Cela fait maintenant plus de 2 ans que j'utilise quotidiennement Embedded Python.
Il est peut-être temps de partager un retour d'expérience sur ce parcours.
Pourquoi écrire ce commentaire de retour d'expérience? Parce que, je suppose, je suis comme la plupart de mes collègues ici, un développeur ObjectScript, et je pense que la communauté bénéficierait de ce retour d'expérience et pourrait mieux comprendre les avantages et les inconvénients du choix de Embedded Python pour développer quelque chose dans IRIS. Et aussi éviter certains pièges.

Introduction
Je suis développeur depuis 2010, et j'ai travaillé avec ObjectScript depuis 2013.
Donc, c'est à peu près 10 ans d'expérience avec ObjectScript.
Depuis 2021, et la sortie de Embedded Python dans IRIS, je me suis lancé un défi :
- Apprendre Python
- Faire autant que possible tout ce qui est en Python.
Quand j'ai commencé ce parcours, je n'avais aucune idée de ce qu'était Python. J'ai donc commencé par les bases, et je continue d'apprendre chaque jour.
Débuter avec Python
L'avantage de Python est sa facilité d'apprentissage. C'est encore plus facile quand on connaît déjà ObjectScript.
Pourquoi ? Ils ont beaucoup de choses en commun.
| ObjectScript | Python |
|---|
| Non typé | Non typé |
| Langage de script | Langage de script |
| Orienté objet | Orienté objet |
| Interprété | Interprété |
| Intégration simple du C | Intégration simple du C |
Donc, si vous connaissez ObjectScript, vous en savez déjà beaucoup sur Python.
Mais il y a quelques différences, et certaines d'entre elles ne sont pas faciles à comprendre.
Python n'est pas ObjectScript
Mais il y a quelques différences, et certaines d'entre elles ne sont pas faciles à comprendre.
Pour moi il y a principalement 3 différences :
Pep8
Mais qu'est-ce que Pep8 ?
Il s'agit d'un ensemble de règles pour écrire du code Python.
pep8.org
Quelques-unes d'entre elles sont :
- convention de nommage
- noms de variables
- noms de classes
- indentation
- longueur de ligne
- etc.
Pourquoi est-ce important ?
Parce que c'est la façon d'écrire du code Python. Et si vous ne suivez pas ces règles, vous aurez du mal à lire le code écrit par d'autres personnes, et elles auront du mal à lire le vôtre.
En tant que développeurs ObjectScript, nous avons aussi quelques règles à suivre, mais elles ne sont pas aussi strictes que Pep8.
J'ai appris Pep8 à la dure.
Je voudrais vous raconter petite histoire, je suis ingénieur commercial chez InterSystems et je fais beaucoup de démonstrations. Et un jour, que je faisais une démo de Embedded Python à un client, et ce client était un développeur Python, la conversation a tourné court lorsqu'il a vu mon code. Il m'a dit que mon code n'était pas du tout Python (il avait raison), je codais en Python comme je codais en ObjectScript. Et à cause de cela, il m'a dit qu'il n'était plus intéressé par Embedded Python. J'ai été choqué, et j'ai décidé d'apprendre Python de la bonne manière.
Donc, si vous voulez apprendre Python, apprenez d'abord Pep8.
Modules
Les modules sont quelque chose que nous n'avons pas en ObjectScript.
Habituellement, dans les langages orientés objet, vous avez des classes et des paquetages. En Python, vous avez des classes, des paquetages et des modules.
Qu'est-ce qu'un module ?
C'est un fichier avec une extension .py. Et c'est la façon d'organiser votre code.
Vous n'avez pas compris? Moi non plus au début. Prenons un exemple.
Habituellement, quand on veut créer une classe en ObjectScript, on crée un fichier .cls, et on y met sa classe. Et si vous voulez créer une autre classe, vous créez un autre fichier .cls. Et si vous voulez créer un paquetage, vous créez un dossier et vous y placez vos fichiers .cls.
En Python, c'est la même chose, mais Python apporte la possibilité d'avoir plusieurs classes dans un seul fichier. Ce fichier s'appelle un module.
Pour information, c'est Pythonic quand il y a plusieurs classes dans un seul fichier.
Prévoyez donc comment vous allez organiser votre code, et comment vous allez nommer vos modules pour ne pas vous retrouver comme moi avec un tas de modules portant le même nom que vos classes.
Un mauvais exemple :
MyClass.py
class MyClass:
def __init__(self):
pass
def my_method(self):
pass
Pour instancier cette classe, vous allez faire :
import MyClass.MyClass # weird right ?
my_class = MyClass()
Bizarre, hein ?
Dunders
Les dunders sont des méthodes spéciales en Python. Elles sont appelées dunder parce qu'elles commencent et se terminent par un double soulignement.
Ce sont en quelque sorte nos méthodes % en ObjectScript.
Elles sont utilisées pour ce qui suit :
- constructeur
- surcharge d'opérateur
- représentation d'objet
- etc.
