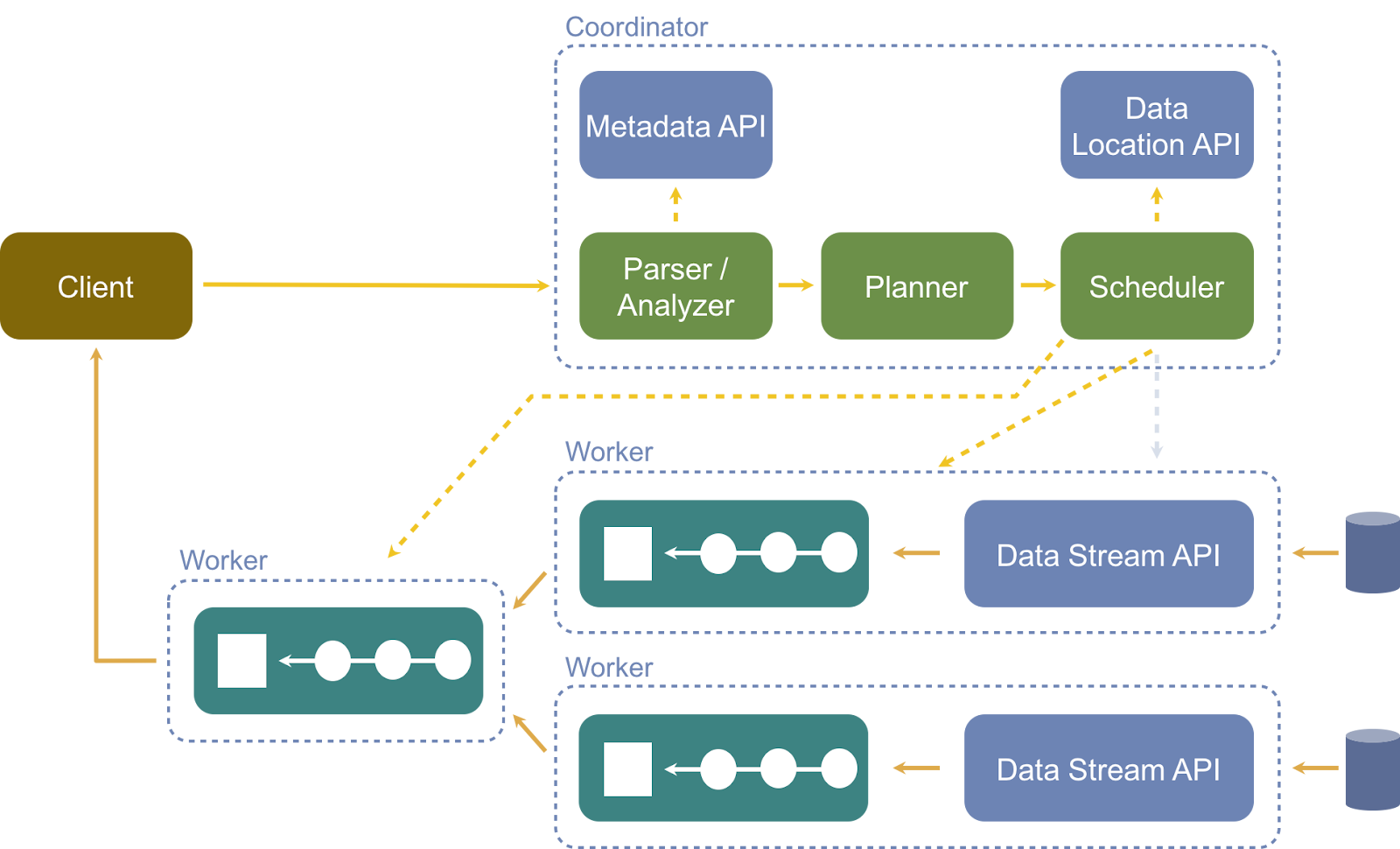
Introduction
Dans mon article précédent, j'ai présenté le module IRIStool, qui intègre de manière transparente la bibliothèque pandas pour Python à la base de données IRIS. Je vais maintenant vous expliquer comment utiliser IRIStool pour exploiter InterSystems IRIS comme base pour une recherche sémantique intelligente dans les données de soins de santé au format FHIR.
Cet article décrit ce que j'ai fait pour créer une base de données pour mon autre projet, FHIR Data Explorer. Les deux projets sont candidats au concours InterSystems actuel, alors n'hésitez pas à voter pour eux si vous les trouvez utiles.
Ils sont disponibles sur Open Exchange:
Dans cet article, nous aborderons les sujets suivants:
- Connexion à la base de données InterSystems IRIS via Python
- Création d'un schéma de base de données compatible FHIR
- Importation de données FHIR au moyen d'intégrations vectorielles pour la recherche sémantique
Conditions préalables
Installez IRIStool à partir de la page Github IRIStool et Data Manager.
