Introduction
Dans mon dernier article, j'ai présenté FHIR Data Explorer, une application de validation de concept qui connecte InterSystems IRIS, Python, et Ollama afin de permettre la recherche sémantique et la visualisation des données de soins de santé au format FHIR. Ce projet participe actuellement au concours InterSystems External Language Contest.
Dans cette suite, nous verrons comment j'ai intégré Ollama pour générer les résumés des dossiers médicaux directement à partir des données FHIR structurées stockées dans IRIS, à l'aide de modèles linguistiques locaux légers (LLM) tels que Llama 3.2:1B ou Gemma 2:2B.
L'objectif était de créer un pipeline d'IA entièrement local capable d'extraire, de formater et de présenter les dossiers médicaux des patients tout en garantissant la confidentialité et le contrôle total des données.
Toutes les données des patients utilisées dans cette démonstration proviennent de paquets FHIR, qui ont été analysés et chargés dans IRIS via le module IRIStool. Cette approche facilite la requête, la conversion et la vectorisation des données de soins de santé à l'aide d'opérations pandas familières en Python. Si vous désirez en savoir plus sur la manière dont j'ai construit cette intégration, consultez mon article précédent Création d'un référentiel vectoriel FHIR avec InterSystems IRIS et Python via le module IRIStool.
Les deux outils, IRIStool et FHIR Data Explorer sont disponibles sur InterSystems Open Exchange — et font partie de mes contributions au concours. Si vous les trouvez utiles, n'hésitez pas à voter pour eux!
1. Configuration avec Docker Compose
Pour simplifier la configuration et la rendre reproductible, tout fonctionne localement au moyen de Docker Compose.
Une configuration minimale se présente comme suit:
services:
iris:
container_name: iris-patient-search
build:
context: .
dockerfile: Dockerfile
image: iris-patient-search:latest
init: true
restart: unless-stopped
volumes:
- ./storage:/durable
ports:
- "9092:52773"# Management Portal / REST APIs
- "9091:1972"# SuperServer port
environment:
- ISC_DATA_DIRECTORY=/durable/iris
entrypoint: ["/opt/irisapp/entrypoint.sh"]
ollama:
image: ollama/ollama:latest
container_name: ollama
pull_policy: always
tty: true
restart: unless-stopped
ports:
- 11424:11434
volumes:
- ./ollama_entrypoint.sh:/entrypoint.sh
entrypoint: ["/entrypoint.sh"]Toutes les configurations sont disponibles sur la page du projet GitHub.
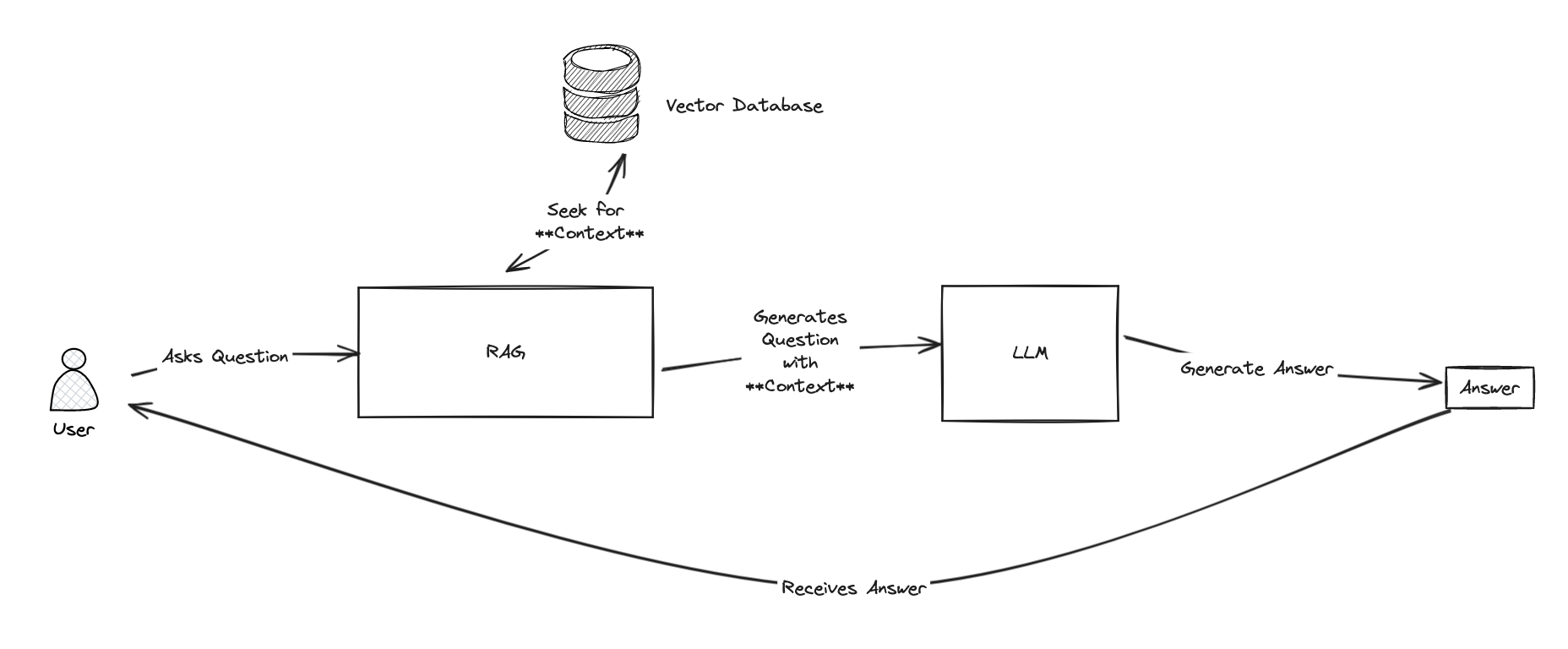