Exemple :
class MyClass:
def __init__(self):
pass
def __repr__(self):
return "MyClass"
def __add__(self, other):
return self + other
Ici, nous avons 3 méthodes de dunder :
__init__ : constructeur__repr__ : représentation d'objet__add__ : surcharge d'opérateur
Les méthodes Dunders sont partout en Python. C'est une partie importante de la langue, mais ne vous inquiétez pas, vous les apprendrez rapidement.
Conclusion
Python n'est pas ObjectScript, et vous devrez l'apprendre. Mais ce n'est pas si difficile, et vous l'apprendrez rapidement.
Gardez simplement à l'esprit qu'il vous faudra apprendre Pep8, et comment organiser votre code avec des modules et des méthodes dunder.
De bons sites pour apprendre Python :
Embedded Python
Maintenant que vous en savez un peu plus sur Python, parlons de Embedded Python.
Qu'est-ce que Embedded Python ?
Embedded Python est un moyen d'exécuter du code Python dans IRIS. C'est une nouvelle fonctionnalité d' IRIS 2021.2+.
Cela signifie que votre code Python sera exécuté dans le même processus qu'IRIS.
Par ailleurs, chaque classe ObjectScript est une classe Python, de même pour les méthodes et les attributs et vice versa. 🥳
C'est génial !
Comment utiliser Embedded Python ?
Il y a 3 façons principales d'utiliser Embedded Python :
- Utilisation la balise de langue dans ObjectScript
- Méthode Foo() As %String [ Language = python ]
- Utilisation de la fonction ##class(%SYS.Python).Import()
- Utilisation de l'interpréteur python
- python3 -c "import iris; print(iris.system.Version.GetVersion())"
Mais si vous voulez vous intéresser sérieusement à Embedded Python, vous aurez à éviter d'utiliser la balise de langue.

Pourquoi ?
- Parce que ce n'est pas Pythonic
- Parce que ce n'est pas ObjectScript non plus
- Parce que vous n'avez pas de débogueur
- Parce que vous n'avez pas de linter
- Parce que vous n'avez pas de formateur
- Parce que vous n'avez pas de cadre de test
- Parce que vous n'avez pas de gestionnaire de paquets
- Parce que vous mélangez 2 langues dans le même fichier
- Parce que lorsque votre processus plante, vous n'avez pas de trace de pile
- Parce que vous ne pouvez pas utiliser d'environnements virtuels ou d'environnements conda
- ...
Ne vous méprenez pas, ça marche, ça peut être utile, si vous voulez tester quelque chose rapidement, mais à mon avis, ce n'est pas une bonne pratique.
Alors, qu'est-ce que j'ai appris de ces 2 années de Embedded Python, et comment l'utiliser de la bonne manière ?
Comment j'utilise Embedded Python
Je crois que vous avez deux options :
- Utiliser les bibliothèques Python comme s'il s'agissait de classes ObjectScript
- withqvec ##class(%SYS.Python).Import() function
- Utiliser une première approche en python
Utilisation des bibliothèques et le code Python comme s'il s'agissait de classes ObjectScript
Vous voulez toujours utiliser Python dans votre code ObjectScript, mais vous ne voulez pas utiliser la balise de langue. Alors, que pouvez-vous faire ?
"Tout simplement" utilisez les bibliothèques et le code Python comme s'il s'agissait de classes ObjectScript.
Prenons un exemplee :
Vous voulez utiliser la bibliothèque 'requests' ( c'est une bibliothèque pour faire des requêtes HTTP ) dans votre code ObjectScript.
Avec la balise de langue
ClassMethod Get() As %Status [ Language = python ]
{
import requests
url = "https://httpbin.org/get"
# faire une requête d'obtention
response = requests.get(url)
# récupérer les données json de la réponse
data = response.json()
# itérer sur les données et imprimer les paires clé-valeur
for key, value in data.items():
print(key, ":", value)
}
Pourquoi je pense que ce n'est pas une bonne idée ?
Parce que vous mélangez 2 langues dans le même fichier, et que vous n'avez pas de débogueur, de linter, de formateur, etc.
Si ce code plante, vous aurez du mal à le déboguer.
Vous n'avez pas de trace de pile, et vous ne savez pas d'où vient l'erreur.
Et vous n'avez pas d'auto-complétion.
Sans de balise de langue
ClassMethod Get() As %Status
{
set status = $$$OK
set url = "https://httpbin.org/get"
// Importation du module Python "requests" en tant que classe ObjectScript
set request = ##class(%SYS.Python).Import("requests")
// Appel de la méthode get de la classe de requête
set response = request.get(url)
// Appel de la méthode json de la classe de réponse
set data = response.json()
// Ici, les données sont un dictionnaire Python
// Pour parcourir un dictionnaire Python, vous devez utiliser la méthode dunder et items()
// Importation du module Embedded Python
set builtins = ##class(%SYS.Python).Import("builtins")
// Ici, nous utilisons len du module intégré pour obtenir la longueur du dictionnaire
For i = 0:1:builtins.len(data)-1 {
// Maintenant, nous convertissons les éléments du dictionnaire en une liste, et nous obtenons la clé et la valeur en utilisant la méthode dunder __getitem__
Write builtins.list(data.items())."__getitem__"(i)."__getitem__"(0),": ",builtins.list(data.items())."__getitem__"(i)."__getitem__"(1),!
