Notre objectif
Dans le dernier article, nous avons parlé de quelques éléments de démarrage pour Django. Nous avons appris à commencer le projet, à nous assurer que nous disposons de tous les éléments requis et à créer une matrice CRUD. Cependant, aujourd'hui, nous allons un peu plus loin.
Aujourd'hui, nous allons donc connecter IRIS à un environnement Python, construire quelques fonctions et les afficher sur une page web. Ce sera similaire à la dernière discussion, mais nous irons assez loin pour que vous puissiez faire quelque chose de nouveau, mais pas assez pour que vous vous sentiez perdus.
Dans ce projet, nous obtiendrons des informations sur les globales dans IRIS afin de suivre leur taille et de comprendre le coût de chaque espace de noms et de chaque table en Mo.
Le projet
Chaque étape est disponible sur mon Référentiel GitHub, dans l'historique des commits.
Les éléments de démarrage
Nous suivons quelques étapes similaires à celles de l'article précédent, alors cette partie vous sera familière.
- Allez dans le répertoire souhaité sur le terminal et tapez ce qui suit.
django-admin startproject globalSize
- Ajoutez requirements.txt avec le texte suivant, et tapez
pip install -r requirements.txt
pour être sûr de remplir les conditions requises.
django>=4.2.1
django-iris==0.2.2
- Dans globalSize/settings.py, ajoutez IRIS dans les configurations DATABASES :
DATABASES = {
‘default’: {
‘ENGINE’: ‘django_iris’,
‘NAME’: ‘USER’,
‘USER’: ‘_system’,
‘PASSWORD’: ‘SYS’,
‘HOST’: ‘localhost’,
‘PORT’: 1972,
}
}
- N'oubliez pas d'ajouter un .gitignore et un .editorconfig. Il est également pratique d'avoir un linter de votre choix, mais cela dépasse le cadre de cet article.
Création de l'application et du modèle
Nous avons créé une application et un modèle dans le dernier article, cette section devrait donc vous être familière, même s'il s'agit d'une application et d'un modèle différents.
- Pour créer l'application, saisissez
python manage.py startapp globals
- Dans _globals/models.py, _créez un modèle avec les informations que vous souhaitez afficher sur vos globales :
classirisGlobal(models.Model):
database = models.CharField(max_length=40)
name = models.CharField(max_length=40)
allocatedsize = models.FloatField()
size = models.FloatField()
def__str__(self):return self.name
- Dans _settings.py, _ajoutez la nouvelle application à INSTALLED_APPS :
INSTALLED_APPS = [
…,
‘globals’,
]
Configuration des URL et de la page d'accueil
Une fois de plus, nous suivons quelques étapes similaires à celles de l'article précédent.
- La fonction incluse dans django.urls est importée dans _globalSize/urls.py et un nouveau chemin est ajouté à globals.urls dans urlpatterns.
from django.urls import path, include
urlpatterns = [
…,
path(‘globals/’, include(‘globals.urls’)),
]
- Créez les URLs pour l'application, en ajoutant le fichier globals/urls.py avec le texte suivant.
from django.urls import path
from .views import home
urlpatterns = [
path(‘’, home),
]
- Créez la vue importée dans la dernière étape. Dans view.py, ajoutez la fonction ci-dessous.
defhome(request):return render(request, “index.html”)
- Pour finir, ajoutez le fichier globals/templates/index.html et générez la page d'accueil comme vous le souhaitez. Consultez l'exemple ci-dessous :
hello world!
