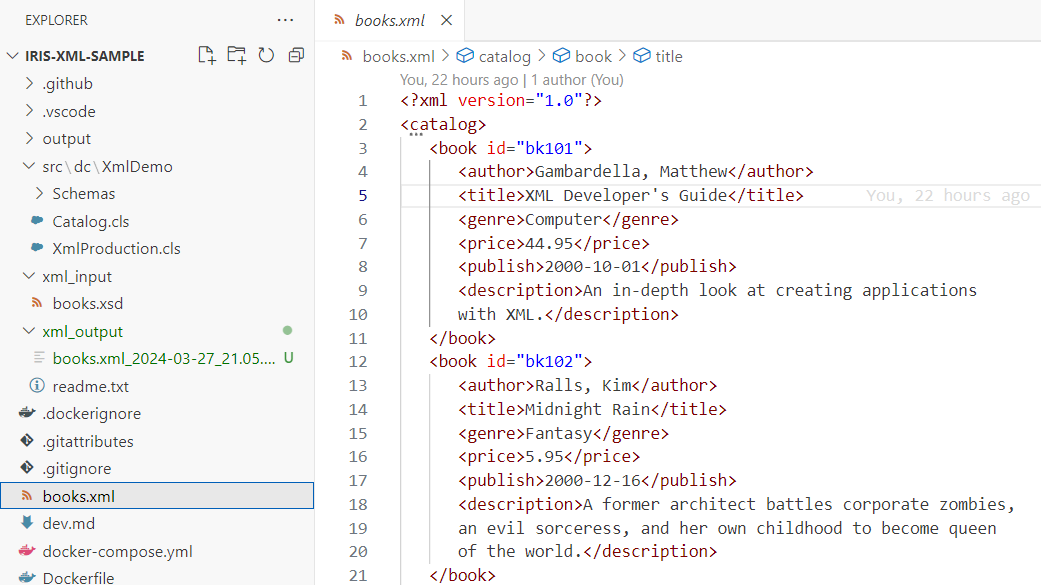
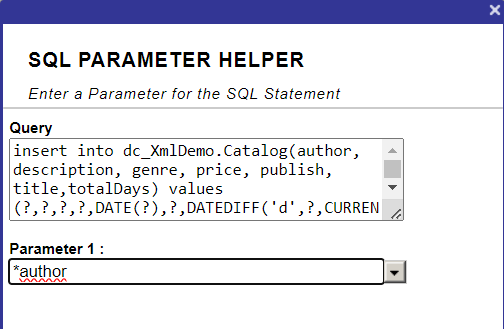
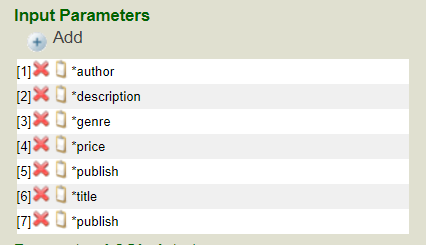
Cet article a pour objectif de fournir au lecteur les informations suivantes:
- Configuration et utilisation du serveur FHIR
- Création d'un serveur d'autorisation OAuth2
- Liaison entre le serveur FHIR et le serveur d'autorisation OAuth2 pour la prise en charge de SMART sur FHIR
- Utilisation des capacités d'interopérabilité dans "IRIS for Health" pour filtrer les ressources FHIR
- Création d'une opération personnalisée sur le serveur FHIR
Schéma de l'article:
Flux de travail de l'article:
1. Table des matières
2. Objectifs
Cette session de formation vise à fournir aux participants les compétences suivantes:
- Configuration et utilisation du serveur FHIR
- Création d'un serveur d'autorisation OAuth2
- Liaison entre le serveur FHIR et le serveur d'autorisation OAuth2 pour la prise en charge de SMART sur FHIR
- Utilisation des capacités d'interopérabilité dans "IRIS for Health" pour filtrer les ressources FHIR
- Création d'une opération personnalisée sur le serveur FHIR
3. Installation
Pour installer l'environnement de formation, vous devez avoir installé Docker et Docker Compose sur votre machine.
Vous pouvez installer Docker et Docker Compose en suivant les instructions sur le site Docker website.
Une fois Docker et Docker Compose installés, vous pouvez cloner ce dépôt et exécuter la commande suivante:
docker-compose up -d
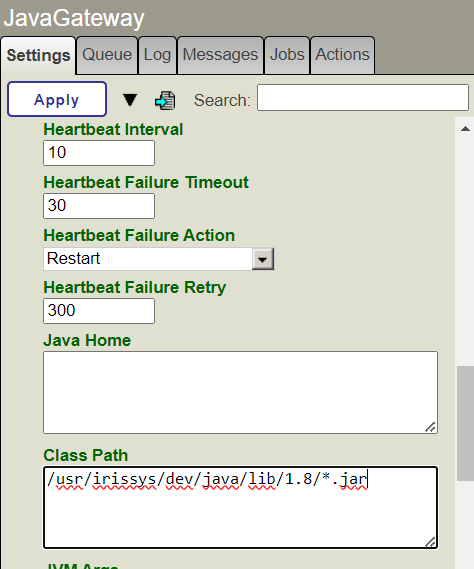
Cette commande démarre le conteneur "IRIS for Health" et le conteneur "Web Gateway" pour exposer le serveur FHIR via HTTPS.
3.1. Accès au serveur FHIR
Une fois les conteneurs démarrés, vous pouvez accéder au serveur FHIR à l'URL suivante:
https://localhost:4443/fhir/r5/
3.2. Accés au Portail de Gestion d'InterSystems IRIS
Vous pouvez accéder au portail de gestion InterSystems IRIS à l'adresse suivante:
http://localhost:8089/csp/sys/UtilHome.csp
Le nom d'utilisateur et le mot de passe par défaut sont "SuperUser" et "SYS" respectivement.
4. Configuration du serveur d'autorisation OAuth2
Pour configurer le serveur d'autorisation OAuth2, il faut se connecter au portail de gestion InterSystems IRIS et naviguer jusqu'à l'administration du système: System Administration > Security > OAuth 2.0 > Servers.
Ensuite, nous remplirons le formulaire pour créer un nouveau serveur d'autorisation OAuth2.
4.1. Onglet Généralités
Nous commençons d'abord par l'onglet Généralités.
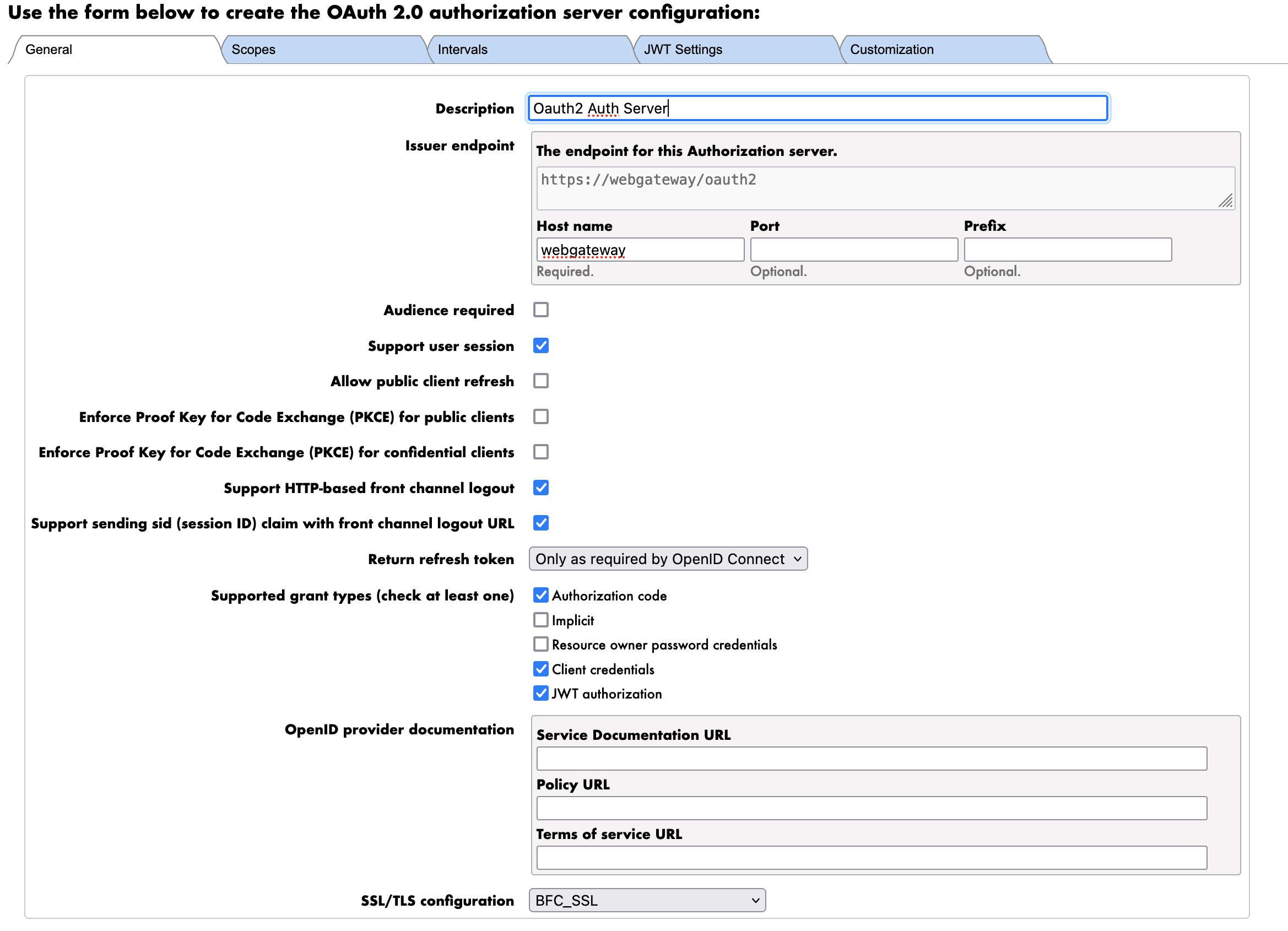
Les paramètres sont les suivants:
- Description: La description du serveur d'autorisation OAuth2
- Serveur d'autorisation Oauth2 Auth
- Émetteur: L'URL du serveur d'autorisation OAuth2
- https://webgateway/oauth2
- REMARQUE : Nous utilisons ici l'URL de la passerelle Web Gateway pour exposer le serveur FHIR via HTTPS. Il s'agit du nom DNS interne du conteneur de la passerelle Web Gateway.
- Types de subventions pris en charge: Les types de subventions pris en charge par le serveur d'autorisation OAuth2
- Code d'autorisation
- Informations d'identification du client
- Autorisation JWT
- REMARQUE : Nous utiliserons le type de subvention de Client Credentials (informations d'identification du client) pour authentifier le serveur FHIR auprès du serveur d'autorisation OAuth2.
- Configuration SSL/TLS: La configuration SSL/TLS à utiliser pour le serveur d'autorisation OAuth2.
4.2. Onglet Périmètre
Ensuite, nous passons à l'onglet Périmètre.
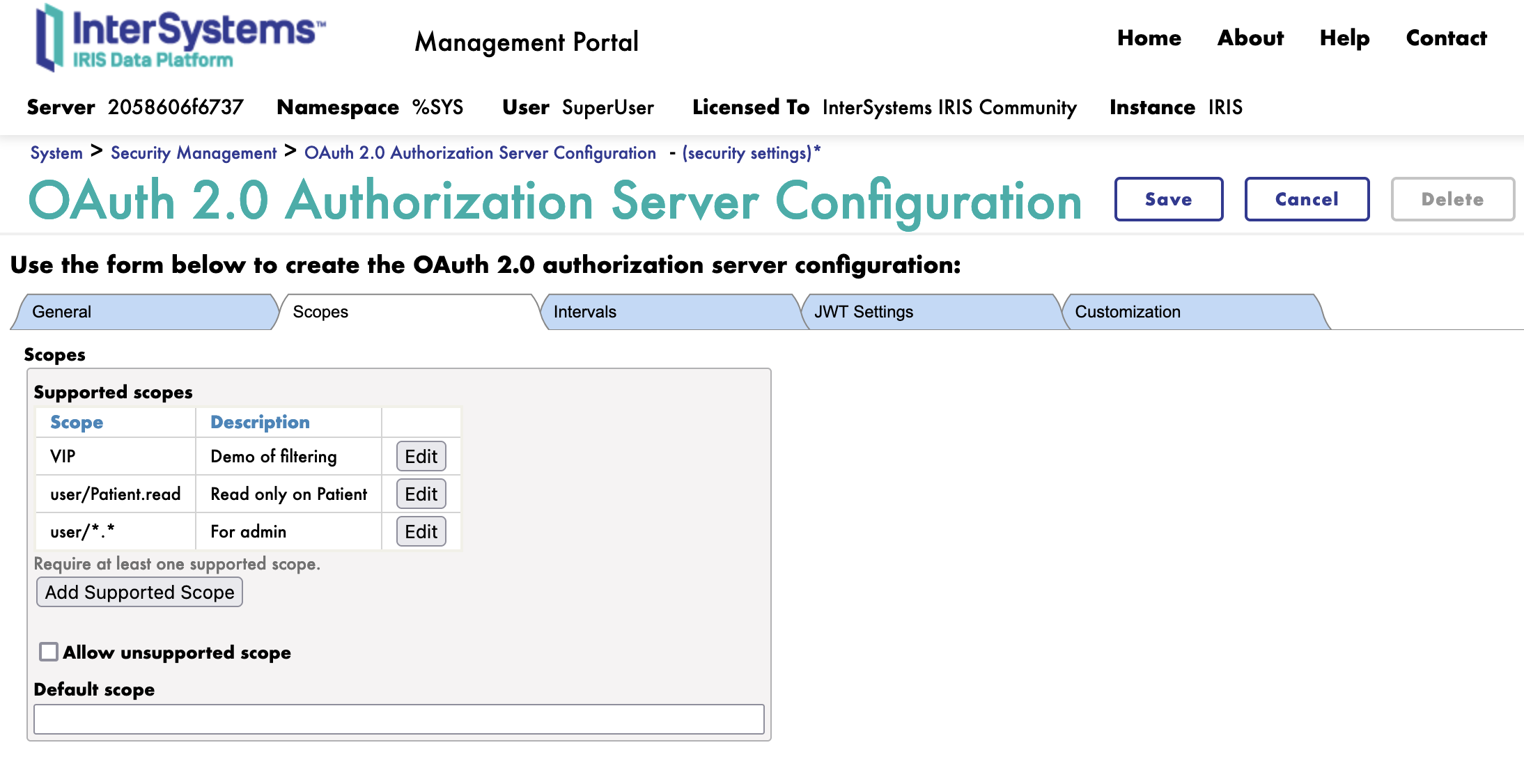
Nous allons créer 3 périmètres:
- user/Patient.read: Le périmètre de lecture des ressources disponibles pour les patients
- VIP: Le périmètre de lecture des ressources disponibles pour les patients VIP
- user/.: Le périmètre de lecture toutes les ressources, à des fins administratives
4.3. Onglet JWT
Ensuite, nous passons à l'onglet JWT.