2. Intégration d'Ollama dans le flux de travail
Ollama fournit une API REST locale simple pour exécuter efficacement des modèles sur le processeur, ce qui le rend idéal pour les applications de santé où la confidentialité et les performances sont importantes.
Pour connecter IRIS et Streamlit à Ollama, j'ai implémenté une classe Python légère pour transmettre les réponses de l'API Ollama:
import requests, json
classollama_request:def__init__(self, api_url: str):
self.api_url = api_url
defget_response(self, content, model):
payload = {
"model": model,
"messages": [
{"role": "user", "content": content}
]
}
response = requests.post(self.api_url, json=payload, stream=True)
if response.status_code == 200:
for line in response.iter_lines(decode_unicode=True):
if line:
try:
json_data = json.loads(line)
if"message"in json_data and"content"in json_data["message"]:
yield json_data["message"]["content"]
except json.JSONDecodeError:
yieldf"Error decoding JSON line: {line}"else:
yieldf"Error: {response.status_code} - {response.text}"Cela permet de transmettre les résultats du modèle en temps réel, ce qui donne aux utilisateurs l'impression de “surveiller“ le travail de l'IA en direct dans l'interface utilisateur Streamlit.
3. Préparation des données du patient pour LLM
Avant d'envoyer quoi que ce soit à Ollama, les données doivent être compactes, structurées et pertinentes sur le plan clinique.
Pour cela, j'ai écrit une classe qui extrait et formate les données les plus pertinentes du patient (données démographiques, état de santé, observations, procédures, etc.) au format YAML, qui est à la fois compréhensible et compatible avec LLM.
Le processus simplifié est le suivant:
- Sélectionnez la chaîne du patient dans IRIS via pandas
- Extrayez les données démographiques et convertissez-les au format YAML
- Traitez chaque table médicale (conditions, observations, etc.)
- Supprimez les champs inutiles ou superflus
- Générez un document YAML concis utilisé comme contexte d'invite LLM.
Cette chaîne est ensuite transmise directement à l'invite LLM, formant le contexte structuré à partir duquel le modèle génère le compte rendu sommaire du patient.
4. Pourquoi limiter le nombre d'enregistrements?
Lors du développement de cette fonctionnalité, j'ai remarqué que la transmission de tous les dossiers médicaux provoquait souvent une confusion ou un biais dans les petits LLM envers les saisies plus anciennes, ce qui faisait perdre de vue les événements récents.