Si vous entrez les commandes ci-dessous et suivez le lien http://127.0.0.1:8000/globals/, vous aurez une page affichant "hello world !".
python manage.py makemigrations<br>python manage.py migrate<br>python manage.py runserver
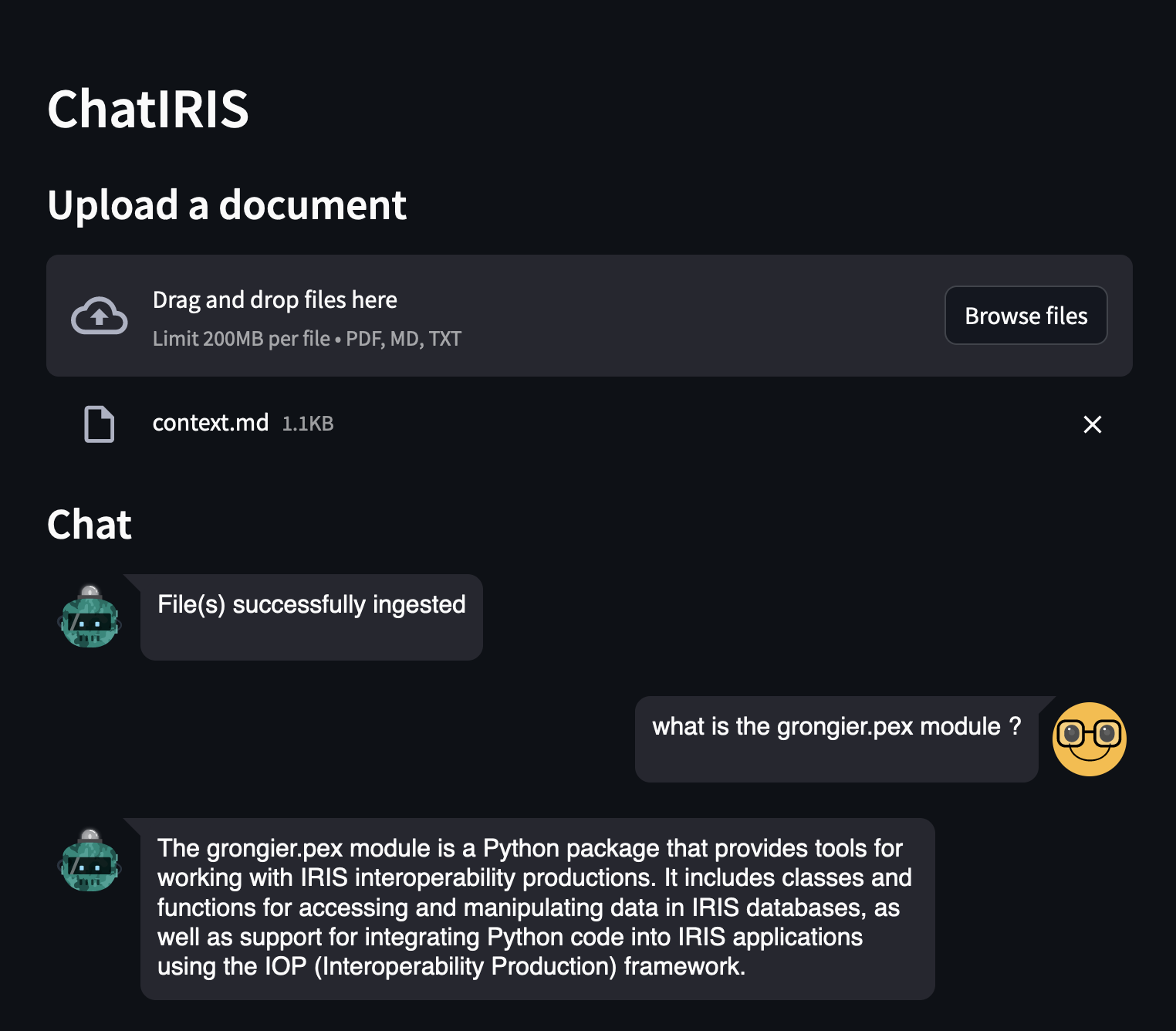
Affichage des globales dans les pages d'accueil et d'administration
- Importez le modèle et enregistrez-le dans le fichier admin.py.
from .models import irisGlobal
admin.site.register(irisGlobal)
- Importez le modèle dans views.py et renvoyez-le dans la fonction.
from .models import irisGlobal
defhome(request):
globals = irisGlobal.objects.all()
return render(request, “index.html”, {“globals”: globals})
- Nous pouvons maintenant accéder aux valeurs globales à partir de _index.html _comme nous le souhaitons. Consultez l'exemple ci-dessous.