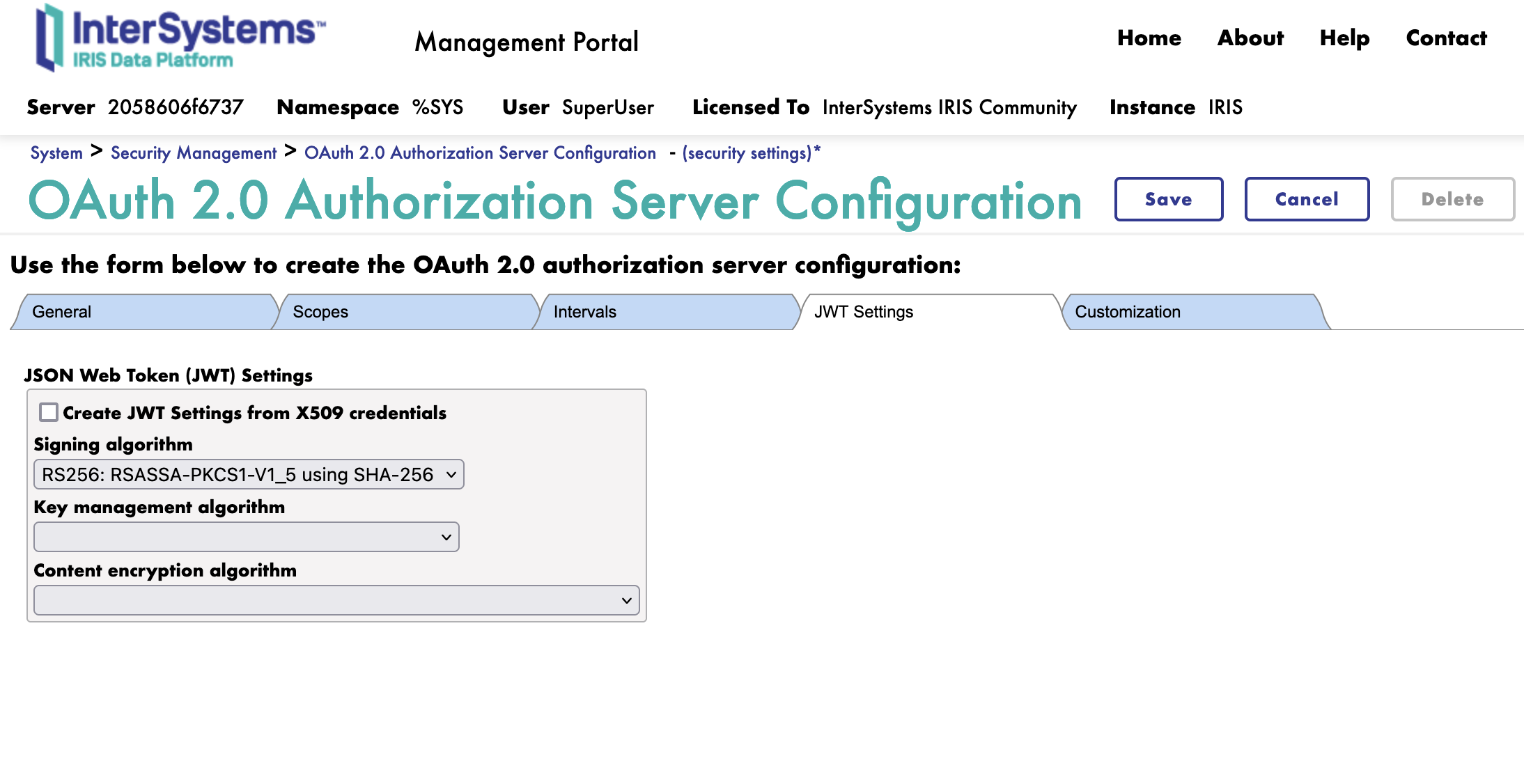
Ici, nous sélectionnons simplement l'algorithme à utiliser pour le JWT..
Nous utiliserons l'algorithme RS256.
Si nécessaire, nous pouvons sélectionner le cryptage pour le JWT. Nous n'utiliserons pas de cryptage pour cette session de formation.
4.4. Onglet Personnalisation
Ensuite, nous passons à l'onglet Personnalisation.
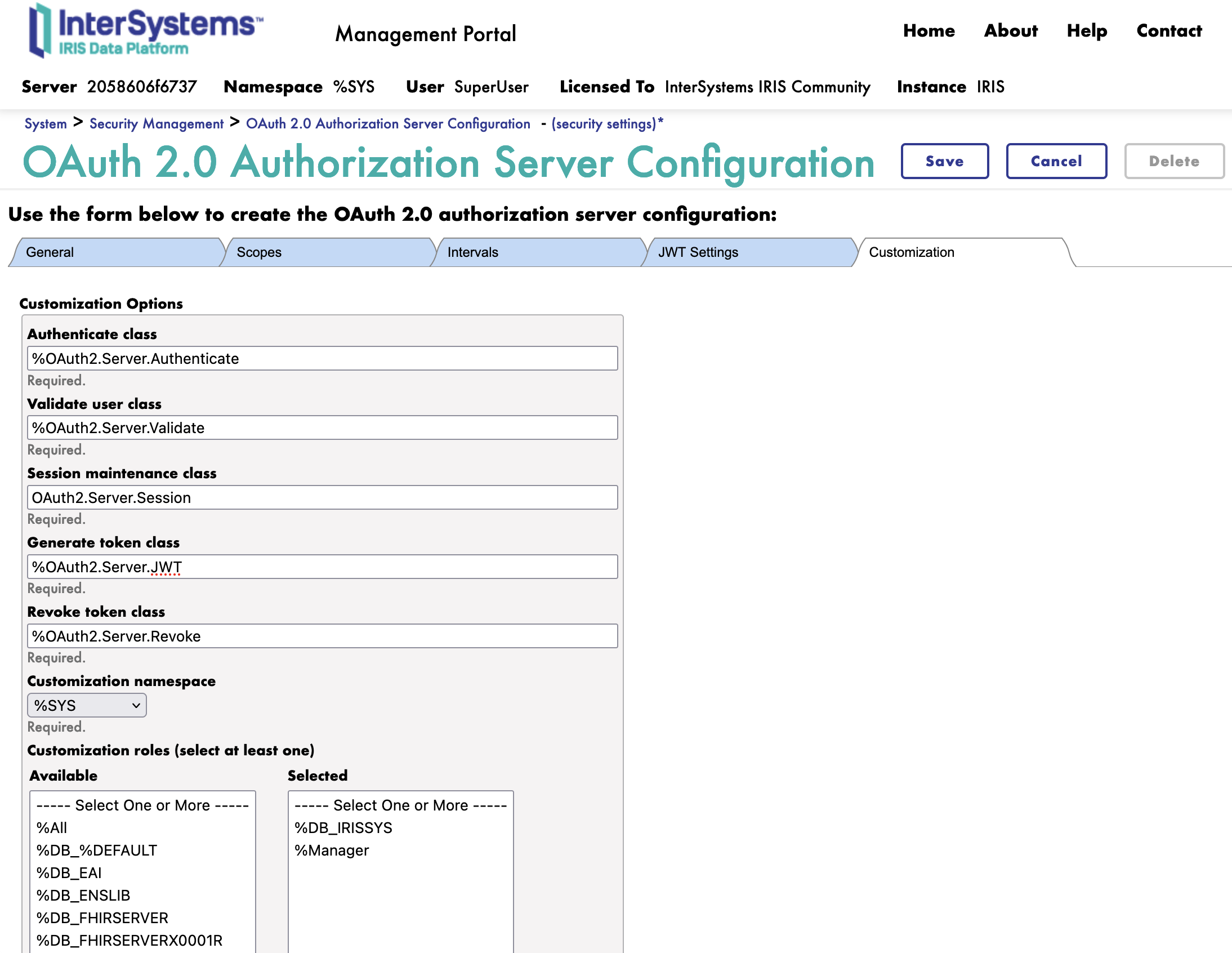
Voici toutes les classes de personnalisation pour le serveur d'autorisation OAuth2.
Nous changeons les classes suivantes:
- Classe de génération du jeton: La classe à utiliser pour générer le jeton
- FROM : %OAuth2.Server.Generate
- TO : %OAuth2.Server.JWT
Nous pouvons maintenant enregistrer le serveur d'autorisation OAuth2.
Félicitations, nous avons maintenant configuré le serveur d'autorisation OAuth2. 🥳
5. Configuration du Client
Pour configurer le Client, il faut se connecter au portail de gestion InterSystems IRIS et naviguer jusqu'à l'administration du système: System Administration > Security > OAuth 2.0 > Client.
Pour créer un nouveau client, il faut d'abord enregistrer le serveur d'autorisation OAuth2.
5.1. Enregistrement du serveur d'autorisation OAuth2
Sur la page client, cliquez sur le bouton de création d'une description de serveur Create Server Description.
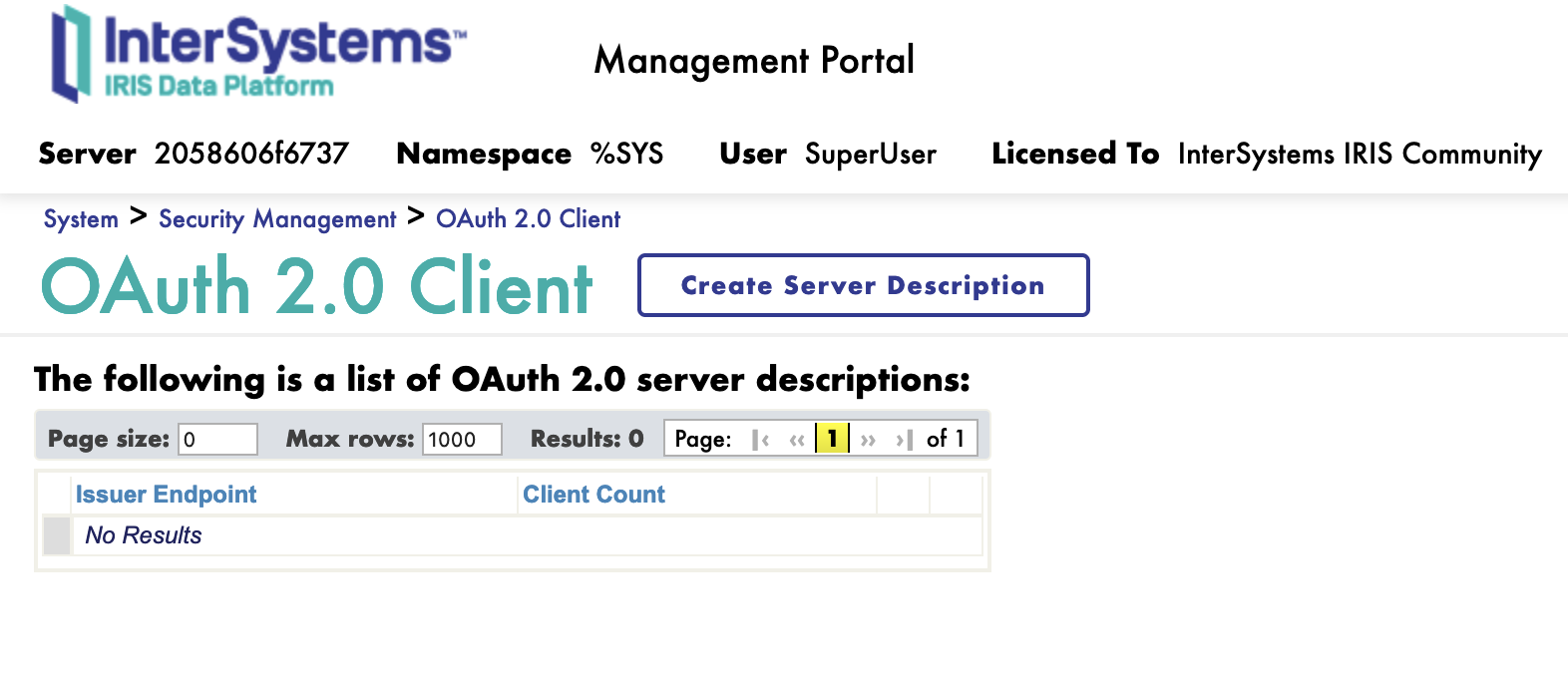
5.2. Description du serveur
Dans le formulaire Description du serveur, nous devons remplir les paramètres suivants:
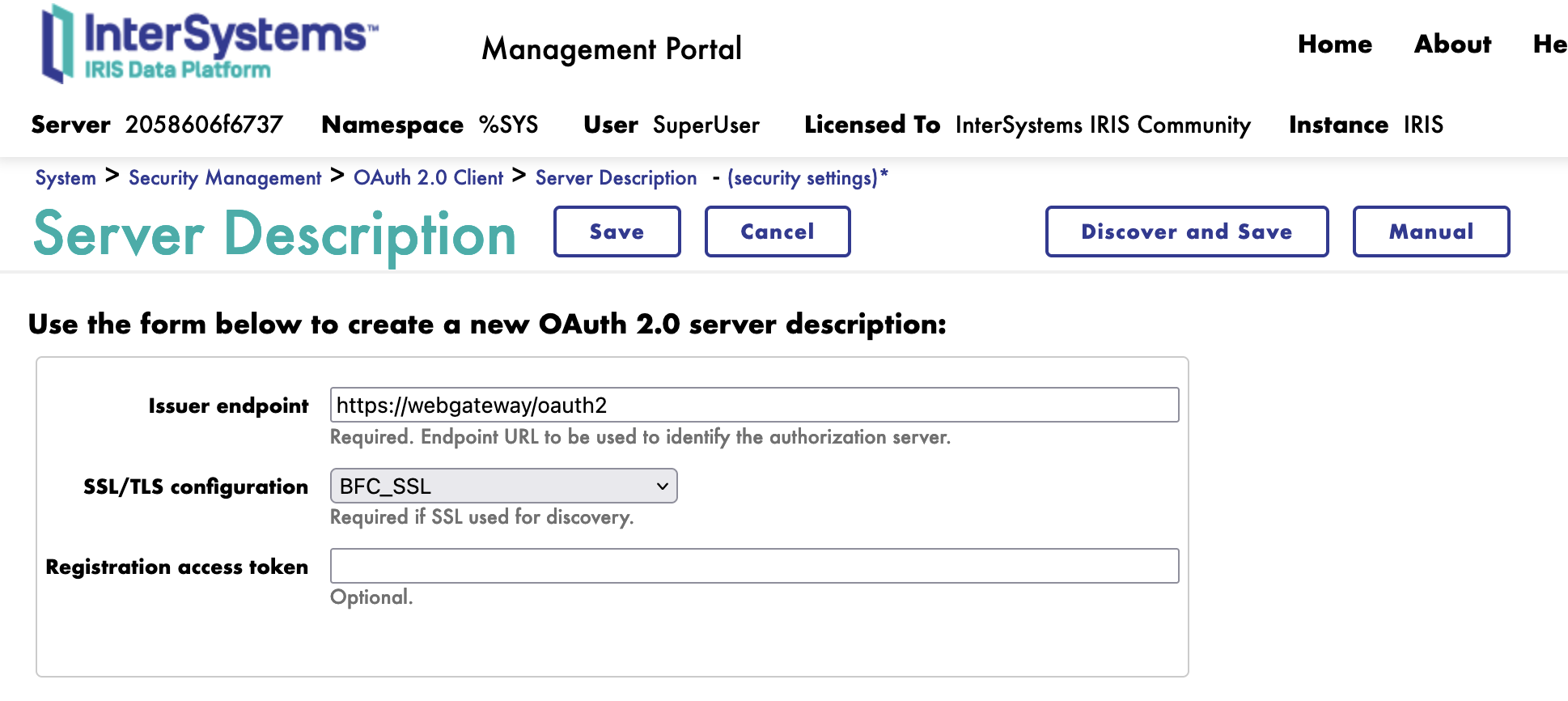
- URL du serveur: L'URL du serveur d'autorisation OAuth2
- Configuration SSL/TLS: La configuration SSL/TLS à utiliser pour le serveur d'autorisation OAuth2
Cliquez sur le bouton Discover and Save (Découvrir et enregistrer).
