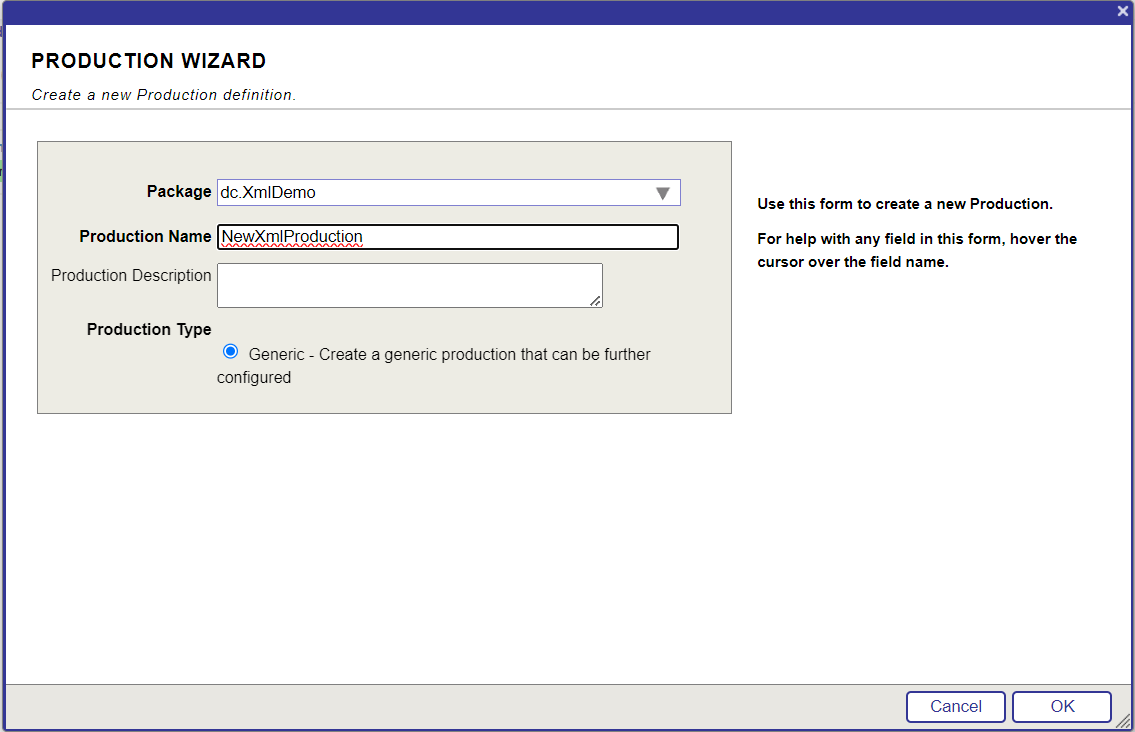
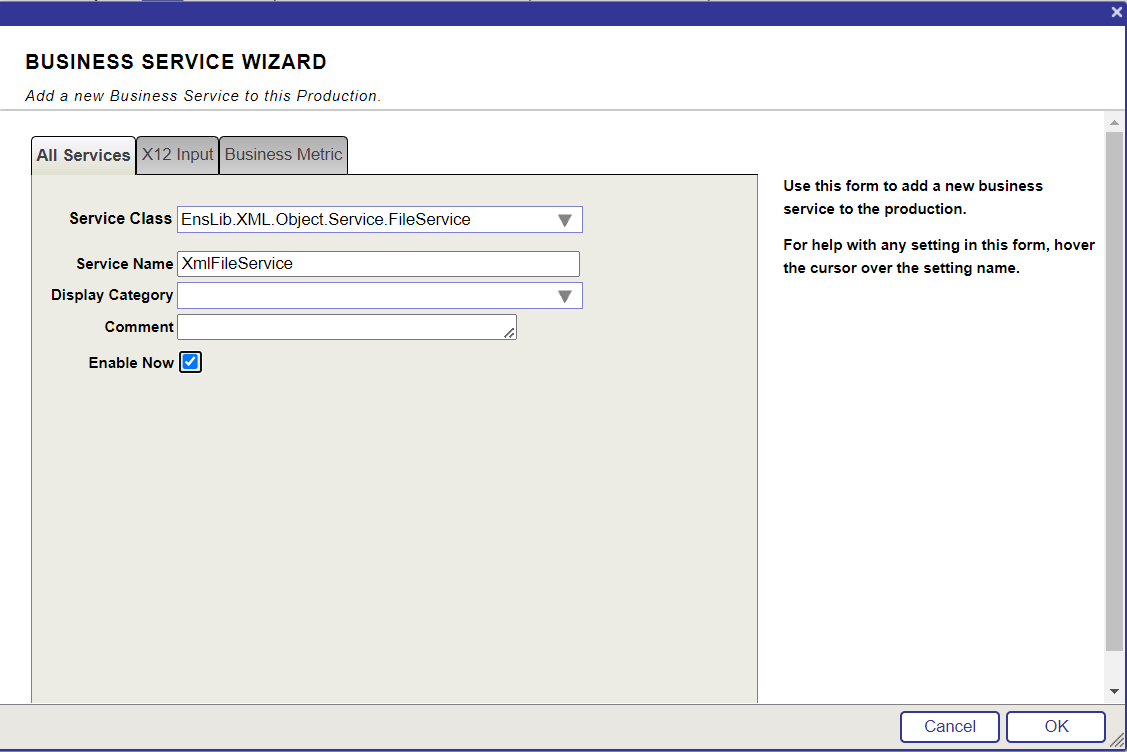
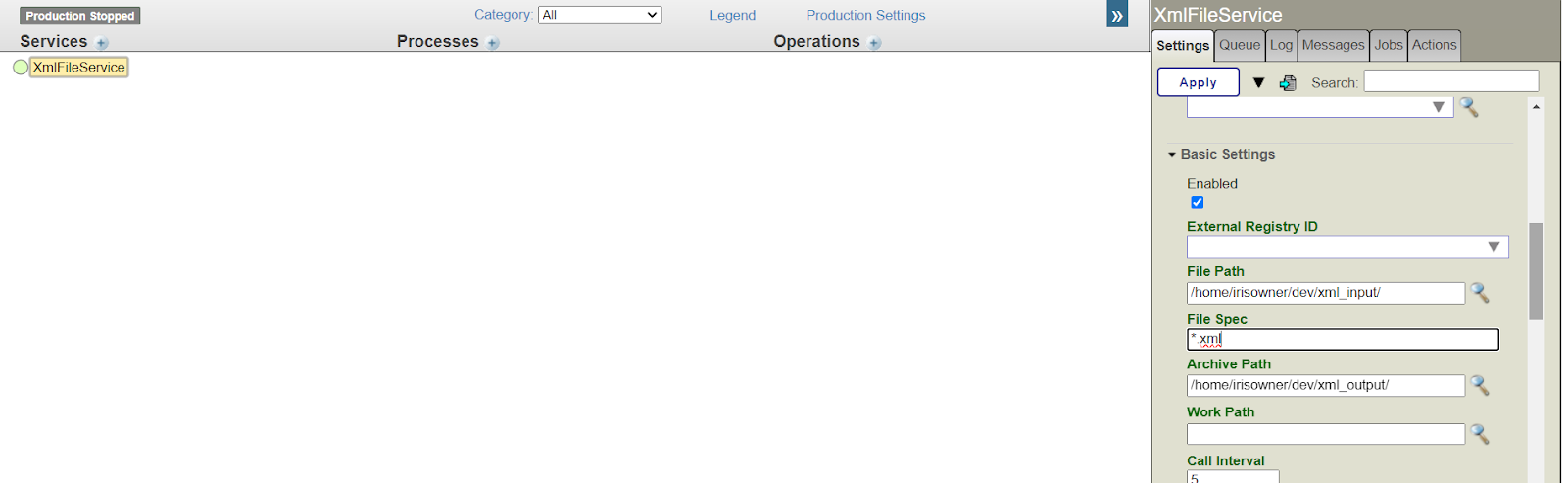
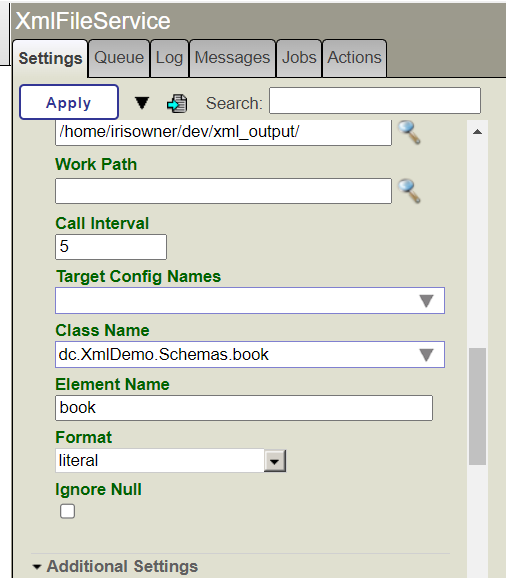
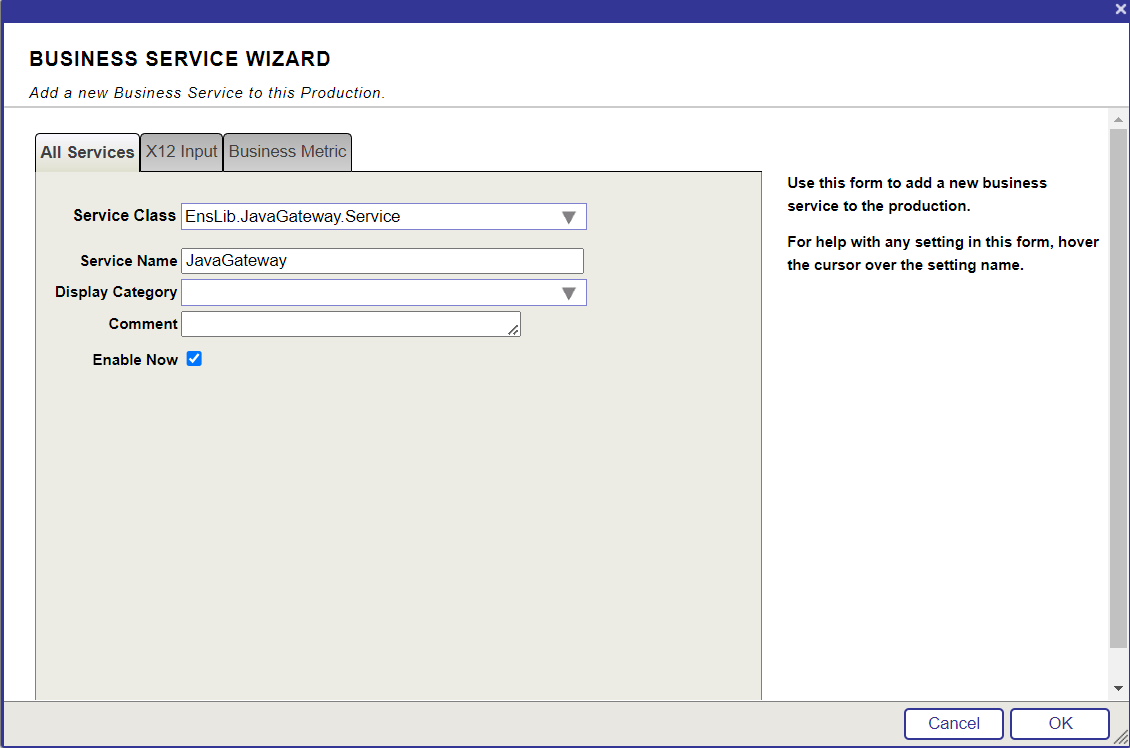
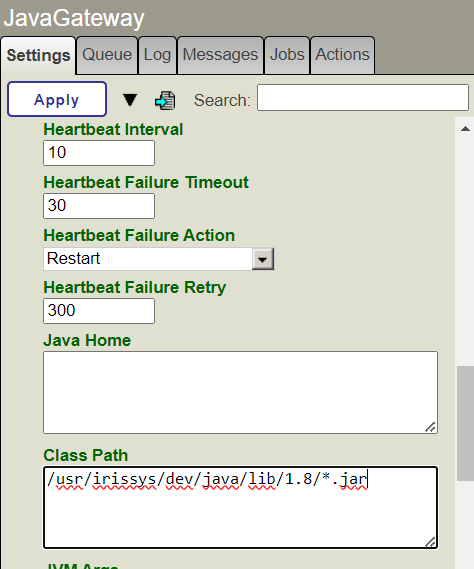
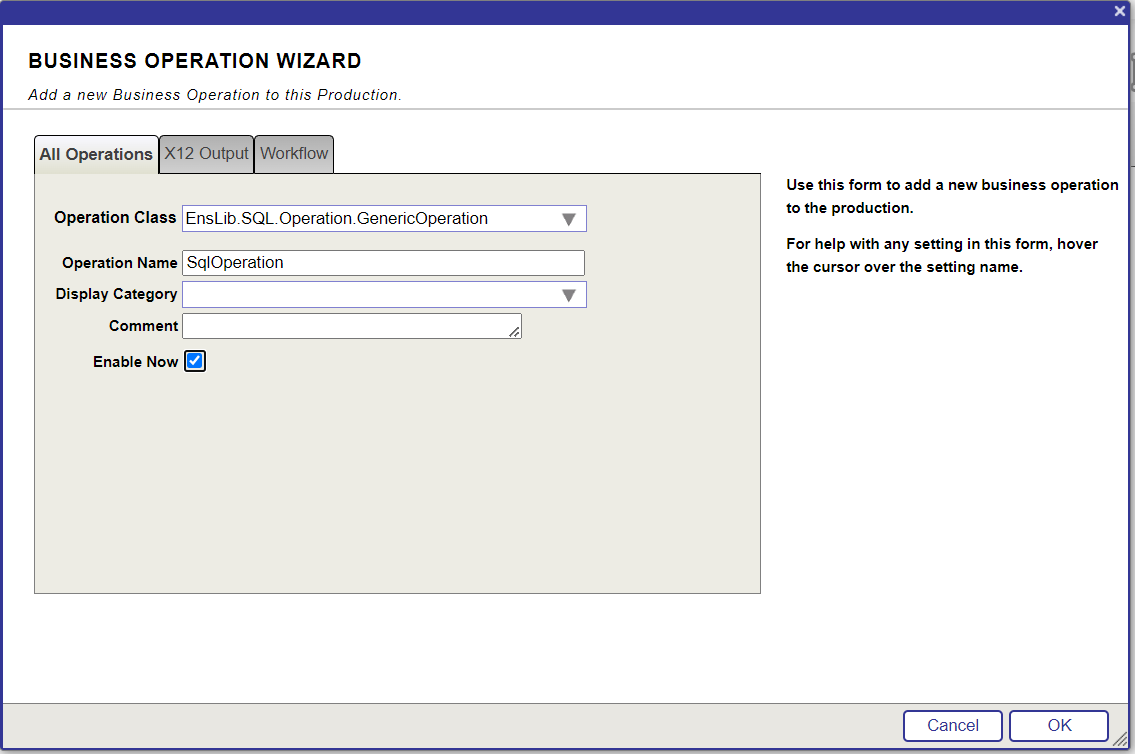
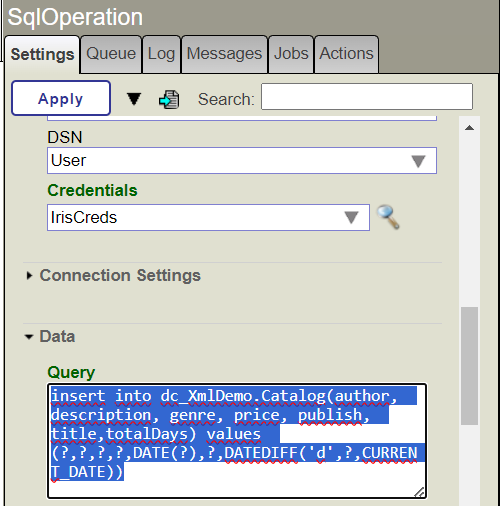
Le défi du Lo-Code
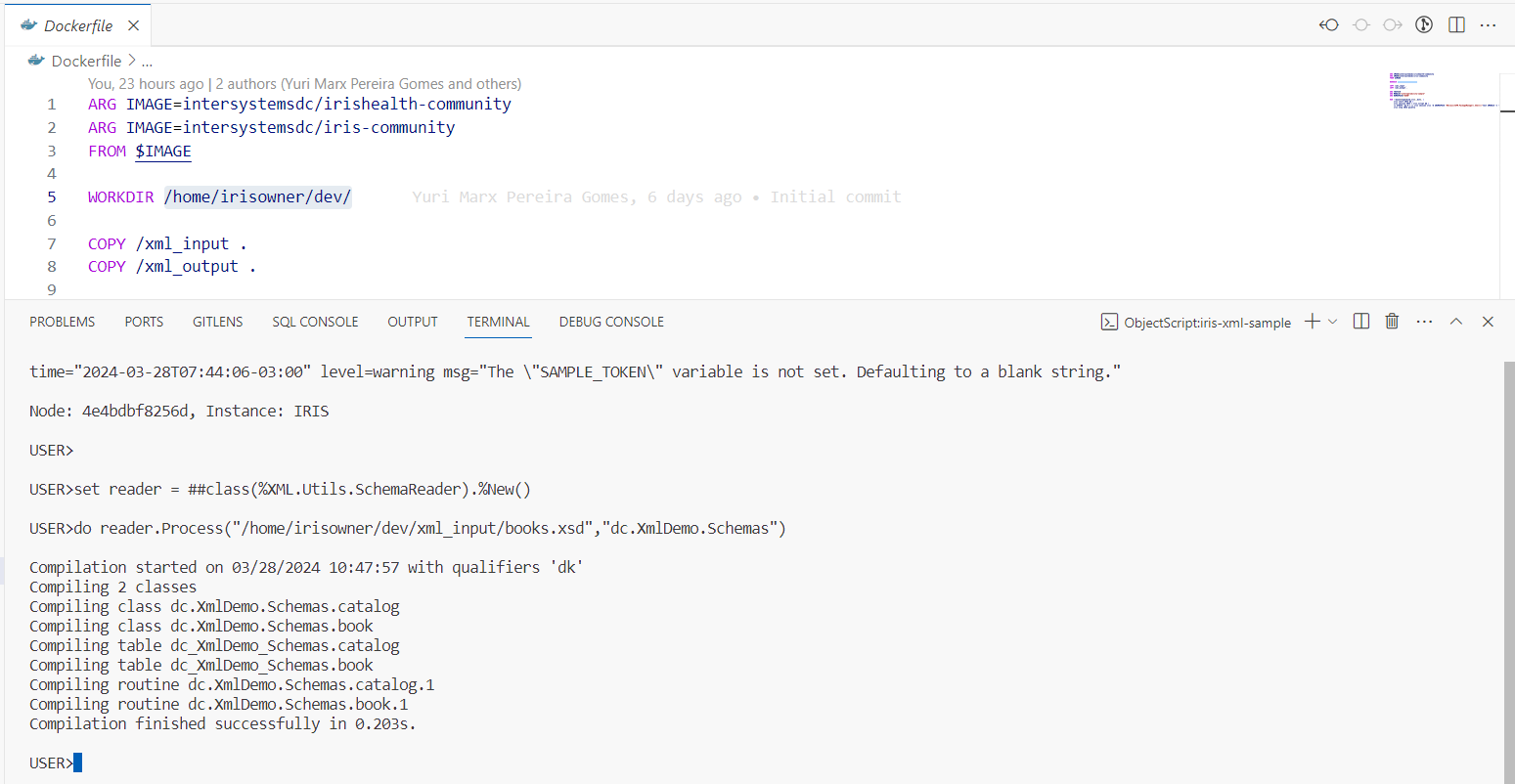
Imaginons la scène. Vous travaillez tranquillement au sein de Widgets Direct, le premier détaillant de Widgets et d'accessoires pour Widgets sur Internet. Votre patron vous annonce une nouvelle désastreuse : certains clients ne sont peut-être pas satisfaits de leurs widgets et nous avons besoin d'une application d'assistance pour assurer le suivi de ces réclamations. Pour rendre les choses plus intéressantes, il veut que cette application ait une très faible empreinte de code et vous demande de livrer une application en moins de 150 lignes de code à l'aide d'InterSystems IRIS. Est-ce possible?