ID - DATABASE / GLOBAL - Size / Allocated
{% for global in globals %}
>
{{ global.id }} - {{ global.database }} {{ global.name }} - {{ global.size }} / {{ global.allocatedsize }}
{% endfor %}
Récupération de données
Récupération de données
À ce stade, le projet est prêt à recevoir des informations. Il existe de nombreuses façons de modeler ce projet, mais pour ma part, j'utiliserai l'approche de Python afin que nous puissions apprendre une nouvelle solution qu'il est possible d'intégrer à Django et à IRIS.
Nous avons besoin de quelques méthodes pour récupérer toutes les données. Nous pouvons utiliser InterSystems IRIS Cloud SQL avec le pilote DB-API pour nous connecter à l'instance que nous voulons analyser - il n'est pas nécessaire que ce soit la même que celle où nous avons connecté Django.
L'organiser dans un nouveau dossier que nous pouvons traiter comme un module est une bonne pratique. Pour cela, créez le dossier api dans les globaux, ajoutez un fichier vide _init_.py_ pour que Python le reconnaisse comme un module, et commencez à écrire le fichier qui contiendra les méthodes. Nous pouvons l'appeler methods.py.

Création de la connexion
Pour connecter notre environnement Python à l'IRIS d'InterSystems, nous devons suivre quelques étapes décrites dans la section "ObjectScript dans l'environnement Python" de l'article précédent [Python et IRIS dans la pratique] (https://community.intersystems.com/post/python-and-iris-practice-examples).
A partir de maintenant, c'est simple ; nous importons iris, nous passons l'adresse de la connexion (l'instance d'IRIS que nous voulons analyser dans le format suivant : host:port/namespace), un nom d'utilisateur et un mot de passe à la méthode iris.connect et nous créons IRIS de Python. Jetez un coup d'œil au code ci-dessous.
import intersystems_iris as iris
from django.db import connection as djangoconnection
conn_params = djangoconnection.get_connection_params()
conn_params[“namespace”] = “%SYS”
connection = iris.connect(**conn_params)
irisPy = iris.createIRIS(connection)
Obtention des répertoires de bases de données
Puisque nous voulons récupérer les tailles des globales, nous avons besoin (bien sûr) de leurs tailles, de leurs noms et de leurs adresses - ce que nous appelons des bases de données.
Je vais vous montrer une version simplifiée de la fonction, mais rappelez-vous qu'il est préférable de vérifier chaque étape et chaque connexion, et de lancer une exception si quelque chose ne va pas.
Tout comme nous le ferions en ObjectScript, nous avons besoin d'une requête SQL pour pouvoir la préparer, l'exécuter et récupérer une liste contenant tous les répertoires de la base de données dans son jeu de résultats. Nous pouvons faire tout cela facilement avec les fonctions "irisPy.classMethodSomething()", où Something (quelque chose) représente le type que la méthode doit retourner, et irisObject.invoke(), où nous pouvons accéder à n'importe quoi à partir de l'irisObject référencé. Voici un exemple.
defgetAllDatabaseDirectories():try:
databaseDirectoriesList = []
with connection.cursor() as cursor:
cursor.execute(“SELECT DISTINCT %EXACT(Directory) FROM Config.Databases WHERE SectionHeader = ?”, [“Databases”,],)
databaseDirectoriesList = [row[0] for row in cursor]
except Exception as error:
return str(error)
return databaseDirectoriesList
La variable statement est définie comme un objet généré par la méthode %New de la classe IRIS %SQL.Statement. Il est alors possible d'invoquer la méthode %Prepare à partir de l'objet instancié, avec une chaîne de requête comme argument. Ensuite, nous pouvons invoquer les méthodes %Execute et %Next pour exécuter la requête et boucler sur l'ensemble des résultats, en ajoutant les informations souhaitées à une liste Python pour un accès facile.