1. Configuration de la connexion IRIS
Commencez par configurer votre connexion à l'aide des variables d'environnement dans un fichier .env:
IRIS_HOST=localhost
IRIS_PORT=9092
IRIS_NAMESPACE=USER
IRIS_USER=_SYSTEM
IRIS_PASSWORD=SYSConnectez-vous à IRIS à l'aide du gestionnaire de contexte du module IRIStool:
from utils.iristool import IRIStool
import os
from dotenv import load_dotenv
load_dotenv()
with IRIStool(
host=os.getenv('IRIS_HOST'),
port=os.getenv('IRIS_PORT'),
namespace=os.getenv('IRIS_NAMESPACE'),
username=os.getenv('IRIS_USER'),
password=os.getenv('IRIS_PASSWORD')
) as iris:
# IRIStool manages the connection automatically
pass
2. Création du schéma FHIR
Commencez par créer une table pour stocker les données FHIR, puis, tout en extrayant les données des paquets FHIR, créez des tables avec des capacités de recherche vectorielle pour chacune des ressources FHIR extraites (comme Patient, Osservability, etc.).
Le module IRIStool simplifie la création de tables et d'index!
Table de référentiel FHIR
# Créer une table de référentiel principal pour les paquets FHIR brutsifnot iris.table_exists("FHIRrepository", "SQLUser"):
iris.create_table(
table_name="FHIRrepository",
columns={
"patient_id": "VARCHAR(200)",
"fhir_bundle": "CLOB"
}
)
iris.quick_create_index(
table_name="FHIRrepository",
column_name="patient_id"
)Table de patients avec support vectoriel
# Création d'une table de patients au moyen de la colonne vectorielle pour la recherche sémantiqueifnot iris.table_exists("Patient", "SQLUser"):
iris.create_table(
table_name="Patient",
columns={
"patient_row_id": "INT AUTO_INCREMENT PRIMARY KEY",
"patient_id": "VARCHAR(200)",
"description": "CLOB",
"description_vector": "VECTOR(FLOAT, 384)",
"full_name": "VARCHAR(200)",
"gender": "VARCHAR(30)",
"age": "INTEGER",
"birthdate": "TIMESTAMP"
}
)
<span class="hljs-comment"># Création d'index standards</span>
iris.quick_create_index(table_name=<span class="hljs-string">"Patient"</span>, column_name=<span class="hljs-string">"patient_id"</span>)
iris.quick_create_index(table_name=<span class="hljs-string">"Patient"</span>, column_name=<span class="hljs-string">"age"</span>)
<span class="hljs-comment"># Création d'un index vectoriel HNSW pour la recherche par similarité</span>
iris.create_hnsw_index(
index_name=<span class="hljs-string">"patient_vector_idx"</span>,
table_name=<span class="hljs-string">"Patient"</span>,
column_name=<span class="hljs-string">"description_vector"</span>,
distance=<span class="hljs-string">"Cosine"</span>
)</code></pre>
3. Importation de données FHIR à l'aide de vecteurs
Générez facilement des intégrations vectorielles à partir des descriptions des patients FHIR et insérez-les dans IRIS:
from sentence_transformers import SentenceTransformer
# Initialisation du modèle de convertisseur
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
# Exemple : Traitement des données du patient
patient_description = "45-year-old male with hypertension and type 2 diabetes"
patient_id = "patient-123"# Création d'un encodage vectoriel
vector = model.encode(patient_description, normalize_embeddings=True).tolist()
# Insertion des données du patient à l'aide du vecteur
iris.insert(
table_name="Patient",
patient_id=patient_id,
description=patient_description,
description_vector=str(vector),
full_name="John Doe",
gender="male",
age=45,
birthdate="1979-03-15"
)
4. Recherche sémantique
Lorsque vos données sont téléchargées, vous pouvez effectuer des recherches par similarité:
# Requête de recherche
search_text = "patients with diabetes"
query_vector = model.encode(search_text, normalize_embeddings=True).tolist()
# définition de requête SQL
query = f"""
SELECT TOP 5
patient_id,
full_name,
description,
VECTOR_COSINE(description_vector, TO_VECTOR(?)) as similarity
FROM Patient
ORDER BY similarity DESC
"""# définition des paramètres de requête
parameters = [str(query_vector)]
# Recherche de patients similaires à l'aide de la recherche vectorielle
results = iris.query(query, parameters)
# Impression des données du DataFrameifnot results.empty:
print(f"{results['full_name']}: {results['similarity']:.3f}")
Conclusion
- Le module IRIStool simplifie l'intégration d'IRIS avec des méthodes Python intuitives pour la création de tables et d'index
- IRIS prend en charge le stockage hybride SQL + vecteur de manière native, ce qui permet de réaliser les deux requêtes traditionnelles et la recherche sémantique
- Les intégrations vectorielles permettent une recherche intelligente dans les données de soins de santé FHIR à l'aide du langage naturel
- Les index HNSW fournissent une recherche par similarité efficace à grande échelle
Cette approche prouve qu'InterSystems IRIS peut servir de base solide pour créer des applications de santé intelligentes avec des capacités de recherche sémantique sur les données FHIR.


.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)