources Patient de notre liste de ressources de patients qui a le bon nom, pour la commodité, nous allons utiliser le patient que nous avons créé avant
patient0 = Patient.parse_obj(patients_resources.search(family='familyname',given='givenname1').first().serialize())
#Créer le nouveau numéro de téléphone de notre patient
telecom = ContactPoint()
telecom.value = '555-748-7856'
telecom.system = 'phone'
telecom.use = 'home'
#Ajouter le téléphone de notre patient à son dossier
patient0.telecom = [telecom]
#Changer le deuxième prénom de notre patient en "un autre prénom"
patient0.name[0].given[1] = "anothergivenname"
#Vérifiez notre Patient dans le terminal
print()
print("Notre patient avec le numéro de téléphone et le nouveau prénom : ",patient0)
print()
#Sauvegarder (mettre) notre patient0, ceci sauvera le numéro de téléphone et le nouveau prénom au patient existant de notre serveur
client.resource('Patient',**json.loads(patient0.json())).save()
Une fois que nous l'avons trouvé, nous ajoutons un numéro de téléphone à son profil et nous changeons son prénom en un autre.
Maintenant nous pouvons utiliser la fonction de mise à jour de notre client pour mettre à jour notre patient sur le serveur.
5.4. Partie 4
Dans cette partie, nous voulons créer une observation pour notre patient précédent, pour ce faire, nous cherchons d'abord notre patients_resources pour notre patient, puis nous obtenons son identifiant, qui est son identificateur unique.
#Partie 4----------------------------------------------------------------------------------------------------------------------------------------------------
#Maintenant nous voulons créer une observation pour notre client
#Obtenir l'identifiant du patient auquel vous voulez attacher l'observation
id = Patient.parse_obj(patients_resources.search(family='familyname',given='givenname1').first().serialize()).id
print("id of our patient : ",id)
#Placer notre code dans notre observation, code qui contient des codages qui sont composés de système, code et affichage
coding = Coding()
coding.system = "https://loinc.org"
coding.code = "1920-8"
coding.display = "Aspartate aminotransférase [Activité enzymatique/volume] dans le sérum ou le plasma"
code = CodeableConcept()
code.coding = [coding]
code.text = "Aspartate aminotransférase [Activité enzymatique/volume] dans le sérum ou le plasma"
#Créer une nouvelle observation en utilisant fhir.resources, nous entrons le statut et le code dans le constructeur car ils sont nécessaires pour valider une observation
observation0 = Observation(status="final",code=code)
#Définir notre catégorie dans notre observation, catégorie qui détient les codages qui sont composés de système, code et affichage
coding = Coding()
coding.system = "https://terminology.hl7.org/CodeSystem/observation-category"
coding.code = "laboratoire"
coding.display = "laboratoire"
category = CodeableConcept()
category.coding = [coding]
observation0.category = [category]
#Définir l'heure de notre date effective dans notre observation
observation0.effectiveDateTime = "2012-05-10T11:59:49+00:00"
#Régler l'heure de notre date d'émission dans notre observation
observation0.issued = "2012-05-10T11:59:49.565+00:00"
#Définir notre valueQuantity dans notre observation, valueQuantity qui est composée d'un code, d'un unir, d'un système et d'une valeur
valueQuantity = Quantity()
valueQuantity.code = "U/L"
valueQuantity.unit = "U/L"
valueQuantity.system = "https://unitsofmeasure.org"
valueQuantity.value = 37.395
observation0.valueQuantity = valueQuantity
#Définir la référence à notre patient en utilisant son identifiant
reference = Reference()
reference.reference = f"Patient/{id}"
observation0.subject = reference
#Vérifiez notre observation dans le terminal
print()
print("Notre observation : ",observation0)
print()
#Sauvegarder (poster) notre observation0 en utilisant notre client
client.resource('Observation',**json.loads(observation0.json())).save()
Ensuite, nous enregistrons notre observation à l'aide de la fonction save().
5.5. Conclusion de la présentation
Si vous avez suivi ce parcours, vous savez maintenant exactement ce que fait client.py, vous pouvez le lancer et vérifier votre Patient et votre Observation nouvellement créés sur votre serveur.
6. Comment ça marche
6.1. Les importations
from fhirpy import SyncFHIRClient
from fhir.resources.patient import Patient
from fhir.resources.observation import Observation
from fhir.resources.humanname import HumanName
from fhir.resources.contactpoint import ContactPoint
import json
La première importation est le client, ce module va nous aider à nous connecter au serveur, à obtenir et exporter des ressources.
Le module fhir.resources nous aide à travailler avec nos ressources et nous permet, grâce à l'auto-complétion, de trouver les variables dont nous avons besoin.
La dernière importation est json, c'est un module nécessaire pour échanger des informations entre nos 2 modules.
6.2. Création du client
client = SyncFHIRClient(url='url', extra_headers={"x-api-key":"api-key"})
L''url' est ce que nous avons appelé avant un point de terminaison tandis que l'"api-key"' est la clé que vous avez générée plus tôt.
Notez que si vous n'utilisez pas un serveur InterSystems, vous voudrez peut-être changer le extra_headers={"x-api-key" : "api-key"} en authorization = "api-key"
Comme ça, nous avons un client FHIR capable d'échanger directement avec notre serveur.
Par exemple, vous pouvez accéder à vos ressources Patient en faisant patients_resources = client.resources('Patient') , fà partir de là, vous pouvez soit obtenir vos patients directement en utilisant patients = patients_resources.fetch() ou en allant chercher après une opération, comme :
patients_resources.search(family='familyname',given='givenname').first() cette ligne vous donnera le premier patient qui sort ayant pour nom de famille 'familyname' et pour nom donné 'givenname'.
6.3. Travailler sur nos ressources
Une fois que vous avez les ressources que vous voulez, vous pouvez les analyser dans une ressource fhir.resources.
Par exemple :
patient0 = Patient.parse_obj(patients_resources.search(family='familyname',given='givenname1').first().serialize())
patient0 est un patient de fhir.resources, pour l'obtenir nous avons utilisé nos patients_resources comme cela a été montré précédemment où nous avons sélectionné un certain nom de famille et un prénom, après cela nous avons pris le premier qui est apparu et l'avons sérialisé.
En mettant ce patient sérialisé à l'intérieur d'un Patient.parse_obj nous allons créer un patient de fhir.resources .
Maintenant, vous pouvez accéder directement à n'importe quelle information que vous voulez comme le nom, le numéro de téléphone ou toute autre information.
Pour ce faire, utilisez juste par exemple :
patient0.name
Cela renvoie une liste de HumanName composée chacune d'un attribut use un attribut family un attribut given
as the FHIR convention is asking.
Cela signifie que vous pouvez obtenir le nom de famille de quelqu'un en faisant :
patient0.name[0].family
6.4. Sauvegarder nos changements
Pour enregistrer toute modification de notre serveur effectuée sur un fhir.resources ou pour créer une nouvelle ressource serveur, nous devons utiliser à nouveau notre client.
client.resource('Patient',**json.loads(patient0.json())).save()
En faisant cela, nous créons une nouvelle ressource sur notre client, c'est-à-dire un patient, qui obtient ses informations de notre fhir.resources patient0. Ensuite, nous utilisons la fonction save() pour poster ou mettre notre patient sur le serveur.
7. Comment commencer le codage
Ce référentiel est prêt à être codé dans VSCode avec les plugins InterSystems.
Ouvrez /src/client.py pour commencer à coder ou utiliser l'autocomplétion.
8. Ce qu'il y a dans le référentiel
8.1. Dockerfile
Le dockerfile le plus simple pour démarrer un conteneur Python.
Utilisez docker build . pour construire et rouvrir votre fichier dans le conteneur pour travailler à l'intérieur de celui-ci.
8.2. .vscode/settings.json
Fichier de paramètres.
8.3. .vscode/launch.json
Fichier de configuration si vous voulez déboguer.