Il est facile de trouver chaque répertoire de base de données dans le tableau Config.Databases, situé uniquement dans l'espace de noms %SYS de chaque instance d'IRIS. Consultez-la dans le portail de gestion si vous le souhaitez, vous y trouverez d'autres informations intéressantes.
Récupération de toutes les globales d'une base de données
Cette fonction est très similaire à la précédente. Cependant, nous disposons maintenant d'une requête de classe prête à l'emploi. Une fois de plus, nous avons besoin d'une requête SQL, nous pouvons donc préparer la requête DirectoryList à partir de la classe %SYS.GlobalQuery. Ensuite, nous l'exécutons avec un répertoire de base de données comme argument et nous récupérons une liste contenant tous les globales de cette base de données.
defgetGlobalsList(databaseDirectory: str):try:
statement = irisPy.classMethodObject("%SQL.Statement", "%New")
status = statement.invoke("%PrepareClassQuery", "%SYS.GlobalQuery","DirectoryList")
result = statement.invoke("%Execute", databaseDirectory)
globalList = []
while (result.invoke("%Next")!=0):
globalList.append(result.invoke("%Get", "Name"))
except Exception as error:
return str(error)
return globalList
Récupération des tailles des globales et des tailles allouées
Enfin, nous pouvons accéder aux informations cibles. Heureusement, IRIS dispose d'une méthode intégrée pour récupérer la taille et la taille allouée à condition de fournir une base de données et une paire de globales.
defgetGlobalSize(databaseDirectory: str, globalName: str):try:
globalUsed = iris.IRISReference(0)
globalAllocated = iris.IRISReference(0)
status = irisPy.classMethodObject("%GlobalEdit", "GetGlobalSize", databaseDirectory, globalName, globalAllocated, globalUsed, 0)
except Exception as error:
return str(error)
return (globalUsed.getValue(), globalAllocated.getValue())
Cette fois, nous avons besoin de la fonction IRISReference(0) du module iris pour recevoir les tailles de la fonction "GetGlobalSize" par référence. Ensuite, nous pouvons accéder à la valeur avec la méthode getValue().
Affichage complet sur la page d'accueil
Enfin, nous pouvons utiliser ces fonctions pour afficher les données sur la page d'accueil. Nous disposons déjà d'un moyen pour accéder aux informations et d'un tableau, il ne nous reste plus qu'à le remplir. Pour cela, je veux créer un bouton de mise à jour.
Tout d'abord, nous ajoutons un lien vers le fichier index.html.
…
href = "{% url 'update' %}">updatea>
…
body>
Ajoutez le lien vers la liste urlpatterns, dans urls.py.
Add the link to the urlpatterns list, in urls.py.
from .views import home, update
urlpatterns = [
path('', home),
path('update', update, name="update"),
]
Ensuite, créez la vue, dans views.py.
from django.shortcuts import render, redirect
from .api.methods import *
defupdate(request):
irisGlobal.objects.all().delete()
databaseList = getAllDatabaseDirectories()
for database in databaseList:
globalList = getGlobalsList(database)
for glob in globalList:
used, allocated = getGlobalSize(database, glob)
irisGlobal.objects.create(database=database, name=glob, size=used, allocatedsize=allocated)
return redirect(home)
Pour cette vue, nous devons d'abord importer la fonction de redirection de django.shortcuts, ainsi que les méthodes que nous venons de construire.
C'est une bonne idée de supprimer toutes les données précédentes du tableau afin que les globales éventuellement supprimées disparaissent. Comme le nombre de globales n'est probablement pas gigantesque, il est préférable de procéder ainsi plutôt que de vérifier chaque enregistrement pour voir s'il a été supprimé ou s'il a besoin d'une mise à jour.