Félicitations, nous avons maintenant enregistré le serveur d'autorisation OAuth2.
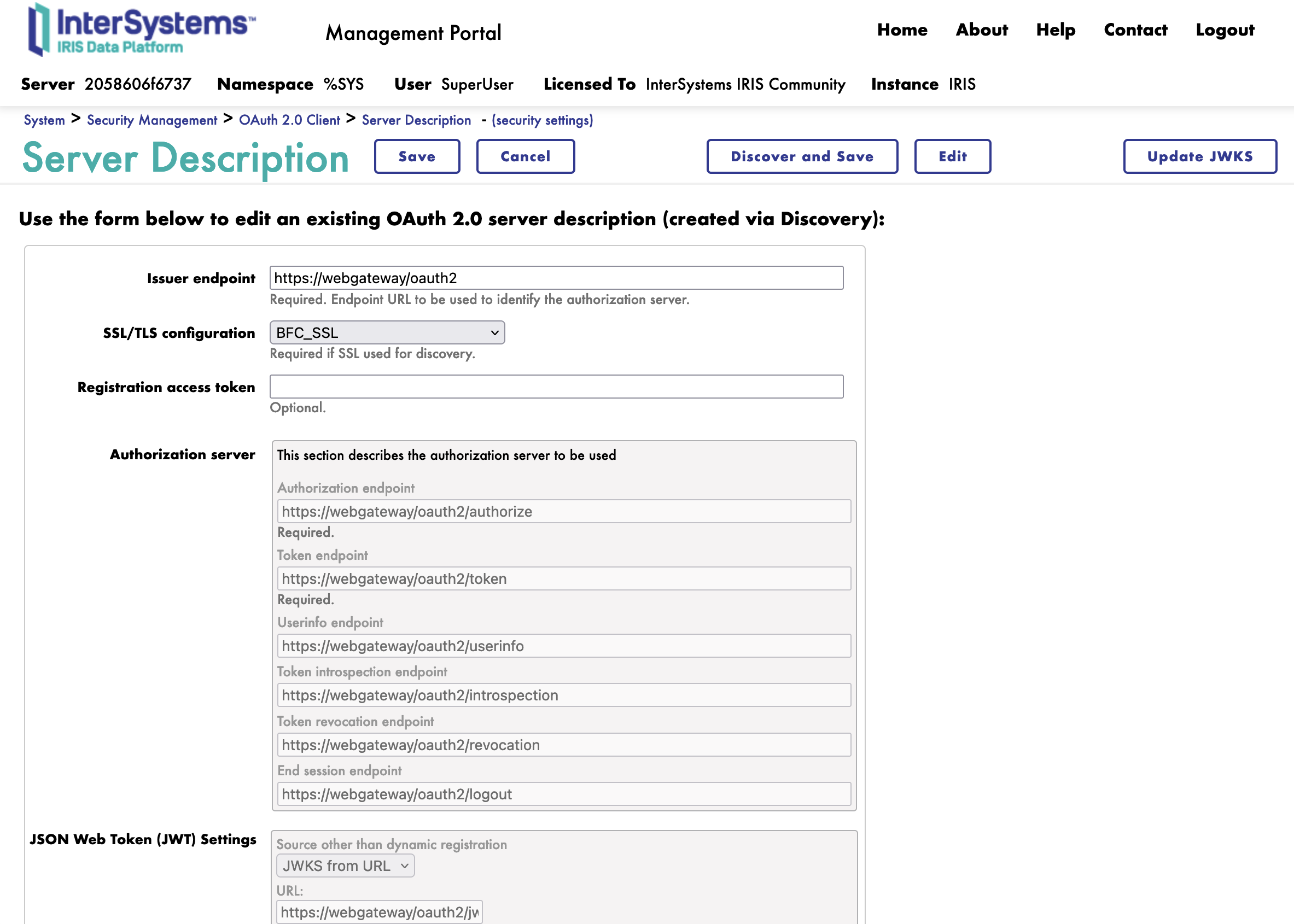
5.3. Création d'un nouveau client
Ensuite, nous pouvons créer un nouveau client.
Sur la page client, nous avons un nouveau bouton Client Configuration (Configuration Client).
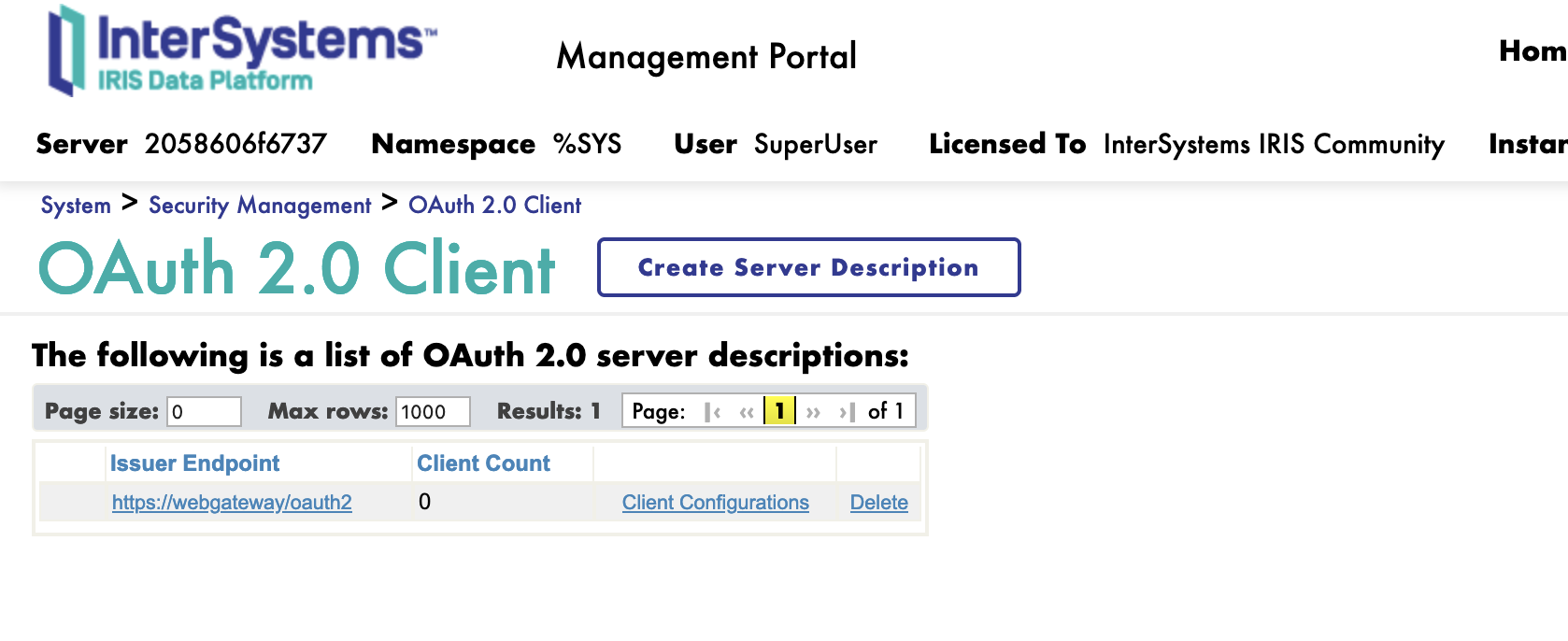
Cliquez sur le bouton de lien Client Configuration vers la description du serveur.
Nous pouvons maintenant créer un nouveau client..
5.3.1. Onglet Généralités
Nous commençons d'abord par l'onglet Généralités.
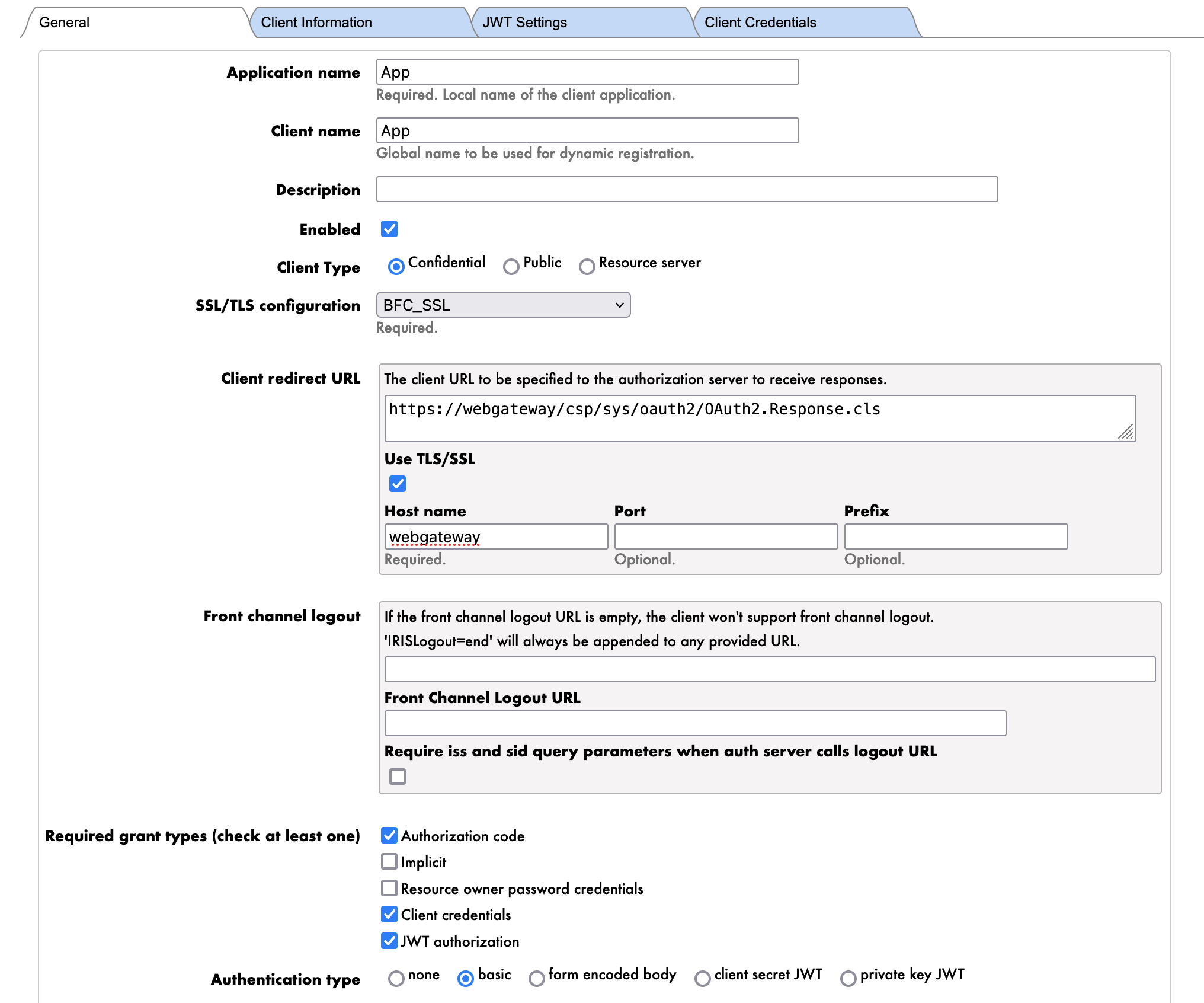
Les paramètres sont les suivants:
- Nom de l'application: Le nom du client
- App
- REMARQUE : C'est le nom du client.