}
quit status
}
Pourquoi je pense que c'est une bonne idée ?
Parce que vous utilisez Python comme s'il s'agissait d'ObjectScript. Vous importez la bibliothèque de requêtes comme une classe ObjectScript et vous l'utilisez comme une classe ObjectScript.
Toute la logique est en ObjectScript, et vous utilisez Python comme une bibliothèque.
Même pour la maintenance, c'est plus facile à lire et à comprendre, n'importe quel développeur ObjectScript peut comprendre ce code.
L'inconvénient est que vous avez à savoir comment utiliser les méthodes de duners, et comment utiliser Python comme s'il s'agissait d'ObjectScript.
Conclusion
Croyez-moi, de cette manière vous obtiendrez un code plus robuste, et vous pourrez le déboguer facilement.
Au début, cela semble difficile, mais vous découvrirez les avantages de l'apprentissage de Python plus rapidement que vous ne le pensez.
Utilisation de première approche en python
C'est la façon dont je préfère utiliser Embedded Python.
J'ai construit beaucoup d'outils en utilisant cette approche, et j'en suis très satisfait.
Quelques exemples :
Qu'est-ce qu'une première approche python ?
TIl n'y a qu'une seule règle : Le code Python doit être dans des fichiers .py, le code ObjectScript doit être dans des fichiers .cls
Comment y parvenir ?
L'idée est de créer des classes de wrappers ObjectScript pour appeler le code Python.
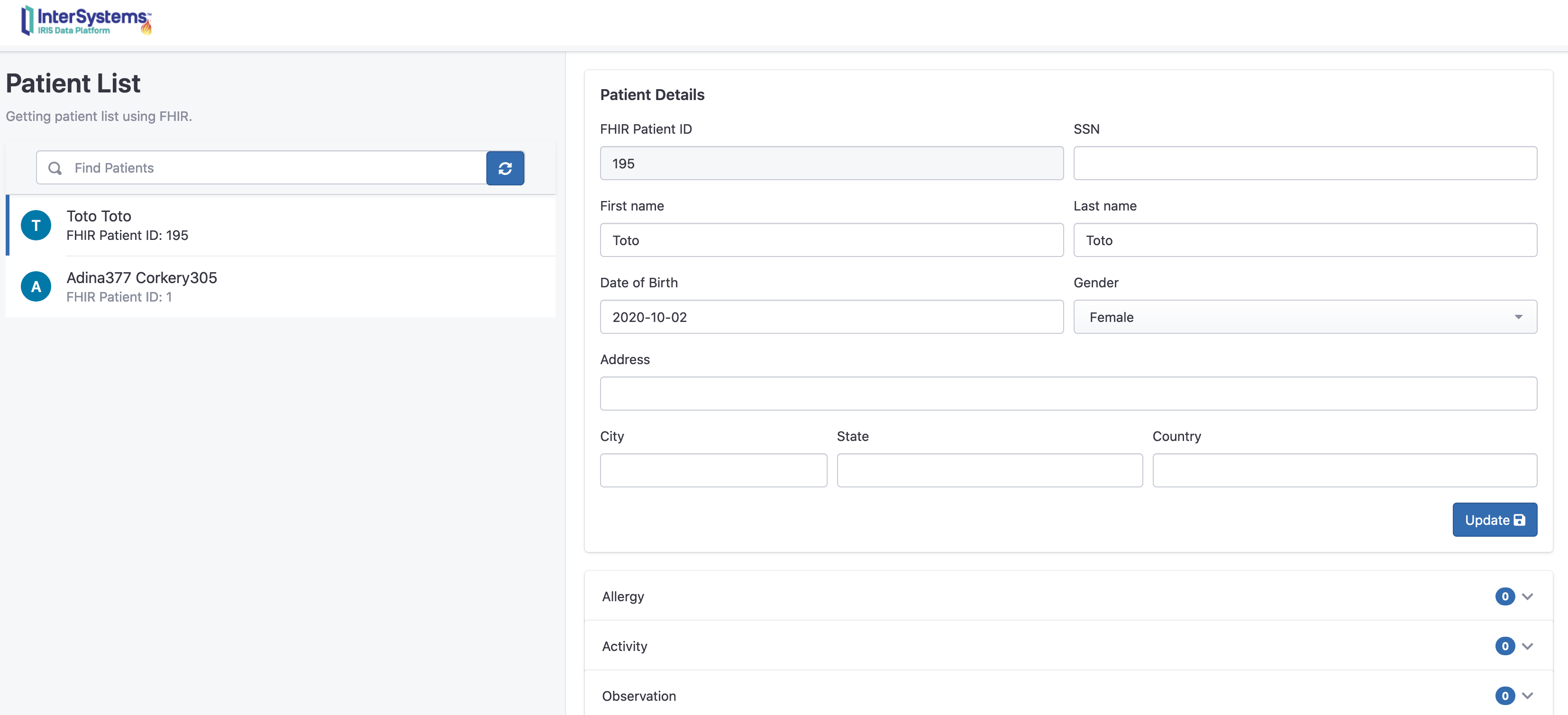
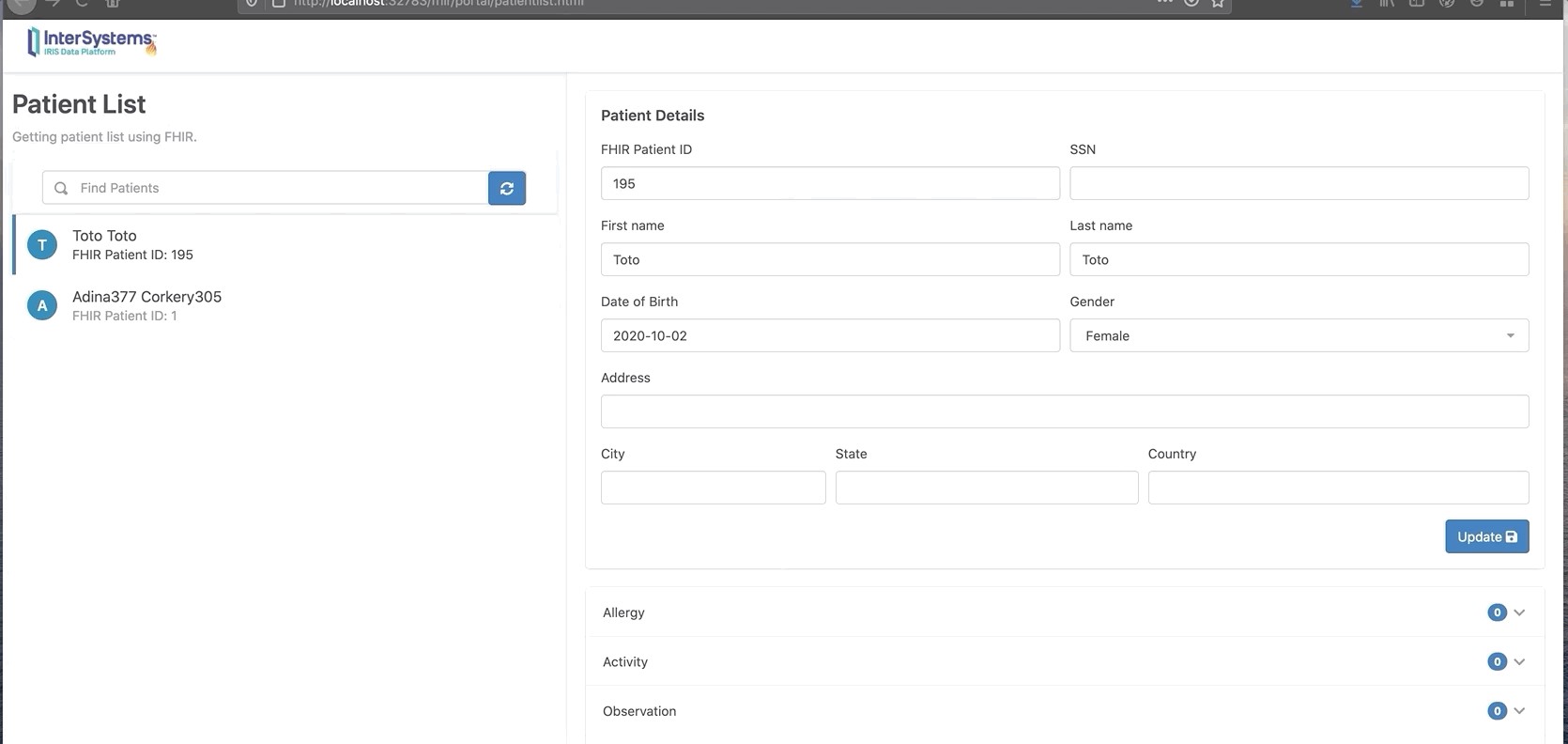
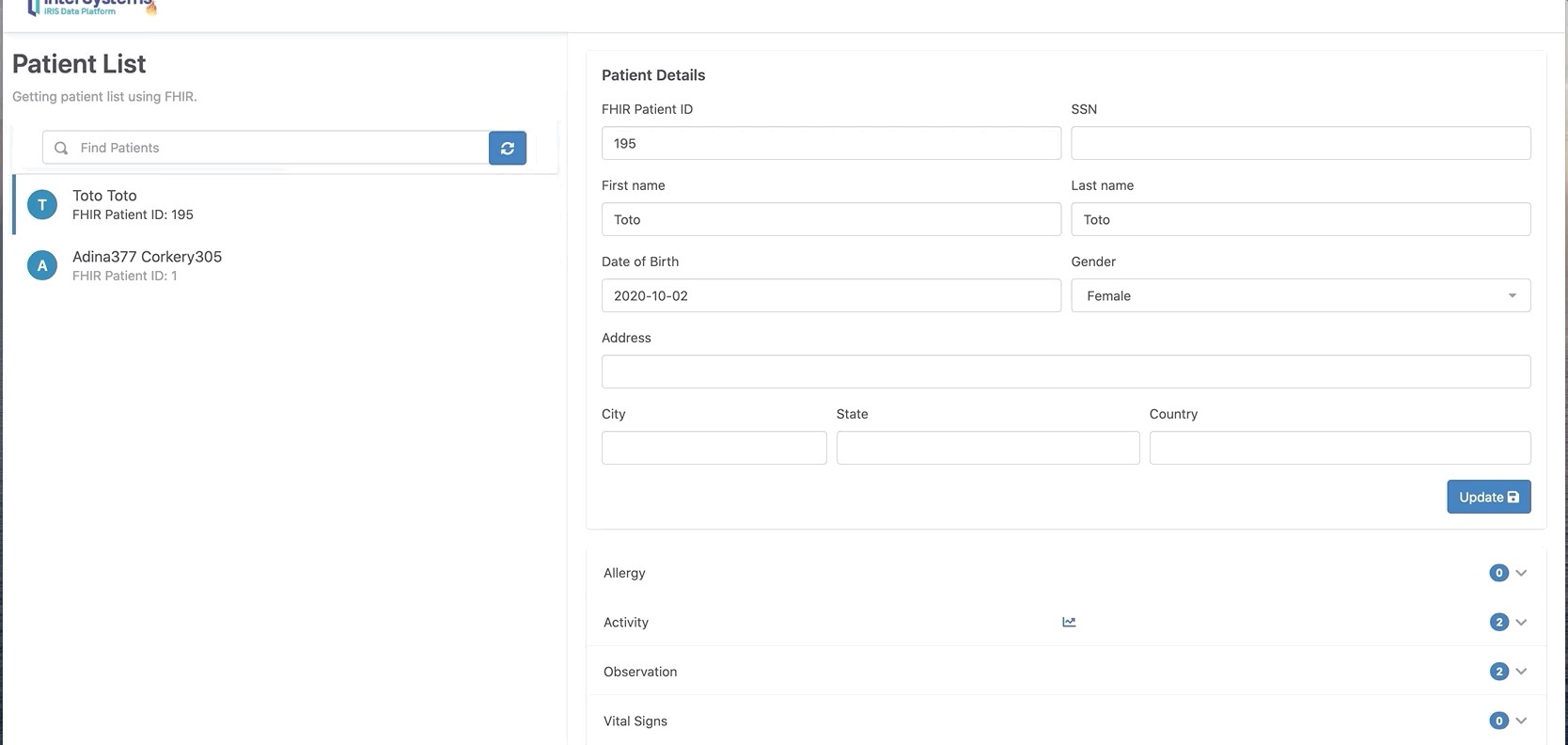
Prenons l'exemple de iris-fhir-python-strategy :
Exemple : iris-fhir-python-strategy
Tout d'abord, nous avons à comprendre comment fonctionne le serveur IRIS FHIR.
Chaque serveur IRIS FHIR met en œuvre une Stratégie.
Une Stratégie est un ensemble de deux classes :
| Superclass | Paramètres de sous-classe |
|---|
| HS.FHIRServer.API.InteractionsStrategy | StrategyKey — Spécifie un identifiant unique pour la stratégie InteractionsStrategy.
InteractionsClass — Spécifie le nom de votre sous-classe Interactions. |
| HS.FHIRServer.API.RepoManager | StrategyClass — Spécifie le nom de votre sous-classe InteractionsStrategy.
StrategyKey — Spécifie un identifiant unique pour la stratégie InteractionsStrategy. Ceci doit correspondre au paramètre StrategyKey dans la sous-classe InteractionsStrategy. |
Ces deux classes sont des classes abstraites Abtract Abstract.
HS.FHIRServer.API.InteractionsStrategy est une classe Abstract qui doit être mise en œuvre pour personnaliser le comportement du serveur FHIR.HS.FHIRServer.API.RepoManager est une classe Abstract qui doit être mise en œuvre pour personnaliser le stockage du serveur FHIR.
Remarques
Pour notre exemple, nous nous concentrerons uniquement sur la classe HS.FHIRServer.API.InteractionsStrategy même si la classe HS.FHIRServer.API.RepoManager est également implémentée et obligatoire pour personnaliser le serveur FHIR.
La classe HS.FHIRServer.API.RepoManager est mise en œuvre par HS.FHIRServer.Storage.Json.RepoManager qui est la mise en œuvre par défaut du serveur FHIR.