Ensuite, nous obtenons tous les répertoires des bases de données afin de pouvoir, pour chaque base de données, vérifier tous les globales qui s'y trouvent, et pour chaque globale, nous pouvons avoir sa taille utilisée et sa taille allouée.
À ce stade, le modèle Django est rempli et prêt à récupérer des données, nous redirigeons donc vers la vue d'accueil.
Si vous accédez à <http://127.0.0.1:8000/globals/> et cliquez sur le lien de mise à jour que nous avons ajouté, la page devrait se recharger et dans quelques secondes, elle affichera la liste des globales, avec ses bases de données, ses tailles et ses tailles allouées, comme dans l'image ci-dessous.
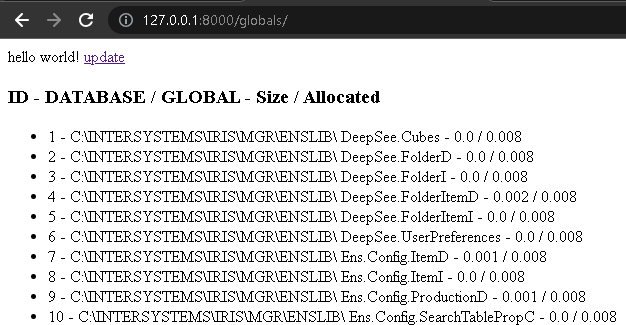
Ajout d'une agrégation
Vous seriez surpris de savoir à quel point il est simple d'ajouter quelques options d'analyse rapide, telles qu'une somme ou un décompte. Il n'est pas nécessaire de maîtriser Django pour créer quelques tableaux de bord sur cette page et, après cette section, vous devriez être en bonne position pour commencer.
Nous savons déjà que la vue accueil est responsable du rendu de l'index. Jusqu'à présent, nous avons généré la variable "globals", contenant toutes les données, et l'avons passée à l'index.html. Nous allons faire quelque chose de similaire, mais avec des fonctions d'agrégation. Nous allons créer une variable pour chaque somme, utiliser les méthodes aggregate() et Sum(), et les ajouter à l'argument "context list" de la fonction "render". Et bien sûr, n'oubliez pas d'importer "Sum" de django.db.models. Consultez la fonction ci-dessous.
defhome(request):
globals = irisGlobal.objects.all()
sumSize = globals.aggregate(Sum("size"))
sumAllocated = globals.aggregate(Sum("allocatedsize"))
return render(request, "index.html", {"globals": globals, "sumSize": sumSize, "sumAllocated":sumAllocated})
Nous pouvons maintenant l'ajouter au fichier index.html et ajouter quelques paragraphes sous la liste (
élément). Dans ces paragraphes, nous pouvons accéder au décompte de toutes les globales et aux sommes, comme indiqué ci-dessous.
…
showing results for {{globals.count}} globalsp>total size: {{sumSize.size__sum}}p><total allocated size: {{sumAllocated.allocatedsize__sum}}p>body>html>
Actualisez le lien et vous devriez obtenir le résultat suivant.

La fin... ou presque
Dans cet article, nous avons appris comment InterSystems IRIS stocke les données en mémoire, comment y accéder à partir de Python, comment construire une API, et comment utiliser IRIS comme un système en nuage, de sorte que nous puissions le suivre et l'analyser facilement. Nous pouvons voir à l'horizon des requêtes plus complexes, la création de tableaux de bord, l'automatisation des mises à jour et l'ajout d'un système de notification.
Dans le prochain article, je me rapprocherai de cet horizon, en montrant comment filtrer et ordonner les données avant de les afficher, en ajoutant quelques options modifiables côté client, et enfin, en ajoutant une pincée de CSS pour donner du charme à l'ensemble.
Souhaitez-vous voir quelque chose que je n'ai pas encore dit ? N'hésitez pas à me contacter si vous avez des idées ou des besoins sur lesquels vous aimeriez que j'écrive.
.png)


.png)







.png)
.png)
.png)
.png)
.png)
.png)
.png)
%20(3).jpg)
.png)