- Nom du client: Le nom du client
- *Type de client: Le type du client
- Confidentiel
- REMARQUE : Nous utiliserons le type de client "confidentiel" pour authentifier le serveur FHIR auprès du serveur d'autorisation OAuth2.
- URI de redirection: L'URI de redirection du client
- https://webgateway/oauth2
- REMARQUE : Nous utilisons ici l'URL de la passerelle Web Gateway pour exposer le serveur FHIR via HTTPS. Il s'agit du nom DNS interne du conteneur de la passerelle Web Gateway.
- REMARQUE : Ceci ne sera pas utilisé dans cette session de formation.
- Types de subventions: Les types de subventions pris en charge par le client
- Informations d'identification du client
- REMARQUE : Nous utiliserons le type de subvention de Client Credentials (informations d'identification du client) pour authentifier l'application client (Client Application) auprès du serveur d'autorisation OAuth2.
- Type d'authentification: Le type d'authentification du client
- Basique
- REMARQUE : Nous utiliserons le type d'authentification Basique pour authentifier l'application client (Client Application) auprès du serveur d'autorisation OAuth2.
Maintenant, nous pouvons cliquer sur le bouton Dynamic Registration (Enregistrement dynamique)..
Félicitations, nous avons maintenant créé le client. 🥳
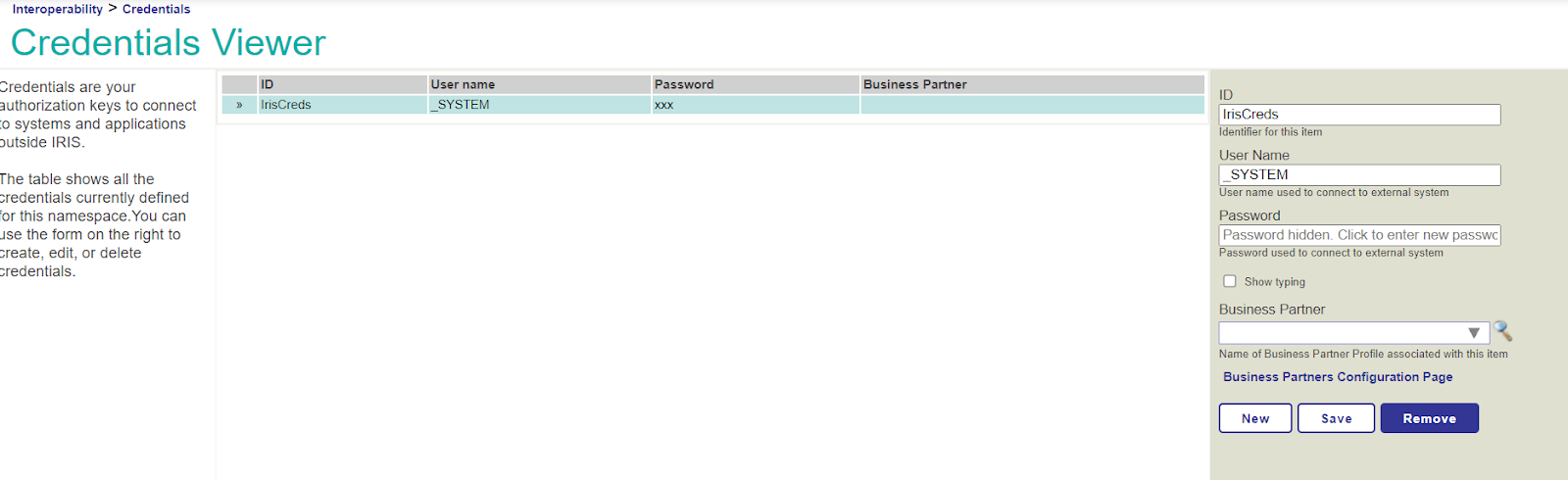
Si nous allons dans l'onglet Client Credentials (Informations d'identification du client), nous pouvons voir les informations d'identification du client.
Notez que les informations d'identification du client sont Client ID et Client Secret (l'Identifiant du client et le Secret du client).
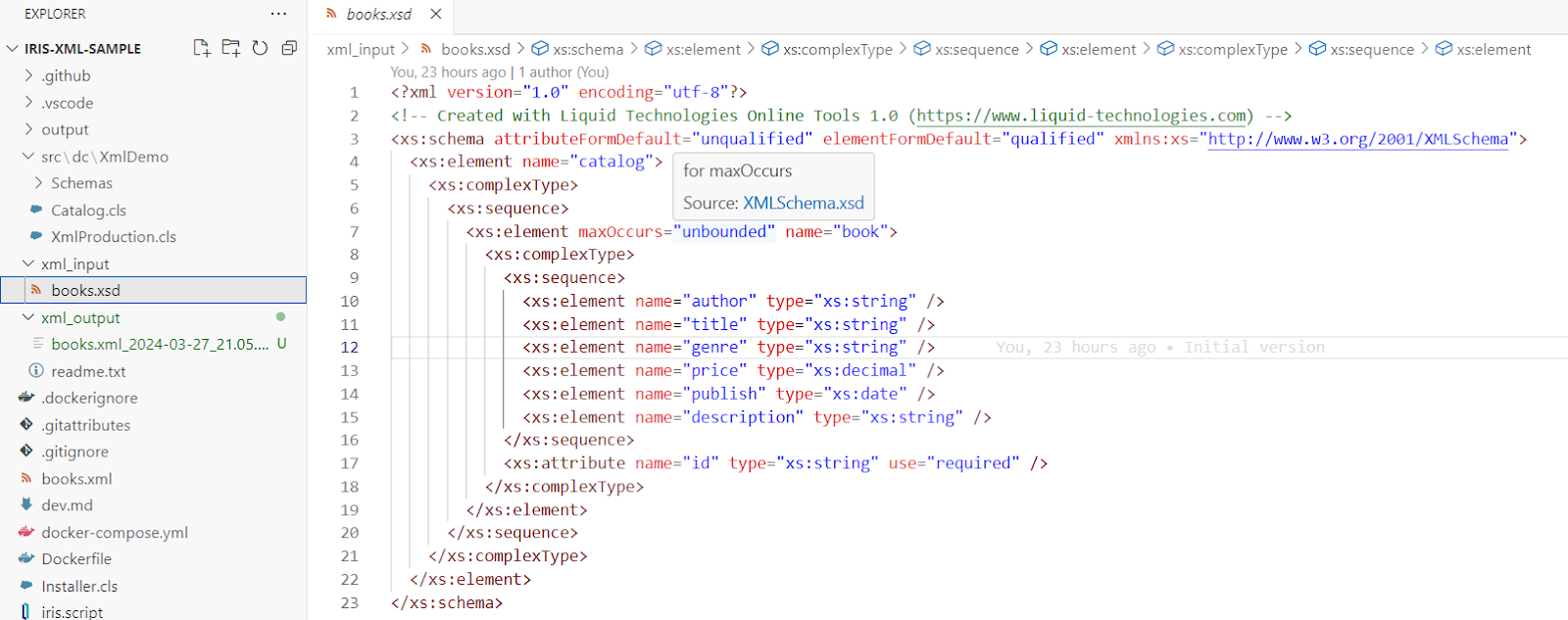
6. Configuration du serveur FHIR
⚠️ AVERTISSEMENT ⚠️ : Assurez-vous d'être sur l'espace de noms FHIRSERVER.
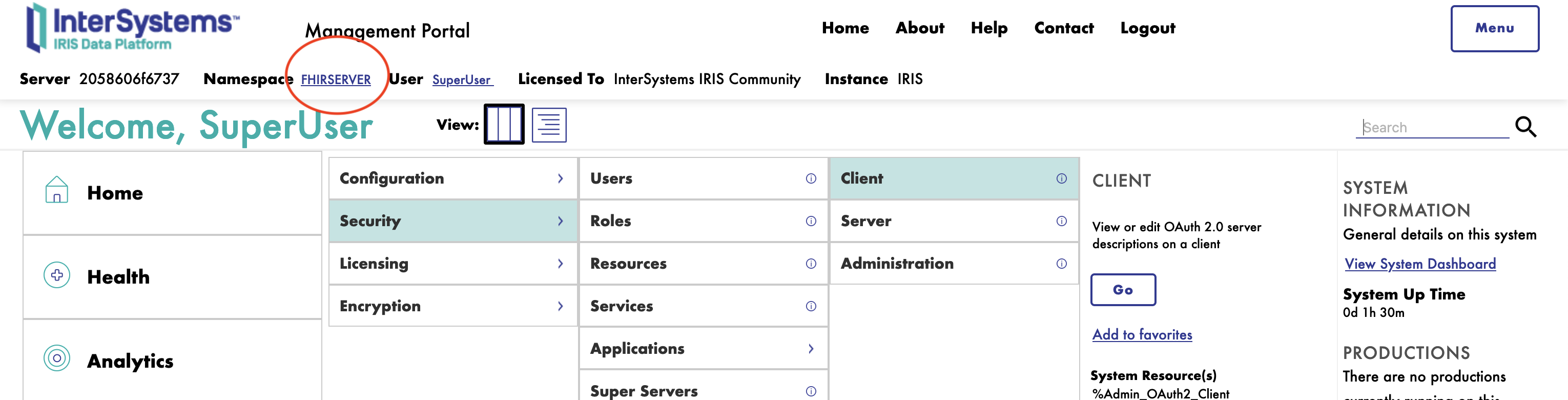
Pour configurer le serveur FHIR, il faut se connecter au portail de gestion InterSystems IRIS et naviguer: Health > FHIR Configuration > Servers.
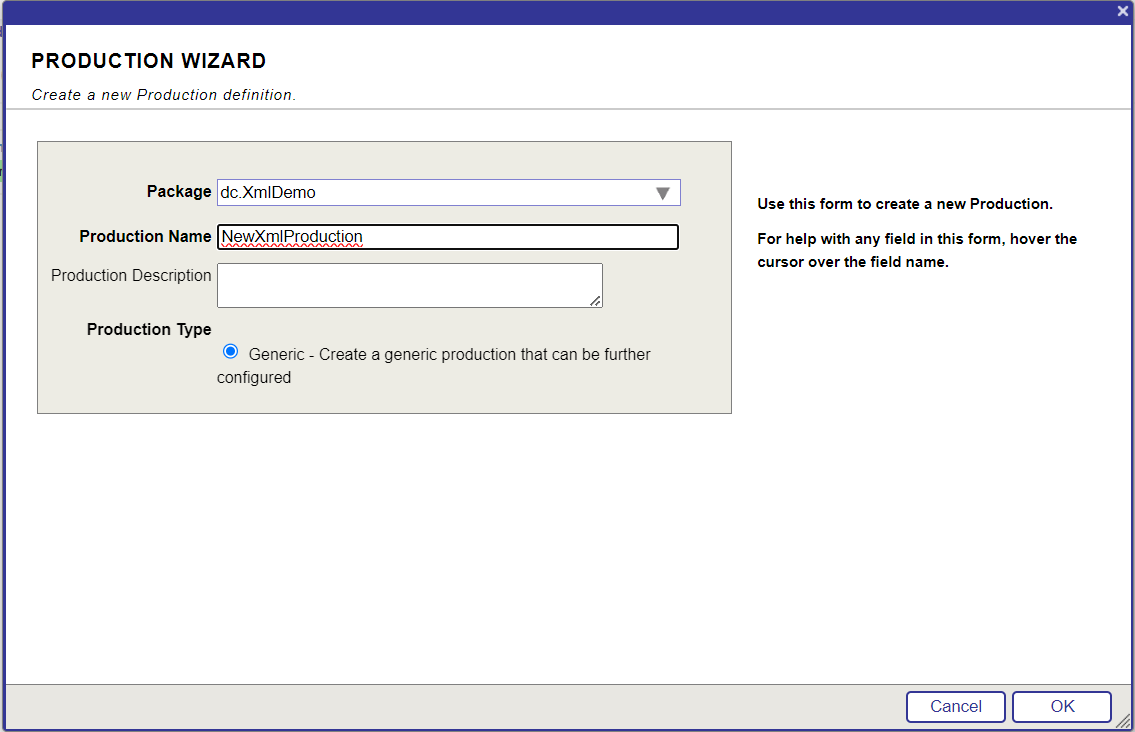
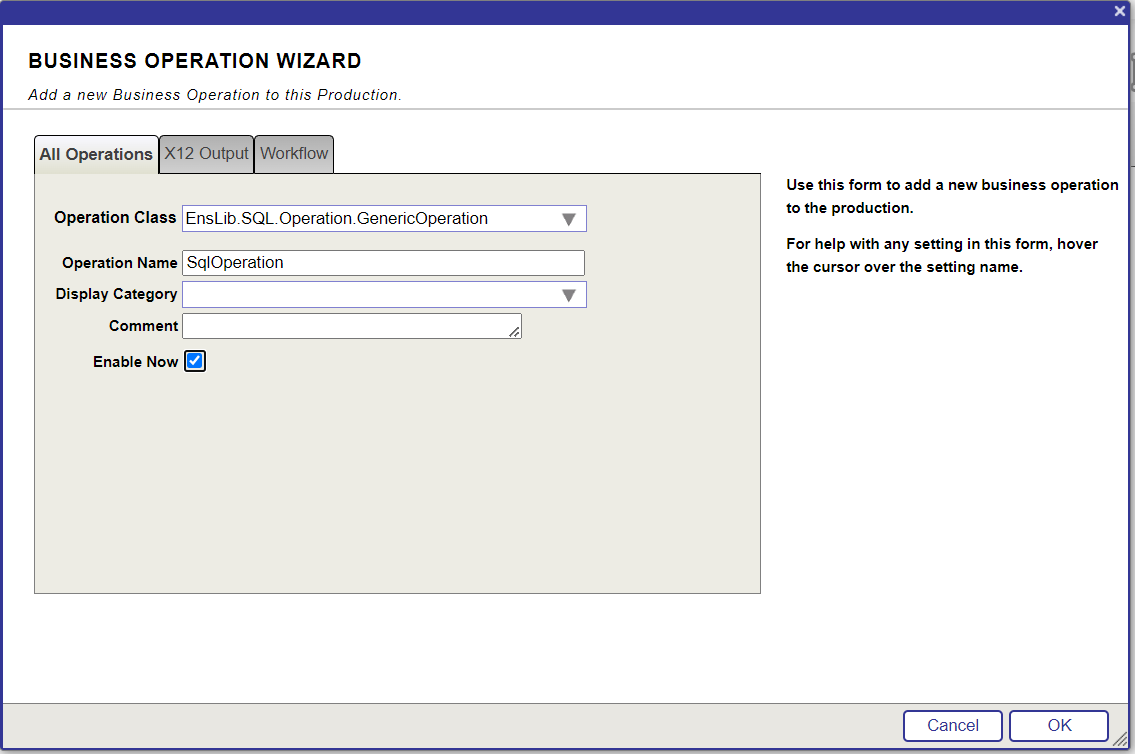
Ensuite, nous allons créer un nouveau serveur FHIR.