Avertissement : cet article présente la construction d'une application très basique et omet, par souci de concision, des éléments de détail tels que la Sécurité et la Gestion des erreurs. Cette application ne doit être utilisée qu'à titre de référence ni pour une application de production. Cet article utilise IRIS 2023.1 comme plate-forme de données, certaines fonctionnalités décrites ne sont pas disponibles dans les versions antérieures
Étape 1 – Définition d'un modèle de données
Nous commençons par définir un nouvel espace de noms propre - avec une base de données de codes et de données. Bien que tout soit regroupé dans une seule base de données, il est utile de diviser ces bases pour permettre l'actualisation des données.
.png)
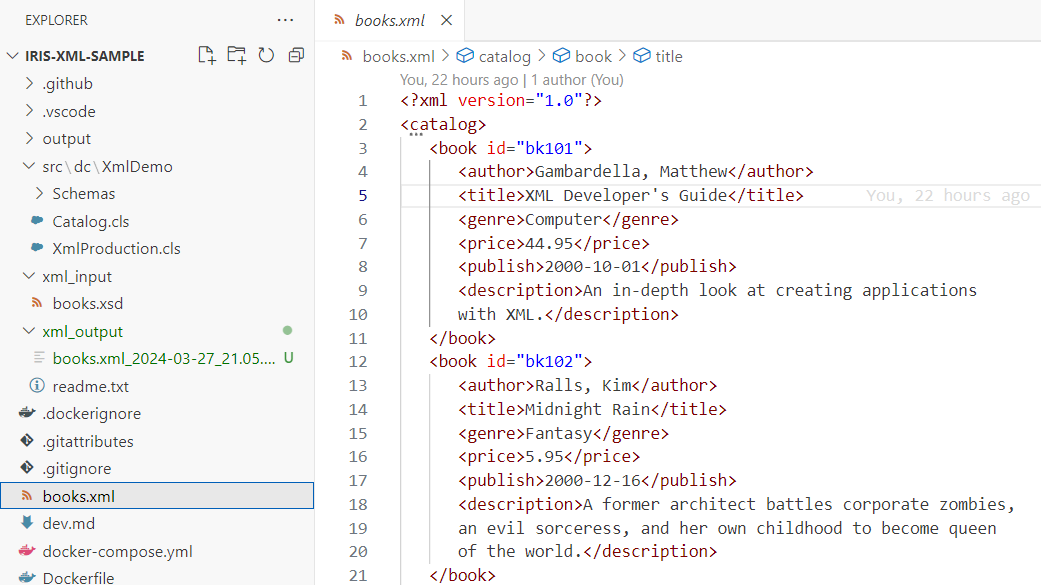
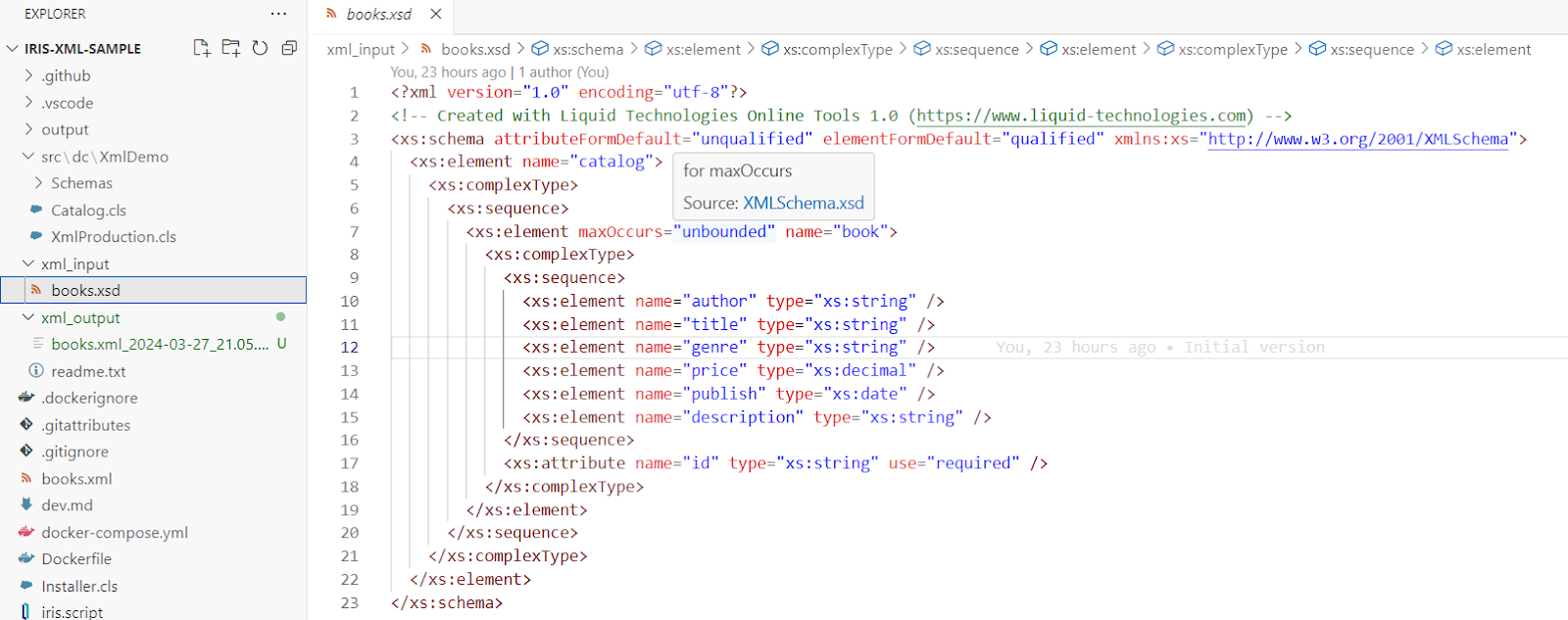
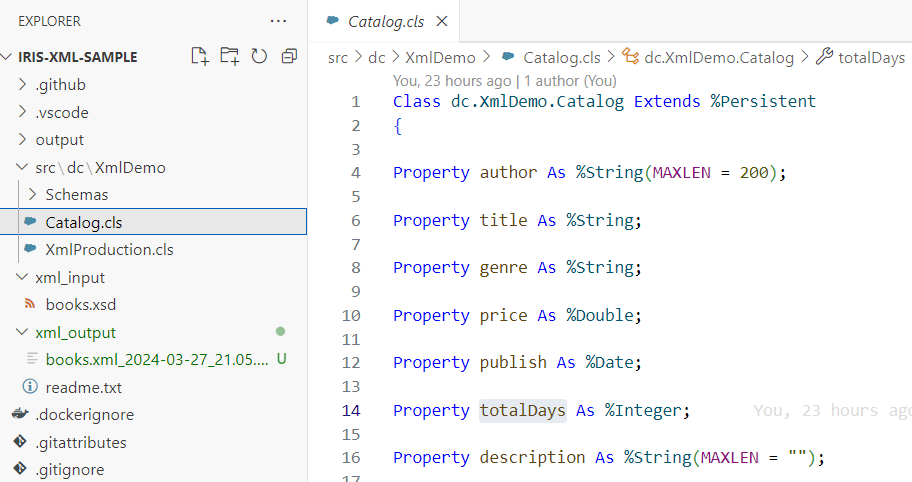