Où trouver le code
Tout le code source peut être trouvé dans le référentiel : iris-fhir-python-strategy
Le dossier src contient les dossiers suivants :
python : contient le code pythoncls : contient le code ObjectScript utilisé pour appeler le code python
Comment mettre en œuvre une Stratégie
Dans cette démonstration de faisabilité, nous nous intéresserons uniquement à la manière d'implémenter une Strategie en Python, et non à la manière de mettre en œuvre un RepoManager.
Pour mettre en œuvre une Strategie vous devez créer au moins deux classes :
- Une classe qui hérite de la classe
HS.FHIRServer.API.InteractionsStrategy - Une classe qui hérite de la classe
HS.FHIRServer.API.Interactions
Mise en œuvre d'InteractionsStrategy
La classe HS.FHIRServer.API.InteractionsStrategy vise à personnaliser le comportement du serveur FHIR en remplaçant les méthodes suivantes :
GetMetadataResource : appelé pour récupérer les métadonnées du serveur FHIR
- C'est la seule méthode que nous remplacerons dans cette preuve de concept
HS.FHIRServer.API.InteractionsStrategy a également deux paramètres :
StrategyKey : un identifiant unique pour la stratégie InteractionsStrategyInteractionsClass : le nom de votre sous-classe Interactions
Mise en œuvre des Interactions
La classe HS.FHIRServer.API.Interactions vise à personnaliser le comportement du serveur FHIR en remplaçant les méthodes suivantes :
OnBeforeRequest : appelée avant l'envoi de la requête au serveurOnAfterRequest : appelée après l'envoi de la requête au serveurPostProcessRead : appelée une fois l'opération de lecture terminéePostProcessSearch : appelée une fois l'opération de recherche terminéeRead : appelée pour lire une ressourceAdd : appelée pour ajouter une ressourceUpdate : appelée pour mettre à jour une ressourceDelete : appelée pour supprimer une ressource- et bien d'autres...
Nous mettons en œuvre la classe HS.FHIRServer.API.Interactions dans la classe src/cls/FHIR/Python/Interactions.cls.
Class FHIR.Python.Interactions Extends (HS.FHIRServer.Storage.Json.Interactions, FHIR.Python.Helper)
{
Parameter OAuth2TokenHandlerClass As%String = "FHIR.Python.OAuth2Token"
Method %OnNew(pStrategy As HS.FHIRServer.Storage.Json.InteractionsStrategy) As%Status
{
set..PythonPath = $system.Util.GetEnviron("INTERACTION_PATH")
set..PythonClassname = $system.Util.GetEnviron("INTERACTION_CLASS")
set..PythonModule = $system.Util.GetEnviron("INTERACTION_MODULE")
<span class="hljs-keyword">if</span> (<span class="hljs-built_in">..PythonPath</span> = <span class="hljs-string">""</span>) || (<span class="hljs-built_in">..PythonClassname</span> = <span class="hljs-string">""</span>) || (<span class="hljs-built_in">..PythonModule</span> = <span class="hljs-string">""</span>) {
<span class="hljs-comment">//quit ##super(pStrategy)</span>
<span class="hljs-keyword">set</span> <span class="hljs-built_in">..PythonPath</span> = <span class="hljs-string">"/irisdev/app/src/python/"</span>
<span class="hljs-keyword">set</span> <span class="hljs-built_in">..PythonClassname</span> = <span class="hljs-string">"CustomInteraction"</span>
<span class="hljs-keyword">set</span> <span class="hljs-built_in">..PythonModule</span> = <span class="hljs-string">"custom"</span>
}
<span class="hljs-comment">// Définissez ensuite la classe python</span>
<span class="hljs-keyword">do</span> <span class="hljs-built_in">..SetPythonPath</span>(<span class="hljs-built_in">..PythonPath</span>)
<span class="hljs-keyword">set</span> <span class="hljs-built_in">..PythonClass</span> = <span class="hljs-keyword">##class</span>(FHIR.Python.Interactions).GetPythonInstance(<span class="hljs-built_in">..PythonModule</span>, <span class="hljs-built_in">..PythonClassname</span>)
<span class="hljs-keyword">quit</span> <span class="hljs-keyword">##super</span>(pStrategy)
}
Method OnBeforeRequest(
pFHIRService As HS.FHIRServer.API.Service,
pFHIRRequest As HS.FHIRServer.API.Data.Request,
pTimeout As%Integer)
{
if$ISOBJECT(..PythonClass) {
set body = ##class(%SYS.Python).None()
if pFHIRRequest.Json '= "" {
set jsonLib = ##class(%SYS.Python).Import("json")
set body = jsonLib.loads(pFHIRRequest.Json.%ToJSON())
}
do..PythonClass."on_before_request"(pFHIRService, pFHIRRequest, body, pTimeout)
}
}
Method OnAfterRequest(
pFHIRService As HS.FHIRServer.API.Service,
pFHIRRequest As HS.FHIRServer.API.Data.Request,
pFHIRResponse As HS.FHIRServer.API.Data.Response)
{
if$ISOBJECT(..PythonClass) {
set body = ##class(%SYS.Python).None()
if pFHIRResponse.Json '= "" {
set jsonLib = ##class(%SYS.Python).Import("json")
set body = jsonLib.loads(pFHIRResponse.Json.%ToJSON())