Cliquez sur le bouton Server Configuration (Configuration du Serveur).
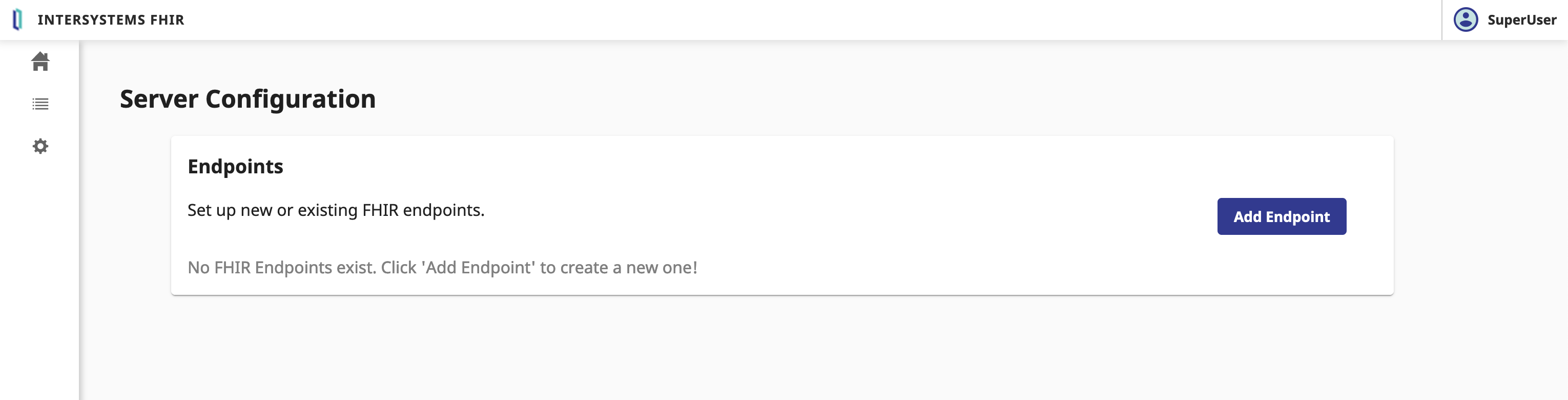
6.1. Création un nouveau serveur FHIR
Dans le formulaire Configuration du serveur, nous devons remplir les paramètres suivants:
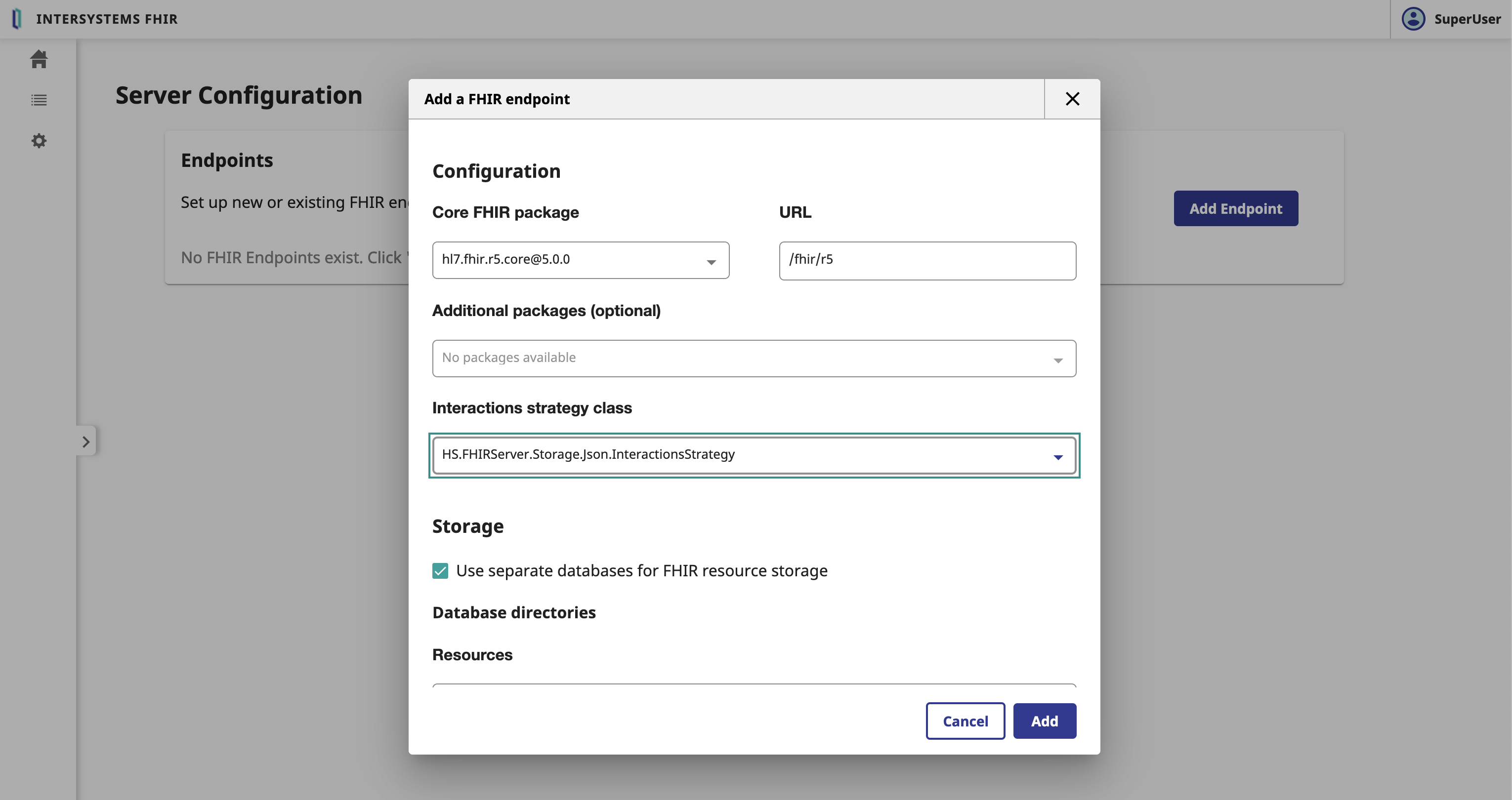
- Paquet de base FHIR: Le paquet de base FHIR à utiliser pour le serveur FHIR
- Adresse URL: L'URL du serveur FHIR
- Stratégie d'interactions: La stratégie d'interactions à utiliser pour le serveur FHIR
- FHIR.Python.InteractionsStrategy
- ⚠️ AVERTISSEMENT ⚠️ : Pas comme sur la photo, il faut sélectionner la stratégie d'interactions
FHIR.Python.InteractionsStrategy.
Cliquer sur le bouton Add.
Cela peut prendre quelques minutes. 🕒 Allons prendre un café. ☕️
Félicitations, nous avons maintenant créé le serveur FHIR. 🥳
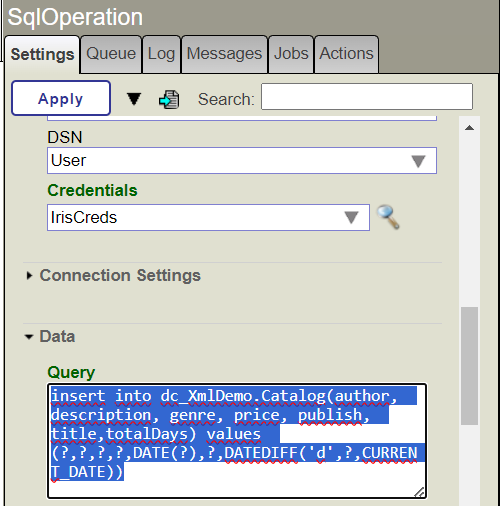
6.2. Liaison entre le serveur FHIR et le serveur d'autorisation OAuth2
Sélectionnez le serveur FHIR et descendez jusqu'au bouton Edit (modifier).
Dans le formulaire Serveur FHIR , nous devons remplir les paramètres suivants:
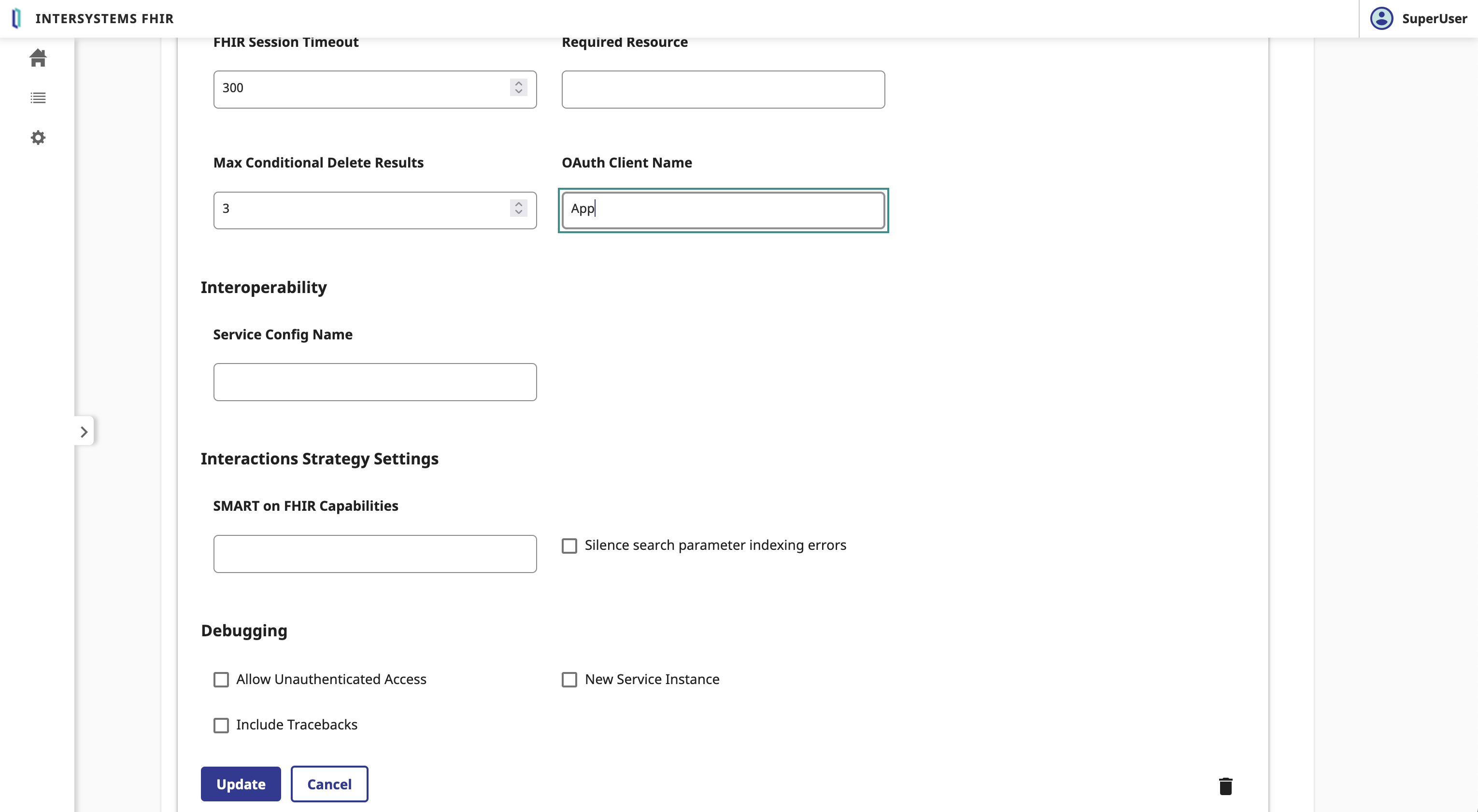
- Nom du Client OAuth2: Le nom du Client
Cliquez sur le bouton Save (sauvegarder).
Félicitations, nous avons maintenant lié le serveur FHIR au serveur d'autorisation OAuth2. 🥳
6.3. Test du serveur FHIR
Pour tester le serveur FHIR, vous pouvez utiliser la commande suivante:
GET https://localhost:4443/fhir/r5/Patient
Sans l'en-tête Authorization, vous obtiendrez une réponse 401 Unauthorized.
Pour authentifier la demande, vous devez ajouter l'en-tête Authorization avec le jeton Bearer.
Pour ce faire, demandons un jeton au serveur d'autorisation OAuth2.
POST https://localhost:4443/oauth2/token
Content-Type: application/x-www-form-urlencoded
Authorization: Basic <client_id>:<client_secret>
grant_type=client_credentials&scope=user/Patient.read&aud=https://localhost:4443/fhir/r5
Vous obtiendrez une réponse 200 OK avec le jeton d'accès access_token et le type de jeton token_type.
Maintenant, vous pouvez utiliser jeton d'accès access_token pour authentifier la demande auprès du serveur FHIR.