Notre système d'assistance a besoin de 3 classes de base : un objet Ticket qui peut contenir des actions pour documenter les interactions entre un conseiller du personnel UserAccount et un contact client UserAccount. Définissons ces classes avec quelques propriétés de base:
.png)
.png)
.png)
19 lignes de code – et nous avons notre modèle de données complet! Nous avons défini 2 classes comme Persistent afin qu'elles puissent être sauvegardées dans la base de données, et nous héritons également de %JSON.Adapter, ce qui nous permet d'importer et d'exporter très facilement nos objets au format JSON. En guise de test, nous configurons notre premier utilisateur dans Terminal, nous le sauvegardons et nous vérifions que l'application JSONExport fonctionne correctement
.png)
Tout cela semble bon. Le patron nous a laissé un fichier csv avec une liste d'employés et de clients. Nous pourrions écrire un code pour analyser ce fichier et le charger, mais y a-t-il un moyen plus simple?
Étape 2 – TÉLÉCHARGEMENT DES DONNÉES
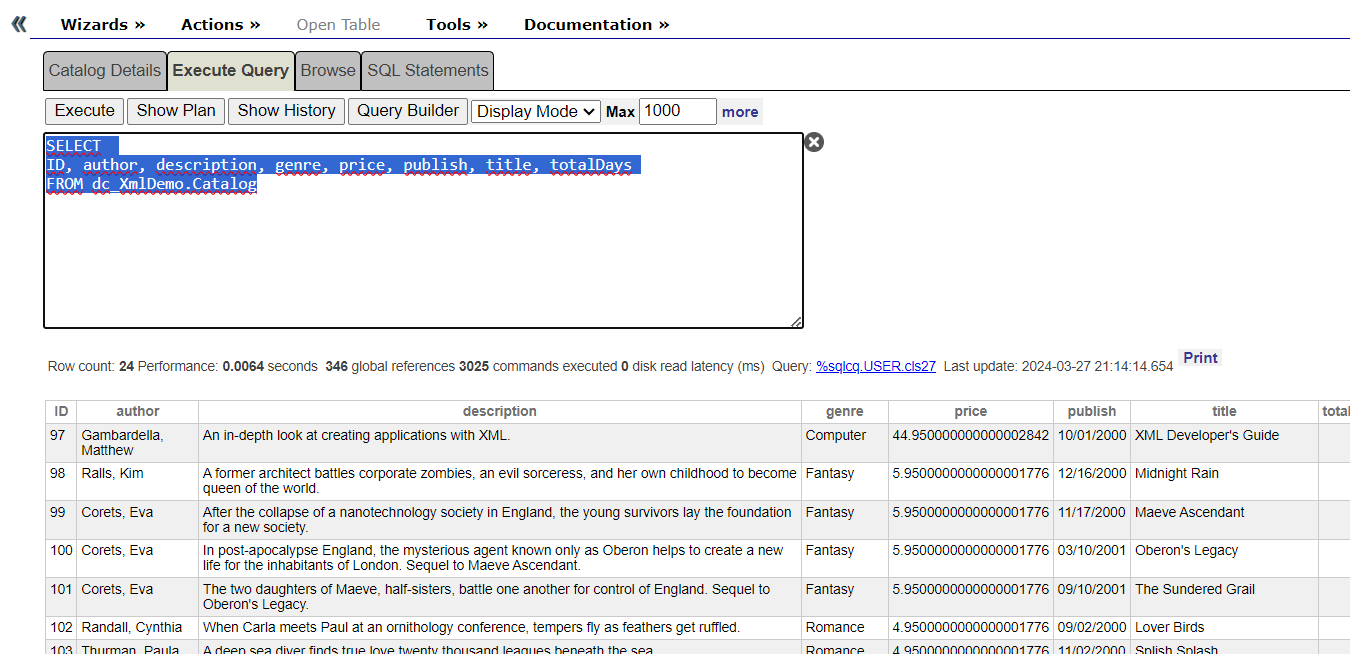
InterSystems IRIS fournit une instruction de chargement de données (LOAD DATA) simple à utiliser en SQL qui permet de télécharger facilement des données à partir d'un fichier CSV, y compris les options permettant d'analyser les en-têtes et de renommer les champs. Utilisons-la pour télécharger notre table d'utilisateurs:
.png)
Nous pouvons utiliser les étiquettes d'en-tête pour extraire ces données et les télécharger dans la base de données de la manière suivante:
.png)
Les 300 lignes ont été importées en une seule commande. Les 4 lignes supplémentaires de code portent notre compte courant à 23 lignes de code écrites. Nous pouvons rapidement vérifier que ces enregistrements sont corrects avec une sélection SQL de base
.png)
Nous avons maintenant nos données de départ, construisons donc quelques API de base pour permettre à un front-end d'être connecté. Nous construirons notre API comme un service REST qui sert et accepte JSON.