Pour résoudre ce problème, j'ai décidé:
- De n'inclure qu'un nombre limité d'enregistrements par catégorie dans l' ordre chronologique inverse (plus récents en premier)
- D'utiliser un format concis YAML au lieu du format brut JSON
- De normaliser les types de données (horodatages, valeurs nulles, etc.) pour plus de cohérence
Cette conception aide les petits LLM à se concentrer sur les données les plus pertinentes sur le plan clinique data en évitant la “surcharge d'invites”.
💬 4. Génération du dossier médical du patient
Une fois les données au format YAML prêtes, l'application Streamlit les envoie à Ollama au moyen d'une simple invite telle que:
“Vous êtes assistant clinique. À partir des données suivantes du patient, rédigez un dossier médical concis en soulignant les pathologies pertinentes et les tendances récentes.”
Le résultat est renvoyé ligne par ligne à l'interface utilisateur, ce qui permet à l'utilisateur de surveiller la rédaction du dossier en temps réel.
Chaque modèle produit un résultat légèrement différent, même au moyen de la même invite, révélant des différences fascinantes dans le raisonnement et le style.
🧠 5. Comparaison des LLM locaux
Pour évaluer l'efficacité de cette approche, j'ai testé trois modèles ouverts et légers, disponibles via Ollama:
| Modèle | Paramètres | Style de dossier | Remarques |
|---|---|---|---|
| Llama 3.2:1B | 1B | Structuré, factuel | Résultat hautement littéral et schématique |
| Gemma 2:2B | 2B | Narratif, à caractère humain | Le plus cohérent et le plus sensible au contexte |
| Gemma 3:1B | 1B | Concis, synthétique | Omettant parfois certains détails, mais très compréhensible |
Vous trouverez des exemples de résultats dans le dossier GitHub suivant. Chaque dossier du patient met en évidence la manière dont la taille du modèle et le style d'entraînement influencent la structure, la cohérence et le niveau de détail du texte.
Voici une interprétation comparative de leur comportement:
- Llama 3.2:1B reproduit généralement la structure des données mot pour mot, presque comme s'il effectuait une exportation de base de données. Ses résumés sont techniquement précis, mais ne sont pas fluides, ressemblant davantage à un rapport clinique structuré qu'à un texte naturel.
- Gemma 3:1B offre une meilleure fluidité linguistique, mais compresse ou omet des détails mineurs.
- Gemma 2:2B offre le meilleur équilibre. Il organise les informations en sections significatives (conditions, facteurs de risque, recommandations de soins) tout en conservant un ton fluide.
En bref:
- Llama 3.2:1B = précision factuelle
- Gemma 3:1B = dossiers médicaux concis
- Gemma 2:2B = narration cliniquement pertinente
Même sans ajustement, une curation des données et une conception des invites judicieuses permettent aux petits LLM locaux de produire des comptes rendus cliniques cohérents et pertinents dans leur contexte.
🔒 6. Pourquoi les modèles locaux sont-ils importants?
En utilisant Ollama localement, vous obtenez:
- Un contrôle total des données — les données du patient ne disparaissent jamais de l'environnement
- Des performances déterministes — une latence stable sur le processeur
- Un déploiement léger — fonctionne même sans processeur graphique
- Une conception modulaire — facile de passer d'un modèle à l'autre ou d'ajuster les invites
Cette configuration est donc idéale pour les hôpitaux, les centres de recherche ou les environnements universitaires qui souhaitent expérimenter en toute sécurité la documentation et la synthèse basées sur l'IA.
🧭 Conclusion
Cette intégration démontre que même les petits modèles locaux, lorsqu'ils sont correctement guidés par des données structurées et des invites claires, peuvent produire des dossiers médicaux utiles et proches de ceux rédigés par des humains.
Au moyen d'IRIS pour la gestion des données, Python pour convertir les données et Ollama pour la génération de texte, nous obtenons un pipeline IA entièrement local et axé sur la confidentialité pour la génération de renseignements cliniques.
.jpg)
.png)
.png)
.png)
.png)
.png)




.png)
.png)
.png)
.png)
.png)
.png)

.png)
.jpg)







.png)