GET https://localhost:4443/fhir/r5/Patient
Authorization: Bearer <access_token>
Accept: application/fhir+json
Félicitations, vous avez maintenant authentifié la demande sur le serveur FHIR. 🥳
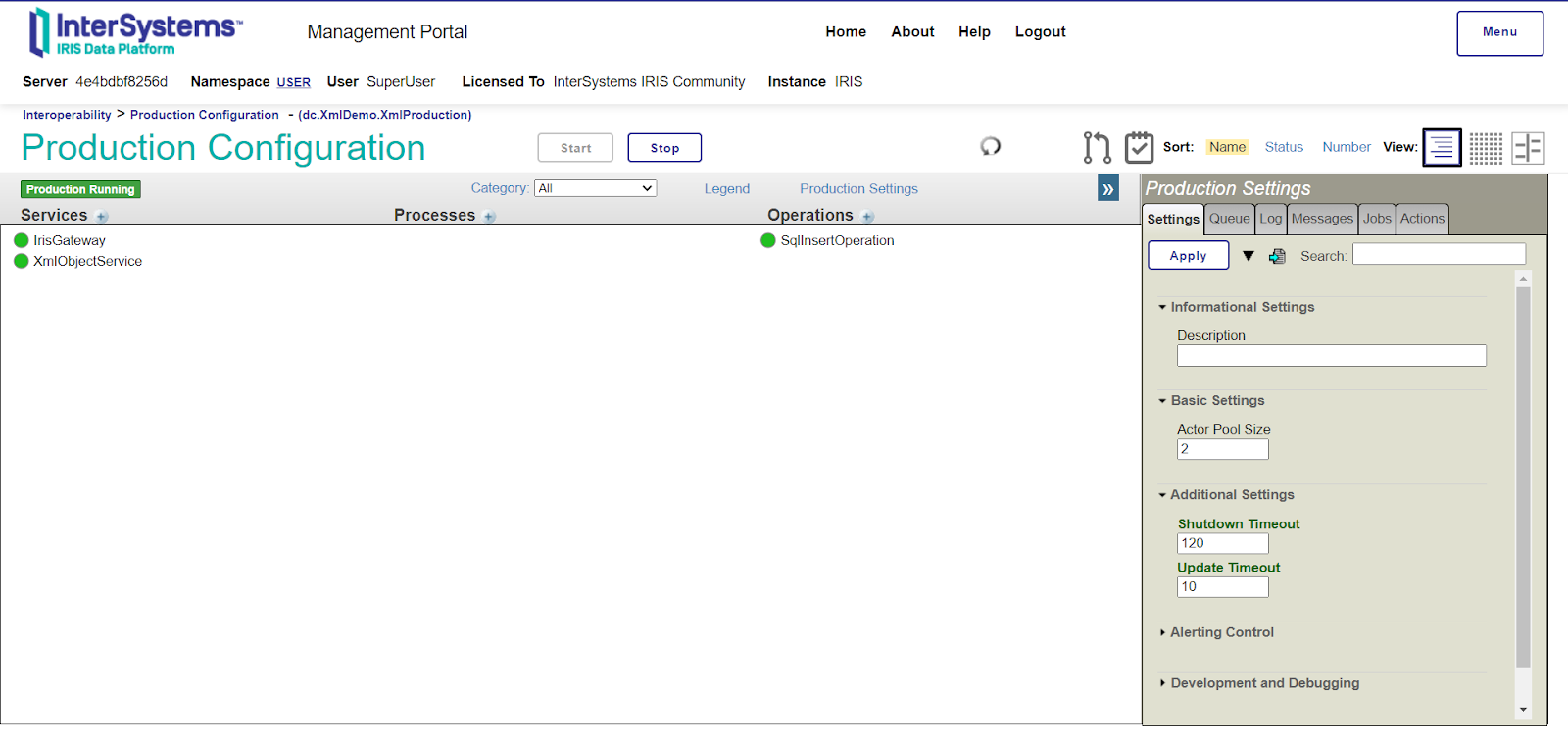
7. Filtrage des ressources FHIR avec "InterSystems IRIS for Health"
Eh bien, nous aborderont maintenant un grand sujet.
Le but de ce sujet sera de mettre en place les capacités d'interopérabilité d'IRIS for Health entre le serveur FHIR et l'application cliente.
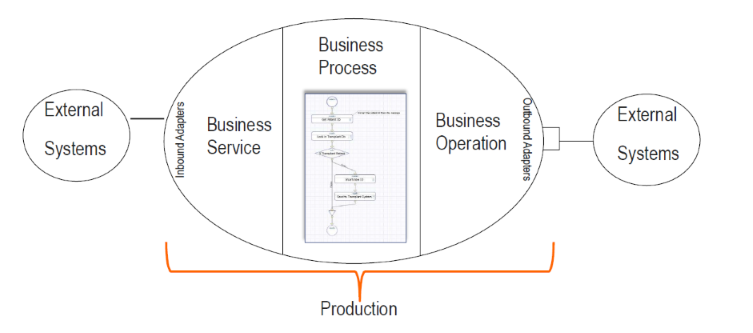
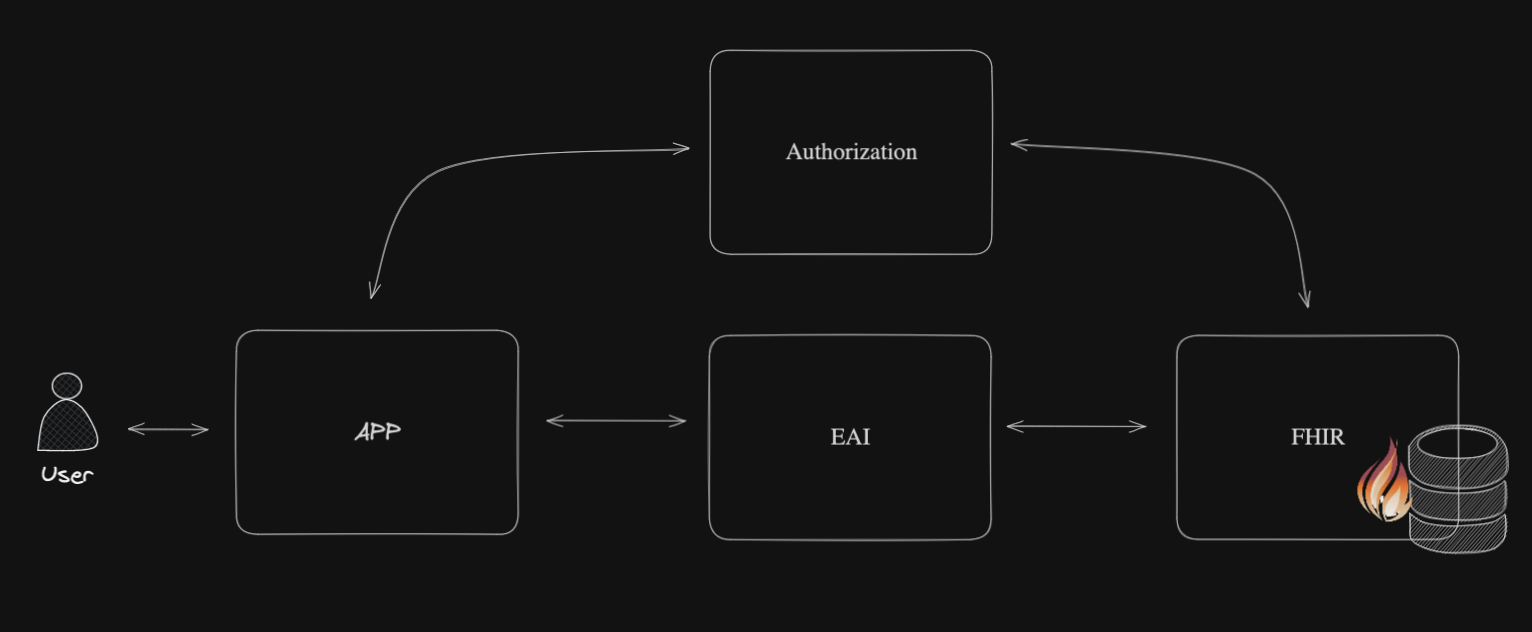
Ci-dessous, une vue macro de l'architecture:
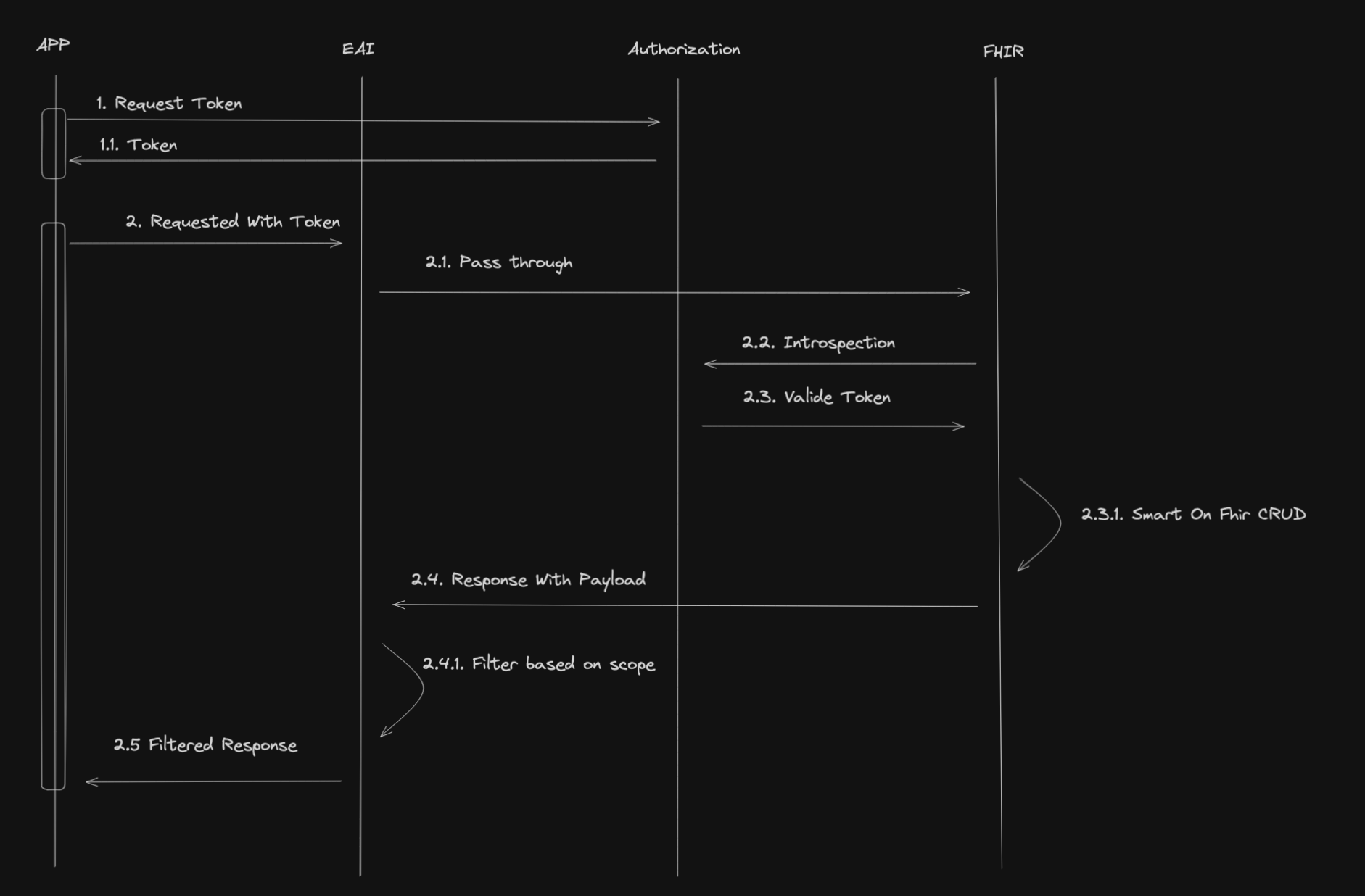
Et voici le flux de travail:
Ce que nous remarquons ici, c'est que l'EAI (capacités d'interopérabilité d'IRIS for Health) servira de chemin d'accès pour les demandes entrantes vers le serveur FHIR.
Il filtrera la réponse du serveur FHIR en fonction des champs d'application et enverra la réponse filtrée à l'application cliente.
Avant d'aller plus loin, permettez-moi de vous présenter rapidement les capacités d'interopérabilité d'IRIS for Health.
7.1. Cadre d'Interopérabilité
Il s'agit du cadre IRIS Framework.
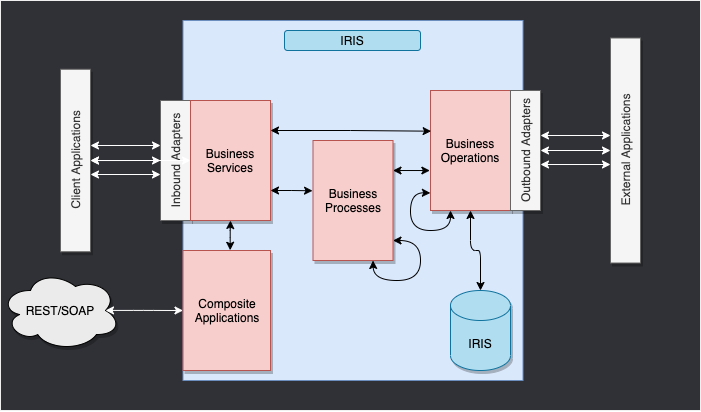
L'objectif de ce cadre est de fournir un moyen de relier différents systèmes entre eux.
Nous avons 4 composants principaux:
- Services métiers: Le point d'entrée du cadre. Il reçoit la demande entrante et l'envoie à la production.
- Processus métier: Le flux de travail du cadre. Il traite la demande entrante et l'envoie à l'opération métier.
- Operations métier: Le point de sortie du cadre. Il traite la demande entrante et l'envoie au service métier.
- Messages: Les données du cadre. Elles contiennent la requête entrante et la réponse sortante.
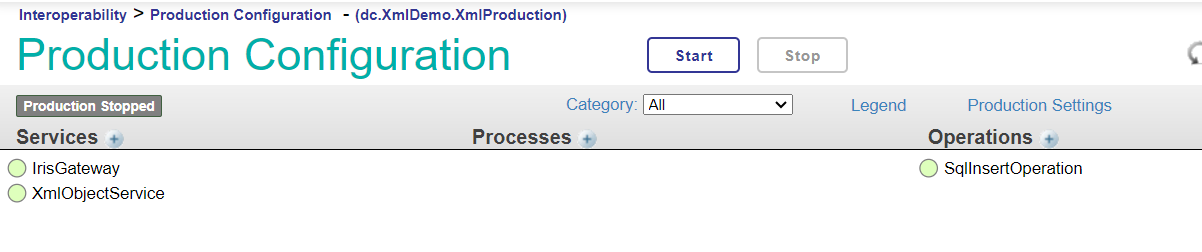
Pour cette session de formation, nous utiliserons les composants suivants:
- Un service métier
Business Service pour recevoir la demande de l'application cliente. - Un processus métier
Business Process pour filtrer la réponse du serveur FHIR en fonction des péramètres. - Une opération métier
Business Operation pour envoyer les messages au serveur FHIR.