}
do..PythonClass."on_after_request"(pFHIRService, pFHIRRequest, pFHIRResponse, body)
}
}
Method PostProcessRead(pResourceObject As%DynamicObject) As%Boolean
{
if$ISOBJECT(..PythonClass) {
if pResourceObject '= "" {
set jsonLib = ##class(%SYS.Python).Import("json")
set body = jsonLib.loads(pResourceObject.%ToJSON())
}
return..PythonClass."post_process_read"(body)
}
quit1
}
Method PostProcessSearch(
pRS As HS.FHIRServer.Util.SearchResult,
pResourceType As%String) As%Status
{
if$ISOBJECT(..PythonClass) {
return..PythonClass."post_process_search"(pRS, pResourceType)
}
quit$$$OK
}
Method Read(
pResourceType As%String,
pResourceId As%String,
pVersionId As%String = "") As%DynamicObject
{
return##super(pResourceType, pResourceId, pVersionId)
}
Method Add(
pResourceObj As%DynamicObject,
pResourceIdToAssign As%String = "",
pHttpMethod = "POST") As%String
{
return##super(pResourceObj, pResourceIdToAssign, pHttpMethod)
}
Method Delete(
pResourceType As%String,
pResourceId As%String) As%String
{
return##super(pResourceType, pResourceId)
}
Method Update(pResourceObj As%DynamicObject) As%String
{
return##super(pResourceObj)
}
}
La classe FHIR.Python.Interactions hérite de la classe HS.FHIRServer.Storage.Json.Interactions et de la classe FHIR.Python.Helper
La classe HS.FHIRServer.Storage.Json.Interactions est la mise en œuvre par défaut du serveur FHIR.
La classe FHIR.Python.Helper vise à aider à appeler du code Python à partir d'ObjectScript.
La classe FHIR.Python.Interactions remplacent les méthodes suivantes :
%OnNew : appelée lors de la création de l'objet
- nous utilisons cette méthode pour définir le chemin python, le nom de la classe python et le nom du module python à partir des variables d'environnement
- si les variables d'environnement ne sont pas définies, nous utilisons les valeurs par défaut
- nous définissons également la classe python
- nous appelons la méthode
%OnNew de la classe parente
Method %OnNew(pStrategy As HS.FHIRServer.Storage.Json.InteractionsStrategy) As %Status
{
// Définissez d'abord le chemin python à partir d'une variable d'environnement
set ..PythonPath = $system.Util.GetEnviron("INTERACTION_PATH")
// Puis définissez le nom de la classe python à partir de la variable d'environnement
set ..PythonClassname = $system.Util.GetEnviron("INTERACTION_CLASS")
// Puis définissez le nom du module python à partir de la variable d'environnement
set ..PythonModule = $system.Util.GetEnviron("INTERACTION_MODULE")
if (..PythonPath = "") || (..PythonClassname = "") || (..PythonModule = "") {
// utilisez les valeurs par défaut
set ..PythonPath = "/irisdev/app/src/python/"
set ..PythonClassname = "CustomInteraction"
set ..PythonModule = "custom"
}
// Ensuite, définissez la classe python
do ..SetPythonPath(..PythonPath)
set ..PythonClass = ..GetPythonInstance(..PythonModule, ..PythonClassname)
quit ##super(pStrategy)
}
OnBeforeRequest : appelée avant l'envoi de la requête au serveur
- nous appelons la méthode
on_before_request de la classe python - nous passons l'objet
HS.FHIRServer.API.Service, l'objet HS.FHIRServer.API.Data.Request, le corps de la requête et le timeout
Method OnBeforeRequest(
pFHIRService As HS.FHIRServer.API.Service,
pFHIRRequest As HS.FHIRServer.API.Data.Request,
pTimeout As %Integer)
{
// OnBeforeRequest est appelée avant le traitement de chaque requête.
if $ISOBJECT(..PythonClass) {
set body = ##class(%SYS.Python).None()
if pFHIRRequest.Json '= "" {
set jsonLib = ##class(%SYS.Python).Import("json")
set body = jsonLib.loads(pFHIRRequest.Json.%ToJSON())
}
do ..PythonClass."on_before_request"(pFHIRService, pFHIRRequest, body, pTimeout)
}
}
OnAfterRequest : appelée après l'envoi de la requête au serveur
- nous appelons la méthode
on_after_request de la classe python - nous passons l'objet
HS.FHIRServer.API.Service, l'objet HS.FHIRServer.API.Data.Request, l'objet HS.FHIRServer.API.Data.Response et le corps de la réponse
Method OnAfterRequest(
pFHIRService As HS.FHIRServer.API.Service,
pFHIRRequest As HS.FHIRServer.API.Data.Request,
pFHIRResponse As HS.FHIRServer.API.Data.Response)
{
// OnAfterRequest est appelée après le traitement de chaque requête.
if $ISOBJECT(..PythonClass) {
set body = ##class(%SYS.Python).None()
if pFHIRResponse.Json '= "" {
set jsonLib = ##class(%SYS.Python).Import("json")
set body = jsonLib.loads(pFHIRResponse.Json.%ToJSON())
}
do ..PythonClass."on_after_request"(pFHIRService, pFHIRRequest, pFHIRResponse, body)
}
}
Interactions en Python
La classeFHIR.Python.Interactions appelle les méthodes on_before_request, on_after_request, ... de la classe python.