.png)
.png)
.png)
.png)
.png)
.png)




.png)






























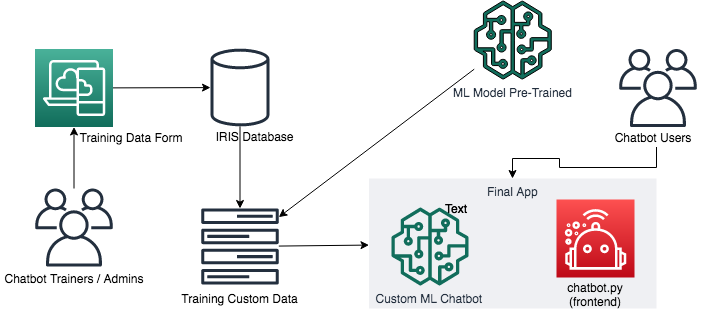


 Nous avons beaucoup d'exemples de dessins animés, d'anime ou de films pour nous rappeler ce qui peut se passer lorsqu'on enseigne à une machine...
Nous avons beaucoup d'exemples de dessins animés, d'anime ou de films pour nous rappeler ce qui peut se passer lorsqu'on enseigne à une machine...






.png)

.png)
.png)
.png)
.png)
.png)


.png)
.png)
.png)
.png)
.png)
.png)

.png)
.png)
.png)
.png)
.png)
.png)

.png)
.png)