Pour cette session de formation, nous utiliserons une production d'interopérabilité pré-construite.
Nous nous concentrerons uniquement sur le processus métier Business Process permettant de filtrer la réponse du serveur FHIR en fonction des périmètres.
7.2. Installation de l'IoP
Pour cette partie, nous utiliserons l'outil IoP. IoP signifie l'Interopérabilité sur Python..
Vous pouvez installer l'outil IoP en suivant les instructions du référentiel de l'IoP
L'outil IoP est pré-installé dans l'environnement de formation.
Connectez-vous au conteneur en cours d'exécution:
docker exec -it formation-fhir-python-iris-1 bash
Et exécutez la commande suivante:
iop --init
Ainsi l'IoP sera installée sur le conteneur IRIS for Health.
7.3. Création de la Production d'Interopérabilité
Toujours dans le conteneur, exécutez la commande suivante:
iop --migrate /irisdev/app/src/python/EAI/settings.py
Ainsi, la production d'interopérabilité sera créée.
Vous pouvez maintenant accéder à la production d'interopérabilité à l'adresse URL suivante:
http://localhost:8089/csp/healthshare/eai/EnsPortal.ProductionConfig.zen?$NAMESPACE=EAI&$NAMESPACE=EAI&
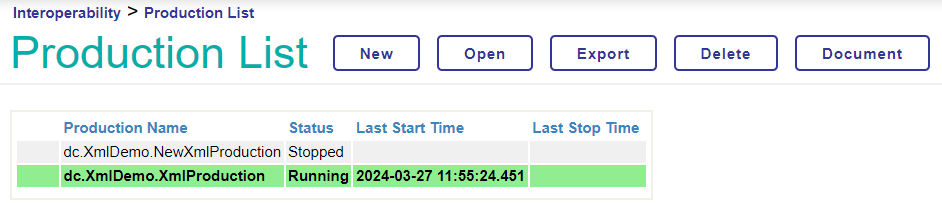
Vous pouvez maintenant lancer la production.
Félicitations, vous avez créé la production d'interopérabilité. 🥳
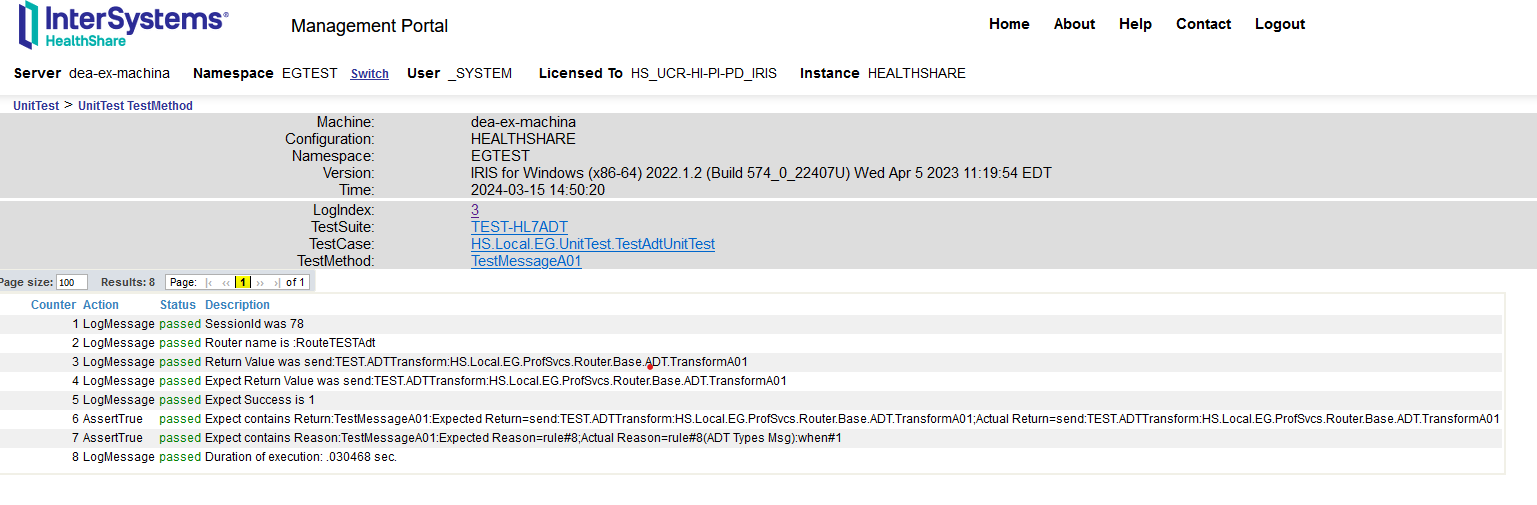
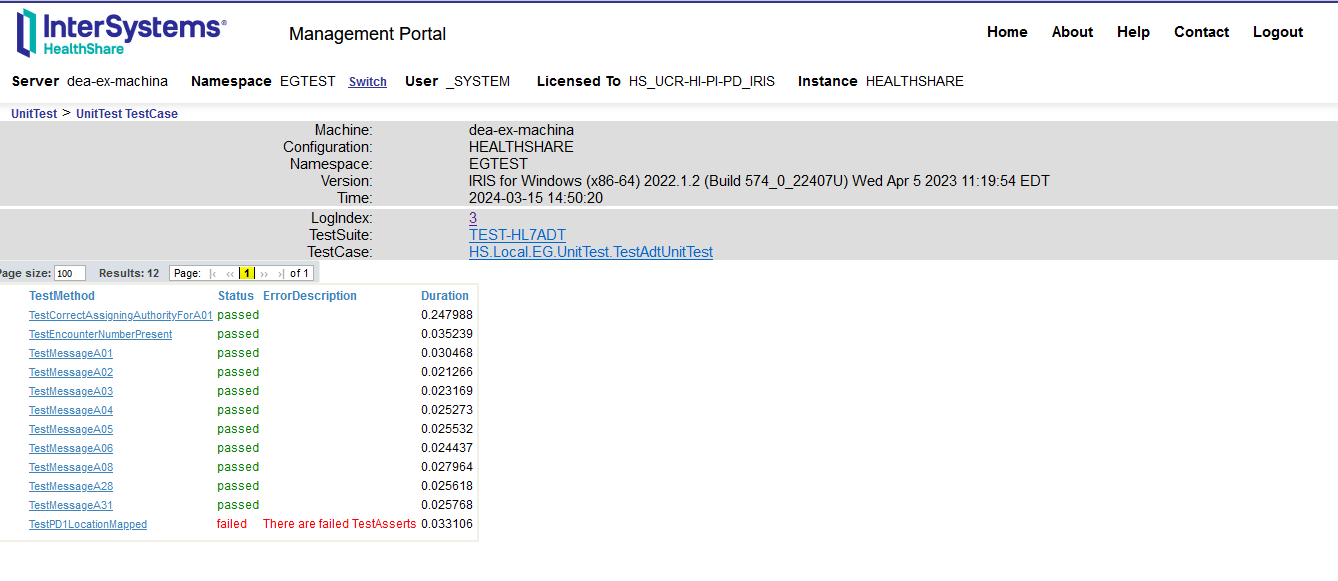
7.3.1. Test de la Production d'Interopérabilité
Obtenez un jeton du serveur d'autorisation OAuth2.
POST https://localhost:4443/oauth2/token
Content-Type: application/x-www-form-urlencoded
Authorization : Basic <client_id>:<client_secret>
grant_type=client_credentials&scope=user/Patient.read&aud=https://webgateway/fhir/r5
⚠️ AVERTISSEMENT ⚠️ : we change the aud parameter to the URL of the Web Gateway to expose the FHIR server over HTTPS.
Faites passer un patient par la production d'interopérabilité.
GET https://localhost:4443/fhir/Patient
Authorization : Bearer <Token>
Accept: application/fhir+json
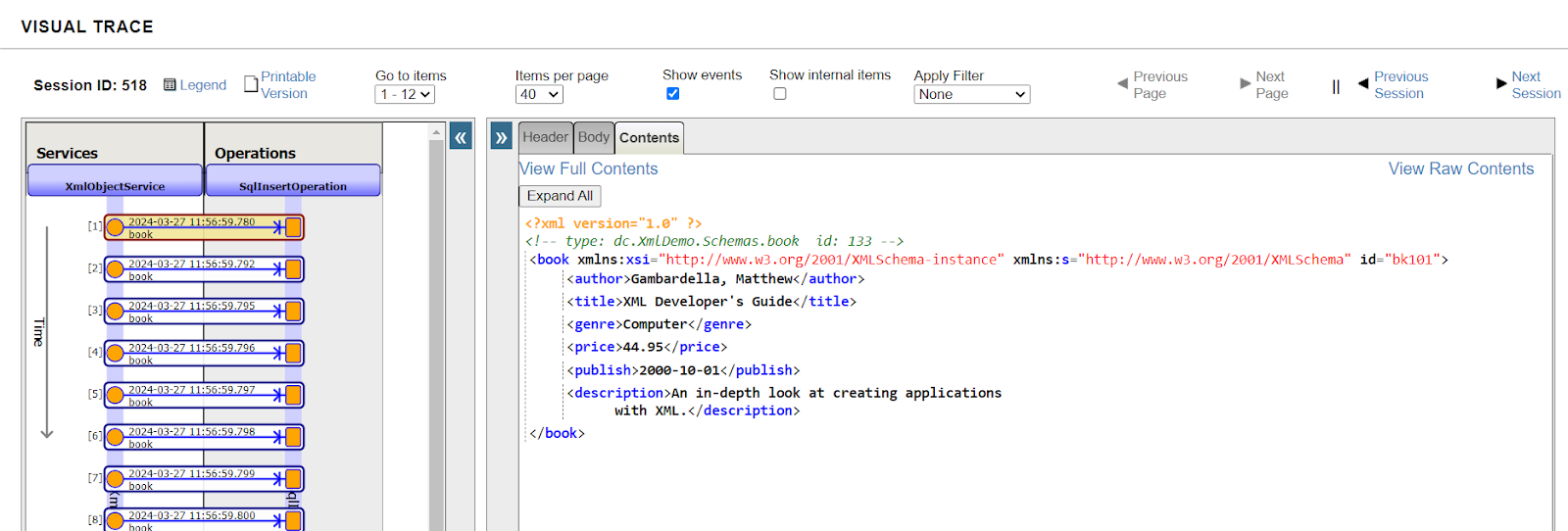
Vous pouvez voir la trace de la requête dans la production d'interopérabilité.
http://localhost:8089/csp/healthshare/eai/EnsPortal.MessageViewer.zen?SOURCEORTARGET=Python.EAI.bp.MyBusinessProcess
7.4. Modification du processus métier
Tout le code pour le processus métier Business Process se trouve dans le fichier suivant : https://github.com/grongierisc/formation-fhir-python/blob/main/src/python/EAI/bp.py
Pour cette session de formation, nous adopterons une approche de développement piloté par les tests, TTD (Test Driven Development)..
Tous les tests pour le processus métier Business Process se trouve dans le fichier suivant : https://github.com/grongierisc/formation-fhir-python/blob/main/src/python/tests/EAI/test_bp.py
7.4.1. Préparation de votre environnement de développement
Pour préparer votre environnement de développement, il faut créer un environnement virtuel.
python3 -m venv .venv
source .venv/bin/activate
pip install -r requirements.txt
7.4.2. Exécution des tests
Pour exécuter les tests, vous pouvez utiliser la commande suivante:
pytest
Les tests échouent.
7.4.3. Mise en œuvre du code
Nous avons 4 fonctions à mettre en œuvre:
check_tokenon_fhir_requestfilter_patient_resourcefilter_resources
Vous pouvez mettre en œuvre le code dans https://github.com/grongierisc/formation-fhir-python/blob/main/src/python/EAI/bp.py file.
7.4.3.1. check_token
Cette fonction vérifie si le jeton est valide et si le champ d'application contient le périmètre VIP.
Si le jeton est valide et que le périmètre contient le périmètre VIP, la fonction renvoie True (vrai), sinon elle renvoie False (faux).
Nous utiliserons la bibliothèque jwt pour décoder le jeton.
Cliquez pour voir le code
def check_token(self, token:str) -> bool:
# décoder le jeton
try:
decoded_token= jwt.decode(token, options={"verify_signature": False})
except jwt.exceptions.DecodeError:
return False
# vérifier si le jeton est valide
if 'VIP' in decoded_token['scope']:
return True
else:
return False
7.4.3.2. filter_patient_resource
Cette fonction filtrera la ressource patient.
Cela supprimera les champ name, address, telecom and birthdate (nom, adresse, télécom et date de naissance) de la ressource patient..
La fonction renverra la ressource patient filtrée sous forme de chaîne.
Nous utiliserons la bibliothèque fhir.resources pour analyser la ressource patient.
Notez la signature de la fonction.
La fonction prend une chaîne en entrée et renvoie une chaîne comme le résultat.
Nous devons donc analyser la chaîne d'entrée en un objet fhir.resources.patient.Patient, puis analyser l'objet fhir.resources.patient.Patient en une chaîne.
Cliquez pour voir le code
def filter_patient_resource(self, patient_str:str) -> str:
# filtrer le patient
p = patient.Patient(**json.loads(patient_str))
# supprimer le nom
p.name = []
# supprimer l'adresse
p.address = []
# supprimer le télécom
p.telecom = []
# supprimer la date de naissance
p.birthDate = None
return p.json()
7.4.3.3. filter_resources
Cette fonction filtrera les ressources.
Nous devons vérifier le type de ressource et filtrer la ressource en fonction du type de ressource.
Si le type de ressource est Bundle (Paquet), nous devons filtrer toutes les entrées du paquet qui sont de type Patient.
Si le type de ressource est Patient, nous devons filtrer la resource de type patient.
La fonction renverra la ressource filtrée sous forme de chaîne.
Nous utiliserons la bibliothèque fhir.resources pour analiser la ressource.