Étape 3 – Création d'une API REST
InterSystems IRIS fournit un support REST natif par le biais de l'héritage de la classe %CSP.REST, nous allons donc créer une classe REST.Dispatch et hériter de %CSP.REST. Cette classe est composée de deux sections: une UrlMap XData qui associe les URL et les Verbes aux méthodes, et les méthodes qui sont appelées par ces Urls.
Notre Produit minimum viable nécessite 4 opérations: la récupération de la liste des utilisateurs pour le personnel ou les clients, la récupération des derniers tickets collectés, la récupération d'un ticket unique par son numéro d'identification, et enfin la création d'un nouveau ticket. Nous définissons nos verbes, et puis les méthodes.
.png)
GetUserList est un Curseur de base SQL intégré qui fournit les données directement en JSON. Nous pouvons alors analyser ces données avec la fonctionnalité JSON native, les placer dans un tableau JSON et les servir en tant que corps de la réponse. Nous passons la variable "staff" de l'URL directement à la requête pour modifier le contexte des données.
.png)
TicketSummary est presque identique, mais la requête accède alors à la table des tickets
.png)
TicketSummary est le service le plus simple. Nous ouvrons l'objet par ID, et écrivons le %JSONExport intégré à la sortie. Si l'objet ne se charge pas, alors nous écrivons un paquet d'erreurs
.png)
Enfin, notre méthode d'UploadTicket est la plus complexe. Nous devons lire le payload de l'objet de la requête, l'analyser en JSON, puis l'appliquer à une nouvelle instance de Ticket en utilisant %JSONImport. Nous définissons également l'OpenDate et l'OpenTime à partir de l'heure actuelle, au lieu de les attendre en entrée. Après une sauvegarde réussie, nous renvoyons la représentation JSON de l'objet, ou si l'objet ne se télécharge pas, nous renvoyons une erreur.
.png)
Avec ces services, nous ajoutons 60 lignes de code supplémentaires à notre total. Nous atteignons maintenant un total de 89 lignes de code pour cette application
Nous devons maintenant créer une application Web sous Sécurité>Applications. Celle-ci doit être définie comme une application de type REST, et le NOMCLASSE (Classname) doit être défini comme la classe de répartition (Dispatch) que nous venons de créer (Remarque: vous devrez accorder un rôle de sécurité approprié à cette application afin qu'elle puisse accéder au code et aux données). Après avoir sauvegardé, les services REST peuvent maintenant être appelés à partir de l'URL que vous avez définie
.png)
Nous pouvons appeler l'UserList pour vérifier
.png)
Nous sommes maintenant prêts à créer des données. Utilisons notre client REST pour envoyer un payload au service de création de tickets. Nous fournissons un mot-clé, une description, un conseiller (Advisor) et un contact (Contact), et nous recevons en retour le fichier JSON du ticket que nous avons créé, y compris l'OpenDate et le TicketId
.png)
.png)
Nous avons maintenant notre Produit minimum viable. En utilisant un constructeur de formulaire frontal de notre choix, nous pouvons maintenant envoyer et recevoir des informations sur les tickets via nos services REST.
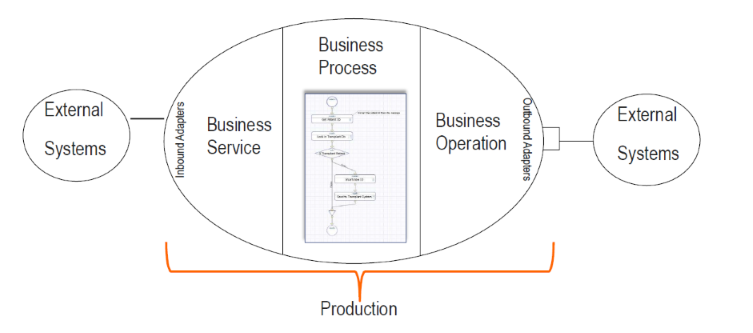
Étape 4 – Exigences d'interopérabilité
Vous avez maintenant construit une application de ticketing de base en seulement 89 lignes de code écrites. Votre patron doit être impressionné? Oui, mais il a de mauvaises nouvelles. Vous avez oublié une exigence. Widgets Direct a un contrat spécial avec les régions francophones et tous les billets rédigés en français doivent être envoyés à Mme Bettie Francis pour un premier examen. Heureusement, vous avez un collègue qui a suivi l'excellent article de Robert Luman "Sur la prise en charge du langage naturel par Python" ("Python Natural Language Support") et qui a créé un service REST capable d'accepter un échantillon de texte et d'en identifier la langue. Pouvons-nous utiliser l'Interopérabilité d'InterSystems IRIS pour appeler ce service et mettre automatiquement à jour le conseiller de Mme Francis lorsque le texte est en français?
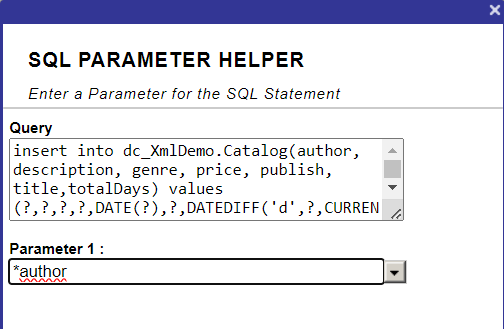
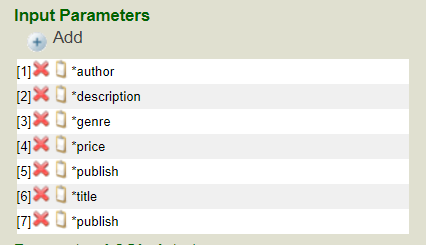
Nous devons commencer par la création de Classes de messages afin d'avoir un moyen d'envoyer et de recevoir nos demandes. Nous avons besoin d'une requête qui contiendra l'identifiant du ticket et le texte de l'échantillon, et d'une réponse qui renverra le Code de la langue et la Description. Ceux-ci hériteront d' Ens. Request et d'Ens. Response
.png)
.png)
6 autres lignes de code écrites nous permettent d'atteindre 95 LOC. Nous devons maintenant créer notre opération, qui enverra la requête au service de votre collègue et récupérera la réponse. Nous définissons une opération Outbound, avec des propriétés pour le serveur et l'URL, et nous les exposons à la configuration de l'utilisateur en les incluant dans le paramètre SETTINGS. Cela nous permettra de mettre facilement à jour la requête si le chemin d'accès au serveur change. Nous créons une méthode d'aide pour configurer une requête HTTPRequest, puis nous l'utilisons pour appeler le service et remplir notre réponse
.png)
.png)
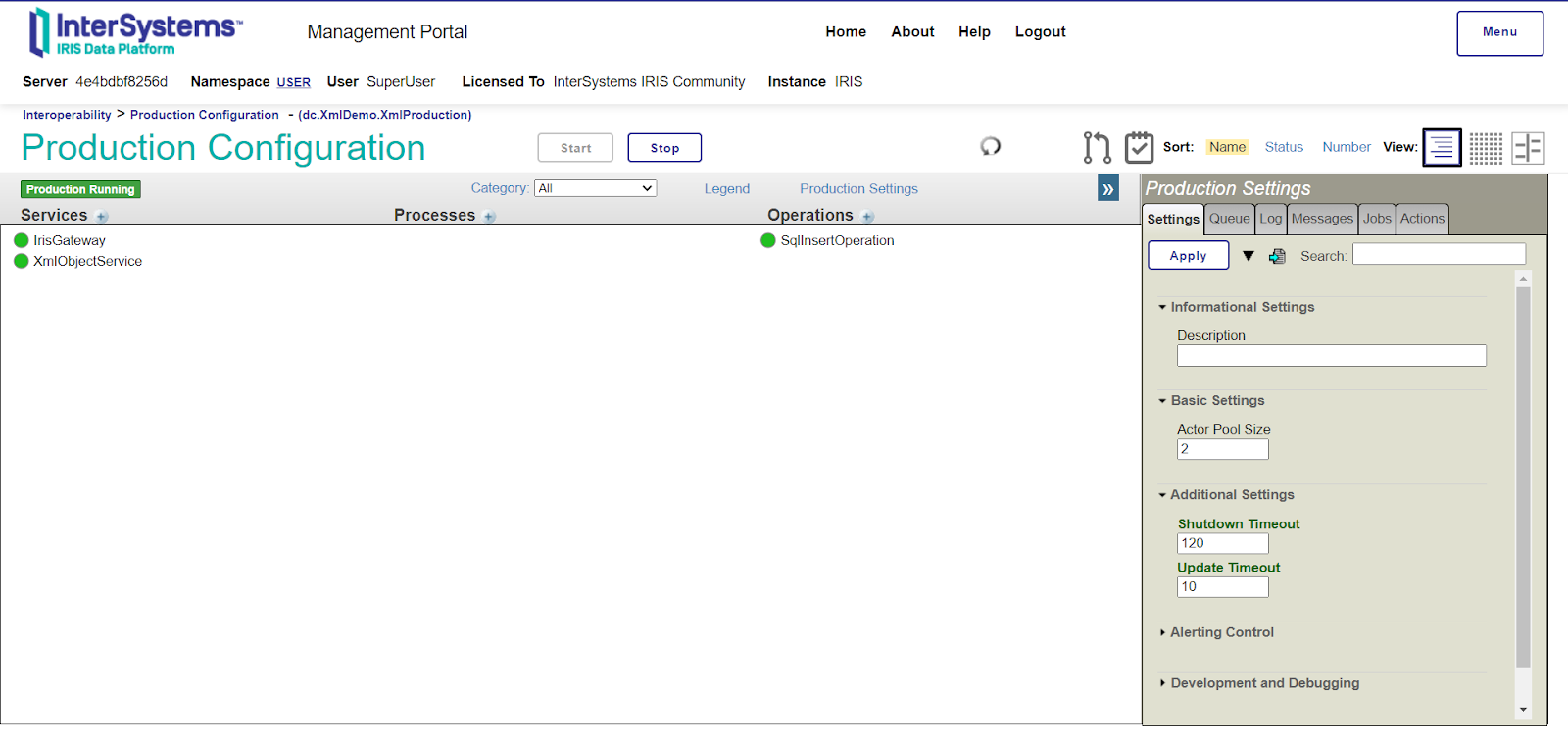
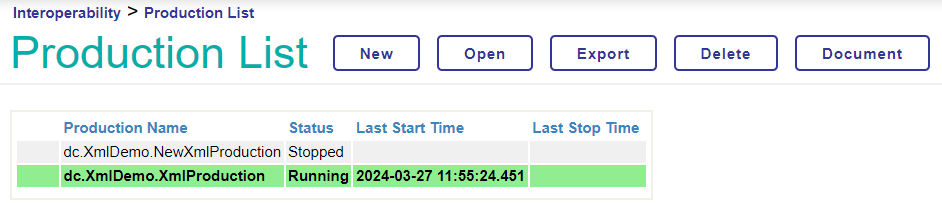
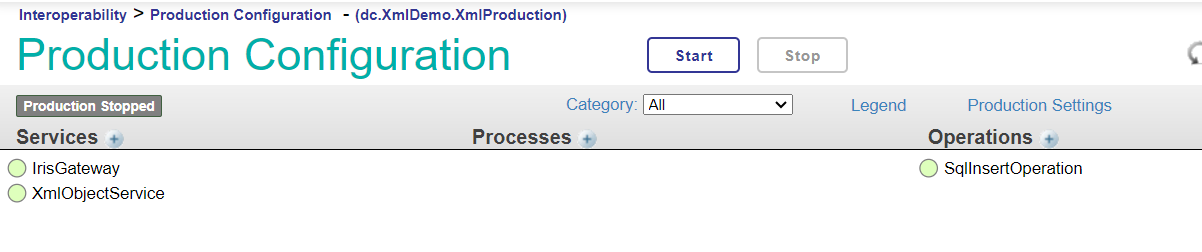
27 lignes de code supplémentaires nous amènent à plus de 100, nous avons maintenant 122 lignes écrites. Nous devons maintenant configurer cette classe dans notre production Ensemble. Nous devons maintenant configurer cette classe dans notre production Ensemble. Accédez à la configuration de la production sous Interopérabilité, et cliquez sur Ajouter (Add) sous l'En-tête Opérations (Operations Header). Configurez votre opération avec le nom de la classe et un nom d'affichage
.png)
Nous pouvons ensuite cliquer dessus pour accéder aux paramètres (Settings), entrer le nom du serveur et l'URL et activer l'Opération.
.png)
Nous avons maintenant besoin d'une deuxième opération qui prend l'identifiant d'un ticket et associe le conseiller à l'identifiant d'un compte d'utilisateur fourni. Nous avons besoin à la fois d'un message et d'une classe d'opération, mais dans ce cas, nous ne renverrons pas de réponse, l'opération exécutera la tâche sans feedback
.png)
Les 12 lignes de code supplémentaires nous amènent à 134 lignes écrites. Nous pouvons ajouter cette Opération à la Production de la même manière que nous avons ajouté le Service linguistique (Language Service), mais dans ce cas, nous n'avons pas de configuration à définir.
Nous avons ensuite besoin d'un routeur capable d'appeler le service, d'évaluer la réponse et, éventuellement, d'appeler l'Opération du conseiller français (French Advisor Operation). Nous allons vers Interoperability>Build>BusinessProcess et accédons à l'outil de création de règles visuelles. Nous définissons d'abord nos contextes pour la requête (Request) et la réponse (Response) et nous ajoutons un élément d'appel (Call). Nous définissons nos entrées et nos sorties sur les classes de messages que nous avons créées, puis nous mappons les entrées à l'aide du générateur de requêtes. Assurez-vous que l'option "Asynchrone" (Asynchronous) n'est pas cochée, car nous voulons attendre la réponse avant de continuer.
.png)
.png)
Nous ajoutons ensuite un élément "Si" (If) pour évaluer le code de langue renvoyé. S'il s'agit de "fr", nous voulons faire appel à l'opération de FrenchAdvisor
.png)
Mme Francis est l'utilisateur ID 11, nous configurons donc notre objet d'appel (Call object) pour qu'il fournisse notre message AdvisorUpdate au service FrenchAdvisor, et nous utilisons le constructeur de requêtes pour transmettre le TicketID et une valeur fixe de 11 au paramètre Advisor
.png)
.png)
Nous pouvons maintenant l'ajouter à la Production en cliquant sur Ajouter (Add) sous l'en-tête Processus, en sélectionnant la classe et en lui donnant un nom d'affichage "FrenchRouter".
Nous avons maintenant notre routage en place. Nous avons juste besoin d'un service pour rechercher les nouveaux tickets et les envoyer au routeur pour traitement. Nous définissons une classe de service basée sur un adaptateur SQL de la manière suivante (en ajoutant 8 lignes de code supplémentaires à notre compte):
.png)
Nous l'ajoutons ensuite à notre production comme nous l'avons fait avec les objets Operation et Process. Nous devons configurer l'adaptateur SQL. Nous fournissons les détails de connexion via un DSN de type ODBC à la base de données locale, ainsi qu'une requête SQL de base que le Service utilisera pour interroger les tickets sur un minuteur défini dans le paramètre d'intervalle d'appel CallInterval. Cette requête est associée au paramètre Key Field Name qui définit la clé unique de la requête et empêche le renvoi d'enregistrements déjà envoyés
.png)
Avec ceci en place, nous avons maintenant une production complète qui va scanner les nouveaux tickets, passer le texte à un service externe pour analyser la langue, et éventuellement réinitialiser le conseiller en fonction de la réponse. Essayons cela! Nous commençons par envoyer une requête en anglais, qui nous est retournée sous la forme TicketId 70. Nous attendons une seconde, et accédons à cet enregistrement via le service GetTicket REST, ici le conseiller est inchangé par rapport à la requête originale
.png)
.png)
Répétons l'opération avec le texte en français (French Text)
.png)
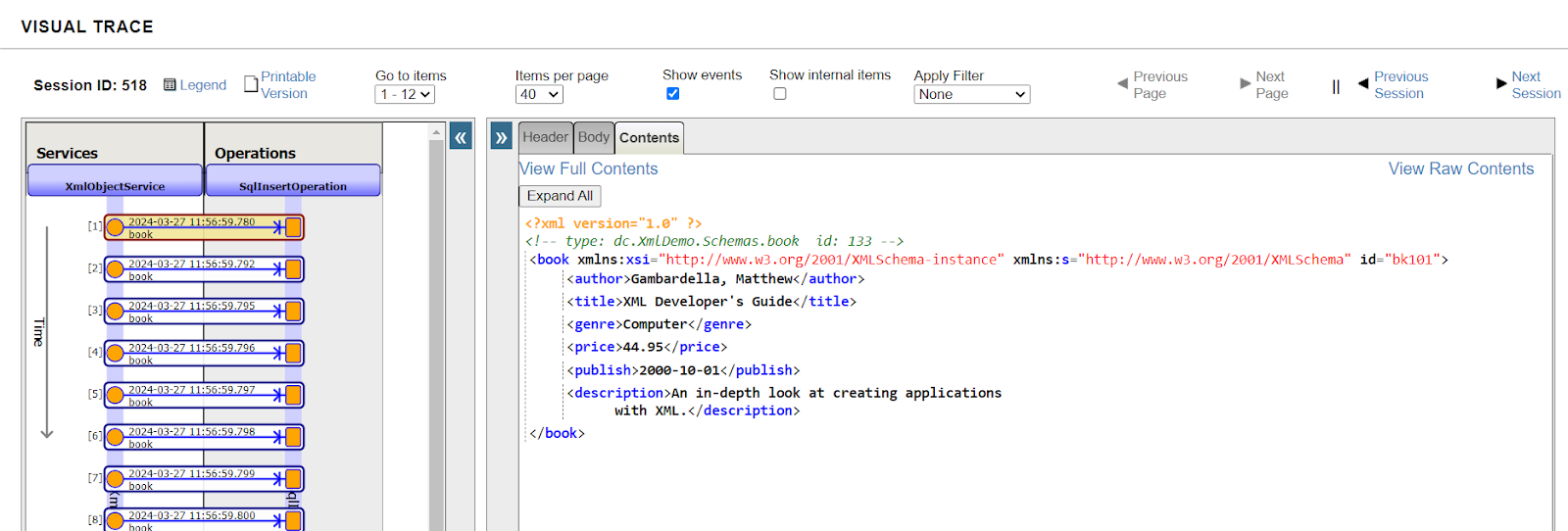
Lorsque nous réclamons le ticket 71, notre conseiller a été changé en Mme Francis, comme nous nous y attendions! Nous pouvons le vérifier dans l'Interoperability en localisant le message dans Visual Trace, et en vérifiant que les Opérations ont été appelées comme prévu.
.png)
.png)
Nous en sommes maintenant à 142 lignes de code écrites, et nous avons une application d'InterSystems IRIS qui persiste les données, les a chargées en utilisant LOAD DATA, fournit une API REST de base pour la visualisation et l'édition des données, et un moteur d'intégration avancé fournissant un Support de décision basé sur des appels à un service REST externe. Assurément, personne ne peut demander mieux?
Étape 5 – En savoir plus: Analyse
Votre application est un succès retentissant et les données affluent. L'accès à ces données précieuses nécessite une certaine expertise, et la direction de Widgets Direct souhaite obtenir des informations. Est-il possible de fournir un accès interactif aux données?
Grâce à InterSystems IRIS Analytics, nous pouvons fournir un accès facile et rapide à des outils de manipulation de données évolués. Nous devons d'abord activer le support Analytics sur notre application web interne:
.png)
Cela nous permet d'utiliser la section Analytics par rapport à notre Espace de noms. Commencez par ouvrir Analytics>Architect. Sélectionnez Nouveau (New) et remplissez le formulaire pour créer un Cube d'analyse pour la classe de tickets.
.png)
Ensuite, nous pouvons configurer nos dimensions et une liste déroulante Drilldown à l'aide du constructeur Visual Builder. Cette vue est accessible par glisser-déposer. Une liste peut également être créée à l'aide d'un constructeur visuel simple, afin de personnaliser ce que l'utilisateur voit lorsqu'il interroge un point de données
.png)
.png)
Une fois la configuration de base établie, nous pouvons Sauvegarder, Compiler et Construire le Cube. Cela permettra de configurer tous les indices et d'activer le Cube pour l'analyse dans le logiciel Analyzer. Ouvrez l'Analyzer pour commencer à jouer avec les données. Dans l'exemple présenté, nous pouvons facilement comparer les conseillers par rapport à une hiérarchie d'années et de trimestres filtrés par le contact en question. Une fois que vous avez cliqué sur une cellule, vous pouvez appuyer sur l'icône des jumelles pour appeler la liste Drilldown que vous avez créée en vue d'une analyse et d'une exportation plus approfondies
.png)
.png)
Conclusion
Avec seulement 142 lignes de code, nous disposons d'une application BackEnd moderne, simple mais fonctionnelle, avec des outils permettant la communication inter-applications et l'analyse avancée. Il s'agit d'une mise en œuvre simplifiée à l'extrême qui ne doit être utilisée que comme exemple des éléments de base nécessaires à la construction d'une application de base de données dans IRIS. Comme il a été mentionné au début de l'article, ce code n'est pas prêt pour la production et, dans le cadre d'une utilisation réelle, les développeurs doivent se référer à la documentation et aux meilleures pratiques d'InterSystems IRIS pour s'assurer que leur code est robuste, sécurisé et évolutif (aucune de ces caractéristiques ne s'applique à cette base de code). Bon codage!

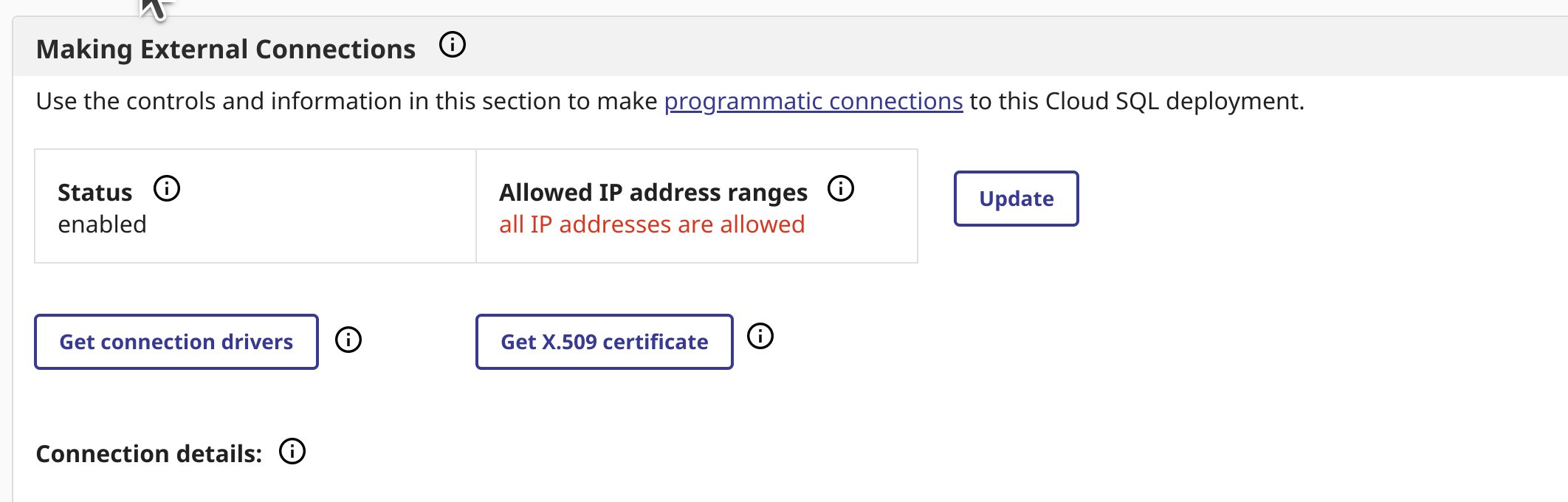







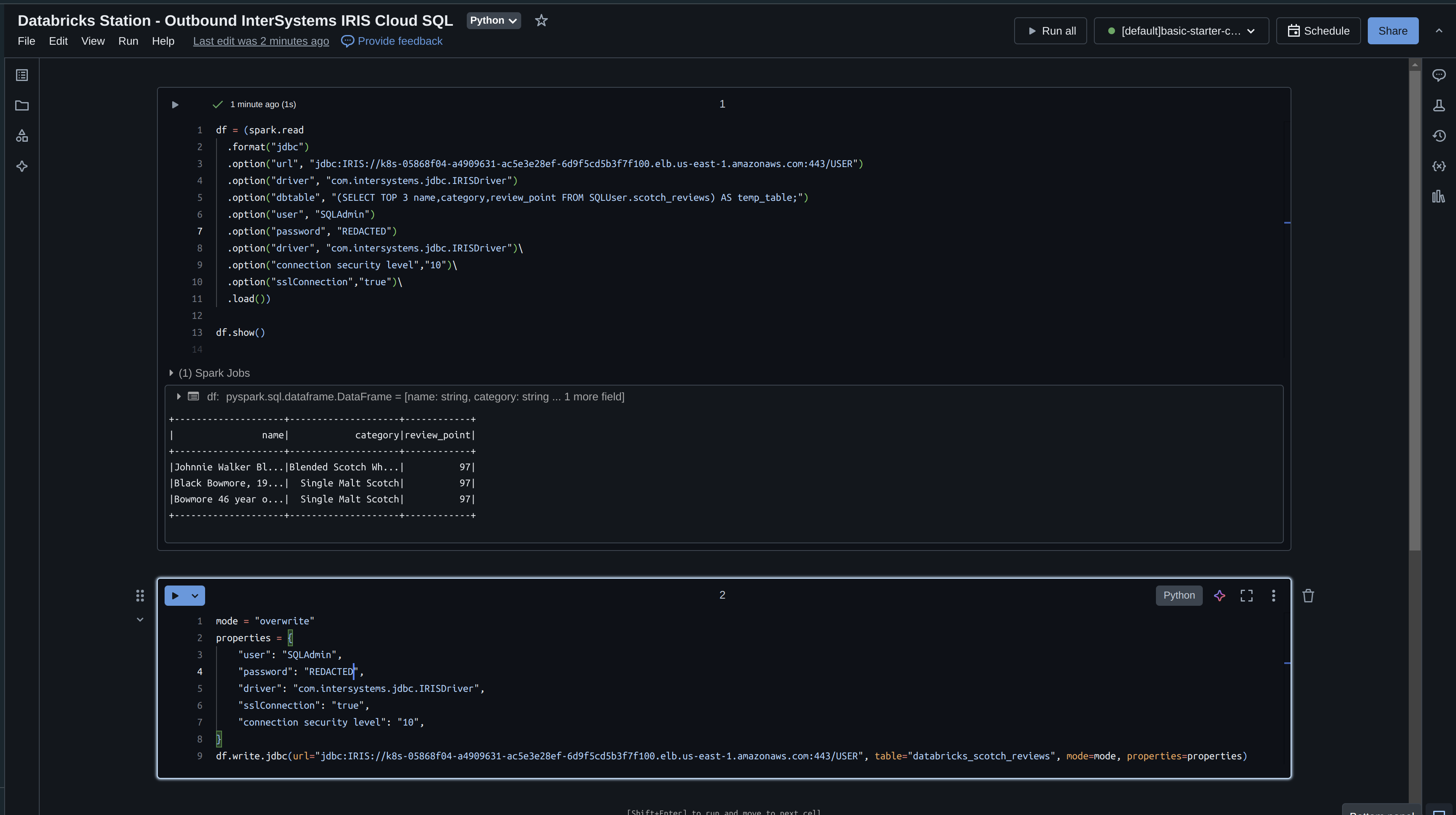

.png)

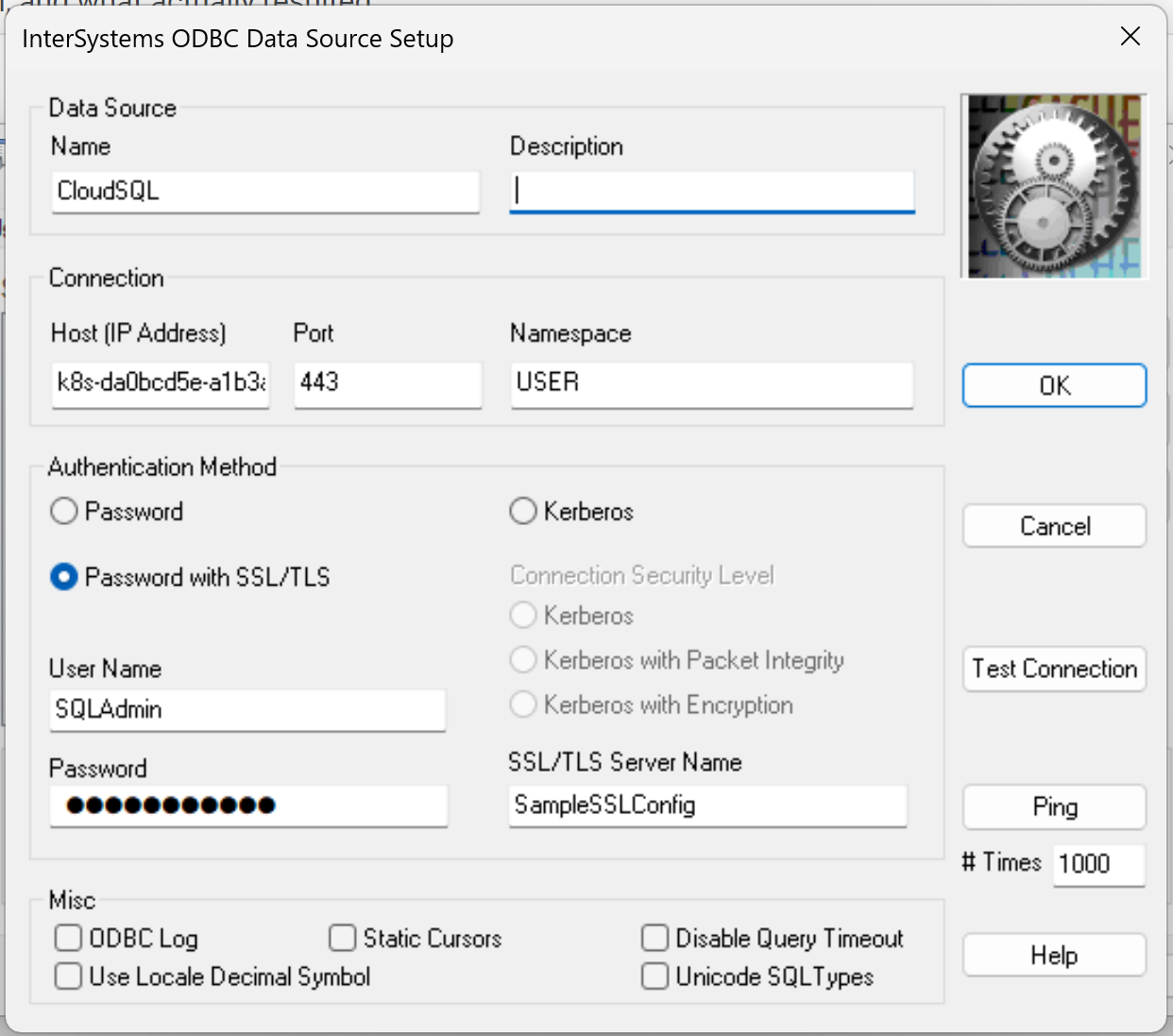 Ensuite, cliquez sur "Test Connection" (Tester la connexion) pour vérifier que tout fonctionne comme prévu. Vous devriez obtenir un message "Connectivity test completed successfully!" (Test de connectivité terminé avec succès). Si ce n'est pas le cas, vérifiez les étapes ci-dessus ou reportez-vous au
Ensuite, cliquez sur "Test Connection" (Tester la connexion) pour vérifier que tout fonctionne comme prévu. Vous devriez obtenir un message "Connectivity test completed successfully!" (Test de connectivité terminé avec succès). Si ce n'est pas le cas, vérifiez les étapes ci-dessus ou reportez-vous au .png)
.png)

.png)
.png)