Voici la classe python abstraite :
import abc
import iris
class Interaction(object):
__metaclass__ = abc.ABCMeta
@abc.abstractmethod
def on_before_request(self,
fhir_service:'iris.HS.FHIRServer.API.Service',
fhir_request:'iris.HS.FHIRServer.API.Data.Request',
body:dict,
timeout:int):
"""
on_before_request is called before the request is sent to the server.
param fhir_service: the fhir service object iris.HS.FHIRServer.API.Service
param fhir_request: the fhir request object iris.FHIRServer.API.Data.Request
param timeout: the timeout in seconds
return: None
"""
@abc.abstractmethod
def on_after_request(self,
fhir_service:'iris.HS.FHIRServer.API.Service',
fhir_request:'iris.HS.FHIRServer.API.Data.Request',
fhir_response:'iris.HS.FHIRServer.API.Data.Response',
body:dict):
"""
on_after_request is called after the request is sent to the server.
param fhir_service: the fhir service object iris.HS.FHIRServer.API.Service
param fhir_request: the fhir request object iris.FHIRServer.API.Data.Request
param fhir_response: the fhir response object iris.FHIRServer.API.Data.Response
return: None
"""
@abc.abstractmethod
def post_process_read(self,
fhir_object:dict) -> bool:
"""
post_process_read is called after the read operation is done.
param fhir_object: the fhir object
return: True the resource should be returned to the client, False otherwise
"""
@abc.abstractmethod
def post_process_search(self,
rs:'iris.HS.FHIRServer.Util.SearchResult',
resource_type:str):
"""
post_process_search is called after the search operation is done.
param rs: the search result iris.HS.FHIRServer.Util.SearchResult
param resource_type: the resource type
return: None
"""
Mise en œuvre de la classe abstraite python
from FhirInteraction import Interaction
class CustomInteraction(Interaction):
def on_before_request(self, fhir_service, fhir_request, body, timeout):
#Extract the user and roles for this request
#so consent can be evaluated.
self.requesting_user = fhir_request.Username
self.requesting_roles = fhir_request.Roles
def on_after_request(self, fhir_service, fhir_request, fhir_response, body):
#Clear the user and roles between requests.
self.requesting_user = ""
self.requesting_roles = ""
def post_process_read(self, fhir_object):
#Evaluate consent based on the resource and user/roles.
#Returning 0 indicates this resource shouldn't be displayed - a 404 Not Found
#will be returned to the user.
return self.consent(fhir_object['resourceType'],
self.requesting_user,
self.requesting_roles)
def post_process_search(self, rs, resource_type):
#Iterate through each resource in the search set and evaluate
#consent based on the resource and user/roles.
#Each row marked as deleted and saved will be excluded from the Bundle.
rs._SetIterator(0)
while rs._Next():
if not self.consent(rs.ResourceType,
self.requesting_user,
self.requesting_roles):
#Mark the row as deleted and save it.
rs.MarkAsDeleted()
rs._SaveRow()
def consent(self, resource_type, user, roles):
#Example consent logic - only allow users with the role '%All' to see
#Observation resources.
if resource_type == 'Observation':
if '%All' in roles:
return True
else:
return False
else:
return True
Trop long, faisons un résumé
La classeFHIR.Python.Interactions est un wrapper pour appeler la classe python.
Les classes abstraites IRIS sont implémentées pour envelopper les classes abstraites python 🥳.
Cela nous aide à séparer le code python et le code ObjectScript et à bénéficier ainsi du meilleur des deux mondes.




.png)
.png)
.png)
.png)
.png)



.png)

.png)
.png)











.png)
.png)
.png) Getting Started (Pour Commencer) -
Getting Started (Pour Commencer) - .png) Apprentissage en ligne -
Apprentissage en ligne - .png)
.png) Évaluation -
Évaluation - .png) Communauté de développeurs -
Communauté de développeurs - .png) Idées InterSystems -
Idées InterSystems - .png) Les Masters Mondiaux -
Les Masters Mondiaux - .png) Open Exchange -
Open Exchange - .png) WRC -
WRC - .png) iService -
iService - .png) ICR -
ICR - .png) Répertoire de partenaires -
Répertoire de partenaires - .png) CCR -
CCR - .png) Connexion Client -
Connexion Client - .png) Commande en ligne -
Commande en ligne - .png)



.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)

.png)
.png)