Cliquez pour voir le code
def filter_resources(self, resource_str:str) -> str:
# analyser le payload
payload_dict = json.loads(resource_str)
# quel est le type de ressource?
resource_type = payload_dict['resourceType'] if 'resourceType' in payload_dict else 'None'
self.log_info('Resource type: ' + resource_type)
# c'est un paquet?
if resource_type == 'Bundle':
obj = bundle.Bundle(**payload_dict)
# filtrer le paquet
for entry in obj.entry:
if entry.resource.resource_type == 'Patient':
self.log_info('Filtering a patient')
entry.resource = patient.Patient(**json.loads(self.filter_patient_resource(entry.resource.json())))
elif resource_type == 'Patient':
# filtrer le patient
obj = patient.Patient(**json.loads(self.filter_patient_resource(resource_str)))
else:
return resource_str
return obj.json()
7.4.3.4. on_fhir_request
Cette fonction sera le point d'entrée du processus métier Business Process.
Elle recevra la demande du service métier Business Service, vérifiera le jeton, filtrera la réponse du serveur FHIR en fonction des champs d'application et enverra la réponse filtrée au service métier Business Service.
La fonction renverra la réponse du serveur FHIR.
Nous utiliserons la bibliothèque iris pour envoyer la requête au serveur FHIR.
Le message sera un objet iris.HS.FHIRServer.Interop.Request.
Cet objet contient la requête au serveur FHIR.
Il consiste des composant suivants: Method, URL, Headers et Payload.
Pour vérifier le jeton, nous utiliserons la fonction check_token et pour obtenir un jeton, il faut utiliser l'en-tête USER:OAuthToken.
Pour filtrer la reponse, nous utiliserons la fonction filter_resources et pour lire la réponse du serveur FHIR, nous utiliserons QuickStream.
Cliquez pour voir le code
def on_fhir_request(self, request:'iris.HS.FHIRServer.Interop.Request'):
# Faire quelque chose avec la requête
self.log_info('Received a FHIR request')
# La passer à la cible
rsp = self.send_request_sync(self.target, request)
# Essayer d'obtenir le jeton de la requête
token = request.Request.AdditionalInfo.GetAt("USER:OAuthToken") or ""
# Faire quelque chose avec la réponse
if self.check_token(token):
self.log_info('Filtering the response')
# Filtrer la réponse
payload_str = self.quick_stream_to_string(rsp.QuickStreamId)
# Si le payload est vide, renvoyer la réponse
if payload_str == '':
return rsp
filtered_payload_string = self.filter_resources(payload_str)
if filtered_payload_string == '':
return rsp
# écrire la chaîne json dans un flux rapide
quick_stream = self.string_to_quick_stream(filtered_payload_string)
# renvoyer la réponse
rsp.QuickStreamId = quick_stream._Id()
return rsp
7.4.4. Exécution des tests
Pour exécuter les tests, vous pouvez utiliser la commande suivante:
pytest
Les tests passent. 🥳
Vous pouvez maintenant tester le processus métier Business Process avec la production d'interopérabilité.
8. Création de l'opération personnalisée
Dernière partie de la session de formation. 🏁
Nous allons créer une opération personnalisée sur le serveur FHIR.
L'opération personnalisée sera opération de fusion de patients Patient et le résultat sera la différence entre les deux patients.
exemple:
POST https://localhost:4443/fhir/r5/Patient/1/$merge
Authorization : Bearer <Token>
Accept: application/fhir+json
Content-Type: application/fhir+json
{
"resourceType": "Patient",
"id": "2",
"meta": {
"versionId": "2"
}
}
La réponse sera la différence entre les 2 patients.
{
"values_changed": {
"root['address'][0]['city']": {
"new_value": "fdsfd",
"old_value": "Lynnfield"
},
"root['meta']['lastUpdated']": {
"new_value": "2024-02-24T09:11:00Z",
"old_value": "2024-02-28T13:50:27Z"
},
"root['meta']['versionId']": {
"new_value": "1",
"old_value": "2"
}
}
}
Avant de poursuivre, permettez-moi de présenter rapidement l'opération personnalisée sur le serveur FHIR..
L'opération de personnalisation se décline en trois types:
- Opération d'instance: L'opération est effectuée sur une instance spécifique d'une ressource.
- Opération de type: L'opération est effectuée sur un type de ressource.
- Opération de système: L'opération est effectuée sur le serveur FHIR.
Pour cette session de formation, pour la création de l'opération personnalisée nous utiliserons l'Instance Operation.
8.1. Codage de l'opération personnalisée
Une opération personnalisée doit hériter de la classe OperationHandler à partir du module FhirInteraction.
Voici la signature de la classe OperationHandler:
class OperationHandler(object):
@abc.abstractmethod
def add_supported_operations(self,map:dict) -> dict:
"""
@API Enumerate the name and url of each Operation supported by this class
@Output map : A map of operation names to their corresponding URL.
Example:
return map.put("restart","http://hl7.org/fhir/OperationDefinition/System-restart")
"""
@abc.abstractmethod
def process_operation(
self,
operation_name:str,
operation_scope:str,
body:dict,
fhir_service:'iris.HS.FHIRServer.API.Service',
fhir_request:'iris.HS.FHIRServer.API.Data.Request',
fhir_response:'iris.HS.FHIRServer.API.Data.Response'
) -> 'iris.HS.FHIRServer.API.Data.Response':
"""
@API Process an Operation request.
@Input operation_name : The name of the Operation to process.
@Input operation_scope : The scope of the Operation to process.
@Input fhir_service : The FHIR Service object.
@Input fhir_request : The FHIR Request object.
@Input fhir_response : The FHIR Response object.
@Output : The FHIR Response object.
"""
Comme nous l'avons fait dans la partie précédente, nous utiliserons une approche TTD (Développement piloté par les tests).
Tous les tests pour le Processus d'Affaires sont dans ce fichier : https://github.com/grongierisc/formation-fhir-python/blob/main/src/python/tests/FhirInteraction/test_custom.py
8.1.1. add_supported_operations
Cette fonction ajoute l'opération de fusion de patients Patient aux opérations prises en charge.
La fonction retournera un dictionnaire avec le nom de l'opération et l'adresse URL de l'opération.
Sachez que le dictionnaire d'entrée peut être vide.
Le résultat attendu est le suivant:
{
"resource":
{
"Patient":
[
{
"name": "merge",
"definition": "http://hl7.org/fhir/OperationDefinition/Patient-merge"
}
]
}
}
This json document will be added to the CapabilityStatement of the FHIR server.
Cliquez pour voir le code
def add_supported_operations(self,map:dict) -> dict:
"""
@API Enumerate the name and url of each Operation supported by this class
@Output map : A map of operation names to their corresponding URL.
Example:
return map.put("restart","http://hl7.org/fhir/OperationDefinition/System-restart")
"""
# verify the map has attribute resource
if not 'resource' in map:
map['resource'] = {}
# verify the map has attribute patient in the resource
if not 'Patient' in map['resource']:
map['resource']['Patient'] = []
# add the operation to the map
map['resource']['Patient'].append({"name": "merge" , "definition": "http://hl7.org/fhir/OperationDefinition/Patient-merge"})
return map
8.1.2. process_operation
Cette fonction traitera l'opération de fusion Patient.
La fonction renverra la différence entre les 2 patients.
Nous allons utiliser la bibliothèque deepdiff pour obtenir la différence entre les 2 patients.
Les paramètres d'entrée sont les suivants:
operation_name: Le nom de l'opération à traiter.operation_scope: Le périmètre de l'opération à traiter.body: Le corps de l'operation.fhir_service: L'objet FHIR Service.
- fhir_service.interactions.Read
- Une méthode pour lire une ressource à partir du serveur FHIR.
- Les paramètres d'entrée sont les suivants:
resource_type: Le type de la ressource à lire.resource_id: L'identifiant de la ressource à lire.
- Le résultat est un objet
%DynamicObject
fhir_request: L'objet de requête FHIR Request..
- fhir_request.Json
- Propriété permettant d'obtenir le corps de la requête, c'est un objet
%DynamicObject
fhir_response: L'objet de réponse FHIR Response.
- fhir_response.Json
- Propriété permettant de définir le corps de la réponse, c'est un objet
%DynamicObject.
%DynamicObject est une classe permettant de manipuler des objets JSON.
C'est la même chose qu'un dictionnaire Python mais pour ObjectScript.
Téléchargement d'objet JSON:
json_str = fhir_request.Json._ToJSON()
json_obj = json.loads(json_str)
Définition d'objet JSON:
json_str = json.dumps(json_obj)
fhir_response.Json._FromJSON(json_str)
Assurez-vous que la fonction de traitement process_operation est appelée pour vérifier si operation_name est merge, operation_scope est Instance et RequestMethod est POST.
Cliquez pour voir le code
def process_operation(
self,
operation_name:str,
operation_scope:str,
body:dict,
fhir_service:'iris.HS.FHIRServer.API.Service',
fhir_request:'iris.HS.FHIRServer.API.Data.Request',
fhir_response:'iris.HS.FHIRServer.API.Data.Response'
) -> 'iris.HS.FHIRServer.API.Data.Response':
"""
@API Process an Operation request.
@Input operation_name : The name of the Operation to process.
@Input operation_scope : The scope of the Operation to process.
@Input fhir_service : The FHIR Service object.
@Input fhir_request : The FHIR Request object.
@Input fhir_response : The FHIR Response object.
@Output : The FHIR Response object.
"""
if operation_name == "merge" and operation_scope == "Instance" and fhir_request.RequestMethod == "POST":
# obtenir la ressource primaire
primary_resource = json.loads(fhir_service.interactions.Read(fhir_request.Type, fhir_request.Id)._ToJSON())
# obtenir la ressource secondaire
secondary_resource = json.loads(fhir_request.Json._ToJSON())
# retrouver la différence entre les deux ressources
# utiliser deepdiff pour obtenir la différence entre les deux ressources
diff = DeepDiff(primary_resource, secondary_resource, ignore_order=True).to_json()
# créer un nouvel %DynamicObject pour stocker le résultat
result = iris.cls('%DynamicObject')._FromJSON(diff)
# mettre le résultat dans la réponse
fhir_response.Json = result
return fhir_response
à tester :
POST https://localhost:4443/fhir/r5/Patient/1/$merge
Authorization : Bearer <Token>
Accept: application/fhir+json
{
"resourceType": "Patient",
"id": "2",
"meta": {
"versionId": "2"
}
}
Vous obtiendrez la différence entre les 2 patients.
{
"values_changed": {
"root['address'][0]['city']": {
"new_value": "fdsfd",
"old_value": "Lynnfield"
},
"root['meta']['lastUpdated']": {
"new_value": "2024-02-24T09:11:00Z",
"old_value": "2024-02-28T13:50:27Z"
},
"root['meta']['versionId']": {
"new_value": "1",
"old_value": "2"
}
}
}
Félicitations, vous avez créé l'opération personnalisée. 🥳
9. Trucs et Astuces
9.1. Journal de Csp
In %SYS
set ^%ISCLOG = 5
zw ^ISCLOG
9.2. Solution de BP
Cliquez pour voir le code
from grongier.pex import BusinessProcess
import iris
import jwt
import json
from fhir.resources import patient, bundle
class MyBusinessProcess(BusinessProcess):
def on_init(self):
if not hasattr(self, 'target'):
self.target = 'HS.FHIRServer.Interop.HTTPOperation'
return
def on_fhir_request(self, request:'iris.HS.FHIRServer.Interop.Request'):
# Faire quelque chose avec la requête
self.log_info('Received a FHIR request')
# La passer à la cible
rsp = self.send_request_sync(self.target, request)
# Essayez d'obtenir le jeton de la requête
token = request.Request.AdditionalInfo.GetAt("USER:OAuthToken") or ""
# Faire quelque chose avec la réponse
if self.check_token(token):
self.log_info('Filtering the response')
# Filtrer la reponse
payload_str = self.quick_stream_to_string(rsp.QuickStreamId)
# si le payload est vide, renvoyer la réponse
if payload_str == '':
return rsp
filtered_payload_string = self.filter_resources(payload_str)
if filtered_payload_string == '':
return rsp
# écrire la chaîne json dans un flux rapide
quick_stream = self.string_to_quick_stream(filtered_payload_string)
# renvoyer la réponse
rsp.QuickStreamId = quick_stream._Id()
return rsp
def check_token(self, token:str) -> bool:
# décoder le jeton
decoded_token= jwt.decode(token, options={"verify_signature": False})
# vérifier si le jeton est valide
if 'VIP' in decoded_token['scope']:
return True
else:
return False
def quick_stream_to_string(self, quick_stream_id) -> str:
quick_stream = iris.cls('HS.SDA3.QuickStream')._OpenId(quick_stream_id)
json_payload = ''
while quick_stream.AtEnd == 0:
json_payload += quick_stream.Read()
return json_payload
def string_to_quick_stream(self, json_string:str):
quick_stream = iris.cls('HS.SDA3.QuickStream')._New()
# écrire la chaîne json dans le payload
n = 3000
chunks = [json_string[i:i+n] for i in range(0, len(json_string), n)]
for chunk in chunks:
quick_stream.Write(chunk)
return quick_stream
def filter_patient_resource(self, patient_str:str) -> str:
# filtrer le patient
p = patient.Patient(**json.loads(patient_str))
# supprimer le nom
p.name = []
# supprimer l'adresse
p.address = []
# supprimer le télécom
p.telecom = []
# supprimer la date de naissance
p.birthDate = None
return p.json()
def filter_resources(self, resource_str:str) -> str:
# analyser le payload
payload_dict = json.loads(resource_str)
# quel est le type de ressource?
resource_type = payload_dict['resourceType'] if 'resourceType' in payload_dict else 'None'
self.log_info('Resource type: ' + resource_type)
# c'est un paquet?
if resource_type == 'Bundle':
obj = bundle.Bundle(**payload_dict)
# filrer le paquet
for entry in obj.entry:
if entry.resource.resource_type == 'Patient':
self.log_info('Filtering a patient')
entry.resource = patient.Patient(**json.loads(self.filter_patient_resource(entry.resource.json())))
elif resource_type == 'Patient':
# filtrer le patient
obj = patient.Patient(**json.loads(self.filter_patient_resource(resource_str)))
else:
return resource_str
return obj.json()
















.jpg)
.png)
.png)
.png)
.png)
.png)


.png)






.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png) ):
):.png)
.png)
.png)
.png)



") Référence:
Référence: