Nous avons publié IPM 0.9.0. J'ai déjà évoqué une partie de l'historique et du raisonnement ici ; pour résumer, il s'agit d'une version importante pour deux raisons : elle représente une réunification attendue depuis longtemps de notre travail interne et communautaire autour de la gestion des paquets ObjectScript centrée sur IRIS, et elle présente certaines incompatibilités rétroactives. Il existe plusieurs incompatibilités rétroactives nécessaires dans notre feuille de route, et nous les avons regroupées ; ce ne sera pas une nouvelle norme.
Dans le paysage actuel des données, les activités commerciales sont confrontées à différents défis. L'un d'entre eux consiste à réaliser des analyses à partir d'une couche de données unifiée et harmonisée, accessible à tous les utilisateurs. Une couche capable de fournir les mêmes réponses aux mêmes questions, indépendamment du dialecte ou de l'outil utilisé. La plate-forme de données InterSystems IRIS répond à cette question en ajoutant la solution 'Adaptive Analytics' (Analyse adaptative) qui peut fournir cette couche sémantique unifiée. Il y a beaucoup d'articles dans DevCommunity sur l'utilisation de cette couche sémantique via des outils décisionnels. Cet article couvrira la partie concernant la façon de l'utiliser avec l'IA et également la façon d'obtenir des informations en retour. Allons-y étape par étape...
Qu'est-ce que la solution 'Adaptive Analytics'?
Vous pouvez facilement trouver une définition sur le site web de la Communauté de développeurs. En quelques mots, elle peut fournir des données sous une forme structurée et harmonisée à divers outils de votre choix pour une utilisation et une analyse ultérieures. Elle fournit les mêmes structures de données à différents outils décisionnels. Mais... elle peut également fournir les mêmes structures de données à vos outils IA/ML!
Adaptive Analytics a un composant supplémentaire appelé AI-Link qui construit ce pont entre l'IA et d'informatique décisionnelle.
Qu'est-ce que AI-Link exactement?
Il s'agit d'un composant Python conçu pour permettre une interaction programmatique avec la couche sémantique dans le but de rationaliser les étapes clés du flux de travail de l'apprentissage automatique (ML) (par exemple, l'ingénierie des fonctionnalités).
Avec AI-Link, vous pouvez:
- accéder de manière programmatique aux fonctionnalités de votre modèle de données analytiques;
- faire des requêtes, explorer les dimensions et les mesures;
- alimenter des pipelines de ML; ... et renvoyer les résultats vers votre couche sémantique pour qu'ils soient à nouveau utilisés par d'autres (par exemple, par le biais de Tableau ou d'Excel).
Comme il s'agit d'une bibliothèque Python, elle peut être utilisée dans n'importe quel environnement Python. Y compris les Notebooks. Dans cet article, je vais donner un exemple simple pour atteindre une solution d'analyse adaptative à partir d'un Notebook Jupyter avec l'aide d'AI-Link.
Voici le référentiel git qui aura le Notebook complet à titre d'exemple : https://github.com/v23ent/aa-hands-on
**Conditions préalables **
Les étapes suivantes supposent que vous ayez rempli les conditions préalables ci-dessous:
- La solution 'Adaptive Analytics' est en place et fonctionne (avec IRIS Data Platform en tant qu'entrepôt de données).
- Jupyter Notebook est opérationnel
- La connexion entre 1. et 2. peut être établie
Étape 1: Configuration
Tout d'abord, installons les composants nécessaires dans notre environnement. Ainsi, nous téléchargerons quelques paquets nécessaires au bon déroulement des étapes suivantes. 'atscale' - c'est notre paquetage principal pour se connecter 'prophet' - c'est le paquet dont nous aurons besoin pour faire des prédictions.
pip install atscale prophet
Ensuite, nous devons importer des classes clés représentant certains concepts clés de notre couche sémantique. Client - c'est la classe que nous utiliserons pour établir une connexion avec Adaptive Analytics; Project - c'est la classe qui représente les projets à l'intérieur d'Adaptive Analytics; DataModel - c'est la classe qui représentera notre cube virtuel;
from atscale.client import Client
from atscale.data_model import DataModel
from atscale.project import Project
from prophet import Prophet
import pandas as pd
Étape 2: Connexion
Maintenant, nous devrions être prêts à établir une connexion avec notre source de données.
client = Client(server='http://adaptive.analytics.server', username='sample')
client.connect()
Continuez et spécifiez les détails de connexion de votre instance d'Adaptive Analytics. Lorsque l'on vous demande l'organisation, répondez dans la boîte de dialogue et entrez votre mot de passe de l'instance AtScale.
Une fois la connexion établie, vous devrez sélectionner votre projet dans la liste des projets publiés au serveur. Vous obtiendrez la liste des projets sous la forme d'une invite interactive et la réponse devrait être l'identifiant entier du projet. Le modèle de données est ensuite sélectionné automatiquement s'il est le seul.
project = client.select_project()
data_model = project.select_data_model()
Étape 3: Explorez votre jeu de données
Il existe un certain nombre de méthodes préparées par AtScale dans la bibliothèque de composants AI-Link. Elles permettent d'explorer votre catalogue de données, d'interroger les données et même d'ingérer des données en retour. La documentation d'AtScale a une référence API complète décrivant tout ce qui est disponible. Voyons d'abord quel est notre jeu de données en appelant quelques méthodes de data_model :
data_model.get_features()
data_model.get_all_categorical_feature_names()
data_model.get_all_numeric_feature_names()
Le résultat devrait ressembler à ceci
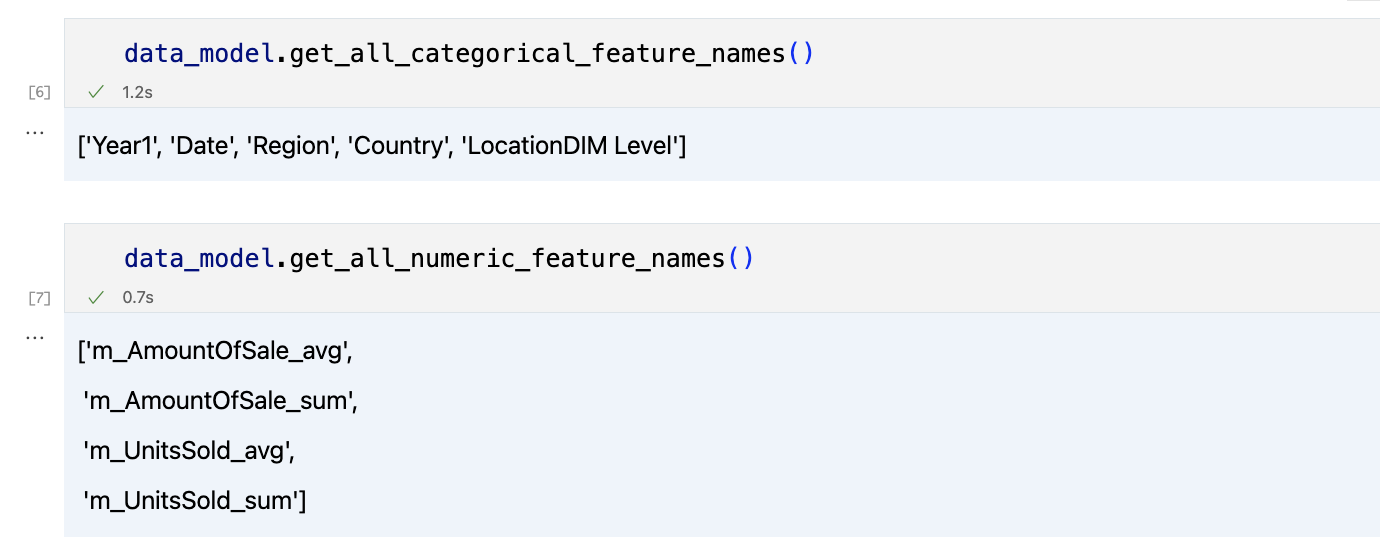
Après avoir examiné un peu la situation, nous pouvons interroger les données qui nous intéressent à l'aide de la méthode 'get_data'. Elle renverra un pandas DataFrame contenant les résultats de la requête.
df = data_model.get_data(feature_list = ['Country','Region','m_AmountOfSale_sum'])
df = df.sort_values(by='m_AmountOfSale_sum')
df.head()
Ce qui affichera votre trame de données:

Préparons un ensemble de données et affichons-le rapidement sur le graphique
import matplotlib.pyplot as plt
# Nous enregistrons des ventes pour chaque date
dataframe = data_model.get_data(feature_list = ['Date','m_AmountOfSale_sum'])
# Création d'un graphique linéaire
plt.plot(dataframe['Date'], dataframe['m_AmountOfSale_sum'])
# Ajout des étiquettes et d'un titre
plt.xlabel('Days')
plt.ylabel('Sales')
plt.title('Daily Sales Data')
# Affichage du graphique
plt.show()
Résultat:

Étape 4: Prédiction
La prochaine étape consistera à tirer profit du pont AI-Link - faisons quelques prédictions simples!
# Chargement des données historiques pour l'entraînement du modèle
data_train = data_model.get_data(
feature_list = ['Date','m_AmountOfSale_sum'],
filter_less = {'Date':'2021-01-01'}
)
data_test = data_model.get_data(
feature_list = ['Date','m_AmountOfSale_sum'],
filter_greater = {'Date':'2021-01-01'}
)
Nous disposons ici de 2 jeux de données différents: pour entraîner notre modèle et pour le tester.
# Pour l'outil que nous avons choisi pour faire la prédiction 'Prophète' ,nous devrons spécifier 2 colonnes: 'ds' et 'y'
data_train['ds'] = pd.to_datetime(data_train['Date'])
data_train.rename(columns={'m_AmountOfSale_sum': 'y'}, inplace=True)
data_test['ds'] = pd.to_datetime(data_test['Date'])
data_test.rename(columns={'m_AmountOfSale_sum': 'y'}, inplace=True)
# Initialisation et ajustement du modèle Prophet
model = Prophet()
model.fit(data_train)
Et puis nous créons une autre trame de données pour accueillir notre prédiction et l'afficher sur le graphique
# Création d'une trame de données prochaine pour la prévision
future = pd.DataFrame()
future['ds'] = pd.date_range(start='2021-01-01', end='2021-12-31', freq='D')
# Prédictions
forecast = model.predict(future)
fig = model.plot(forecast)
fig.show()
Résultat:

Étape 5: Réécriture
Une fois notre prédiction en place, nous pouvons la renvoyer à l'entrepôt de données et ajouter un agrégat à notre modèle sémantique afin de la refléter pour d'autres utilisateurs. La prédiction serait disponible via n'importe quel autre outil décisionnel pour les analystes décisionnels et les utilisateurs commerciaux. La prédiction elle-même sera placée dans notre entrepôt de données et y sera stockée.
from atscale.db.connections import Iris
db = Iris(
username,
host,
namespace,
driver,
schema,
port=1972,
password=None,
warehouse_id=None
)
data_model.writeback(dbconn=db,
table_name= 'SalesPrediction',
DataFrame = forecast)
data_model.create_aggregate_feature(dataset_name='SalesPrediction',
column_name='SalesForecasted',
name='sum_sales_forecasted',
aggregation_type='SUM')
Fin
C'est ça! Bonne chance avec vos prédictions!
Pour les développeurs axés sur le backend, le développement du frontend peut être une tâche intimidante, voire cauchemardesque. Au début de ma carrière, les frontières entre frontend et backend étaient brouillées et tout le monde était censé s'occuper des deux. Le CSS, en particulier, a été une lutte constante ; il a été ressenti comme une mission impossible.
Bien que j'apprécie le travail sur le front-end, CSS reste un défi complexe pour moi, d'autant plus que je l'ai appris par essais et erreurs. Le mème de Peter Griffin s'efforçant d'ouvrir des stores illustre parfaitement mon expérience de l'apprentissage du CSS.

Mais aujourd'hui, tout est changé. Des outils comme Streamlit ont révolutionné le jeu pour les développeurs qui, comme moi, préfèrent le confort de l'écran noir d'un terminal. Fini le temps où l'on se débattait avec des lignes de code qui ressemblaient à des messages cryptiques d'extraterrestres (je te regarde, CSS!). Comme le dit toujours le docteur Károly Zsolnai-Fehér de Two Minute Papers, "Quelle époque pour être en vie !". Avec Streamlit, vous pouvez créer une application web complète en utilisant uniquement du code Python. Voulez-vous le voir à l'œuvre? Attachez vos ceintures, car je suis sur le point de partager ma tentative de création d'un frontend pour SQLZilla en utilisant cet outil génial.
Pour l'installer, il suffit d'ouvrir votre terminal et de lancer le sort suivant:
pip install streamlit
(Ou vous pouvez l'ajouter à votre fichier requirements.txt.)
Créez un fichier, app.py et ajoutez cet extrait de code pour afficher un titre "SQLZilla":
import streamlit as st
st.title("SQLZilla")
L'événement est à vous!
Ouvrez à nouveau votre terminal et tapez la commande suivante pour activer votre création:
streamlit run app.py
Voila! Votre application Streamlit devrait apparaître dans votre navigateur web, affichant fièrement le titre "SQLZilla".
Ajoutez une image en utilisant la méthode d'image, pour la centraliser j'ai juste créé 3 colonnes et je les ajouté au centre (honte à moi)
st.title("SQLZilla")
left_co, cent_co, last_co = st.columns(3)
with cent_co:
st.image("small_logo.png", use_column_width=True)
Pour gérer les configurations et les résultats des requêtes, vous pouvez utiliser l'état de la session. Vous trouverez ci-dessous la manière d'enregistrer les valeurs de configuration et de stocker les résultats des requêtes:
if 'hostname' not in st.session_state:
st.session_state.hostname = 'sqlzilla-iris-1'
if 'user' not in st.session_state:
st.session_state.user = '_system'
if 'pwd' not in st.session_state:
st.session_state.pwd = 'SYS'
# Add other session states as needed
Pour connecter SQLZilla à une base de données IRIS InterSystems, vous pouvez utiliser SQLAlchemy. Tout d'abord, installez SQLAlchemy avec:
pip install sqlalchemy
Ensuite, configurez la connexion dans votre fichier app.py:
from sqlalchemy import create_engine
import pandas as pd
# Remplacez par vos propres données de connexion
engine = create_engine(f"iris://{user}:{password}@{host}:{port}/{namespace}")
def run_query(query):
with engine.connect() as connection:
result = pd.read_sql(query, connection)
return result
Une fois connecté à la base de données, vous pouvez utiliser Pandas et Streamlit pour afficher les résultats de vos requêtes. Voici un exemple d'affichage d'un DataFrame dans votre application Streamlit:
if 'query' in st.session_state:
query = st.session_state.query
df = run_query(query)
st.dataframe(df)
Pour rendre votre application plus interactive, vous pouvez utiliser st.rerun() pour rafraîchir l'application à chaque changement de la requête:
if 'query' in st.session_state and st.button('Run Query'):
df = run_query(st.session_state.query)
st.dataframe(df)
st.rerun()
Vous pouvez trouver des composants Streamlit variés à utiliser. Dans SQLZilla, j'ai ajouté une version de l'éditeur de code ACE appelée streamlit-code-editor:
from code_editor import code_editor
editor_dict = code_editor(st.session_state.code_text, lang="sql", height=[10, 100], shortcuts="vscode")
if len(editor_dict['text']) != 0:
st.session_state.code_text = editor_dict['text']
Comme l'assistant SQLZilla est écrit en Python, j'ai simplement appelé la classe:
from sqlzilla import SQLZilla
def assistant_interaction(sqlzilla, prompt):
response = sqlzilla.prompt(prompt)
st.session_state.chat_history.append({"role": "user", "content": prompt})
st.session_state.chat_history.append({"role": "assistant", "content": response})
if "SELECT" in response.upper():
st.session_state.query = response
return response
Bravo! Vous avez créé votre propre SQLZilla. Continuez à explorer Streamlit et améliorez votre application avec d'autres fonctionnalités. Et si vous aimez SQLZilla, votez pour cet incroyable assistant qui convertit le texte en requêtes!
Salut la Communauté !
Utilisez-vous des outils d’IA générative pour le développement ? Laissez les principes d’InterSystems vous guider ! 🌟 Découvrez la démarche de l'entreprise :
Bonjour la communauté,
Regardez cette vidéo pour apprendre à gérer par programmation les planifications de tâches à l'aide d'InterSystems IRIS, notamment la création, la modification et la suppression d'une tâche définie par l'utilisateur :
⏯ Utilisation des planifications de tâches InterSystems IRIS par programmation
Salut la communauté !
Besoin d'une introduction à l'IA générative ? Learning Services est ravi d'annoncer la première vidéo d'une nouvelle série sur les bases de GenAI :
Pour des raisons pratiques, il peut être souhaitable qu'après un redémarrage du serveur Linux, l'instance IRIS soit automatiquement démarrée.
Vous trouverez ci-dessous les étapes à suivre pour automatiser le démarrage d'IRIS lors d'un reboot du serveur Linux, via systemd :
1. Créer un fichier iris.service dans /etc/systemd/system/iris.service contenant les informations suivantes
Avant-propos
Les versions 2022.2 et ultérieures d'InterSystems IRIS offrent la possibilité de s'authentifier auprès d'une API REST à l'aide de jetons web (JWT) JSON. Cette fonctionnalité renforce la sécurité en limitant le lieu et la fréquence de transfert des mots de passe sur le réseau et en fixant un délai d'expiration pour l'accès.
L'objectif de cet article est de servir de tutoriel sur la façon d'implémenter une API REST fictive en utilisant InterSystems IRIS et de verrouiller l'accès à cette API par le biais de JWT.
REMARQUE Je ne suis PAS développeur. Je ne fais aucune déclaration quant à l'efficacité, l'évolutivité ou la qualité des échantillons de code que j'utilise dans cet article. Les exemples ci-dessous sont donnés UNIQUEMENT à des fins éducatives. Ils ne sont PAS destinés à un code de production.
Prologue
Cette réserve étant faite, explorons les concepts que nous allons décortiquer ici.
Qu'est-ce que REST?
Le terme REST est l'acronyme de REpresentational State Transfer. Il s'agit d'un style d'architecture pour la conception d'applications connectées et pour l'accès à des fonctions publiées par ces applications.
Qu'est-ce qu'un JWT?
Un jeton web JSON (JWT) est un moyen compact et sûr au niveau de l'URL qui permet de représenter les demandes transférées entre deux parties et qui peuvent être signées numériquement, cryptées ou les deux à la fois. Si vous souhaitez en savoir plus sur les JWT et les autres classes web JSON prises en charge par InterSystems IRIS, lisez cet article.
Se salir les mains
Selon les spécifications
Pour consommer une API REST, il faut d'abord disposer d'une API REST. J'ai fourni ici un exemple de spécification OpenAPI 2.0 qui est adapté au jeu de rôle sur table (TTRPG). Je l'utiliserai tout au long des exemples présentés ici. Il existe de nombreux exemples de rédaction en ligne, alors n'hésitez pas à vous y plonger, mais la spécification n'est qu'un plan directeur. Il ne fait rien d'autre que de nous informer sur l'utilisation de l'API.
Génération d'API REST
InterSystems IRIS fournit une manière très soignée de générer des souches de code pour l'API REST. Cette documentation fournit une méthode complète de génération de souches de code. N'hésitez pas à utiliser la spécification OpenAPI 2.0 que j'ai fournie dans la section précédente.
Mise en œuvre
C'est là que nous allons creuser. La section de génération aura créé trois fichiers .cls pour vous :
impl.clsdisp.clsspec.cls
Nous allons passer le plus de temps possible dans impl.cls, peut-être toucher à disp.cls pour le débogage, et laisser spec.cls tranquille.
Dans impl.cls se trouvent les souches de code pour les méthodes que disp.cls appellera lorsqu'il recevra une requête API. La spécification OpenAPI a défini ces signatures. Elle peut dire ce que vous voulez qu'elle fasse, mais c'est vous qui devez la mettre en œuvre. Alors faisons ça!
Création
L'une des façons dont nous utilisons une base de données est d'y ajouter des objets. Ces objets servent de base à nos autres fonctions. Sans objets existants, nous n'aurons rien à voir, nous allons donc commencer par notre modèle d'objet : un caractère Character !
Un Character aura nécessairement un nom et spécifiera éventuellement sa classe, sa race et son niveau. Voici un exemple d'implémentation de la classe TTRPG.Character.
Class TTRPG.Character Extends %Persistent
{
Property Name As %String [ Required ];
Property Race As %String;
Property Class As %String;
Property Level As %String;
Index IndexName On Name [ IdKey ];
ClassMethod GetCharByName(name As %String) As TTRPG.Character
{
set character = ##class(TTRPG.Character).%OpenId(name)
Quit character
}
}
Puisque nous voulons stocker les objets Character dans la base de données, il nous faut hériter de la classe %Persistent. Nous voulons être capables de rechercher nos charactères par leur nom plutôt que de leur assigner une clé d'identification arbitraire, donc nous définissons l'attribut [ IdKey ] sur l'index pour la propriété Character.Name. Cela garantit également l'unicité du nom du caractère.
Une fois notre modèle d'objet fondamental défini, nous pouvons analyser la mise en œuvre de l'API REST. La première méthode que nous allons explorer est la méthode PostCharacter.
En résumé, cette partie consomme une requête HTTP POST vers le point de terminaison /characters avec les propriétés de caractères que nous avons définies dans le corps de la requête. Il devrait prendre les arguments fournis et créer un objet TTRPG.Character à partir de ceux-ci, le sauvegarder dans la base de données, et nous faire savoir s'il a réussi ou non.
ClassMethod PostCharacter(name As %String, class As %String, race As %String, level As %String) As %DynamicObject
{
set results = {} // create the return %DynamicObject
//créer l'objet caractère
set char = ##class(TTRPG.Character).%New()
set char.Name = name
set char.Class = class
set char.Race = race
set char.Level = level
set st = char.%Save()
if st {
set charInfo = {}
set charInfo.Name = char.Name
set charInfo.Class = char.Class
set charInfo.Race = char.Race
set charInfo.Level = char.Level
set results.Character = charInfo
Set results.Status = "success"
}
else {
Set results.Status = "error"
Set results.Message = "Unable to create the character"
}
Quit results
}
Désormais, nous pouvons créer des caractères, mais comment récupérer celui que nous venons de créer ? Selon la spécification OpenAPI, le point de terminaison /characters/{charName} nous permet de récupérer un caractère par son nom. Nous récupérons l'instance de caractère, si elle existe. S'il n'existe pas, nous renvoyons une erreur indiquant à l'utilisateur qu'un caractère avec le nom fourni n'existe pas. Ceci est mis en œuvre dans la méthode GetCharacterByName.
ClassMethod GetCharacterByName(charName As %String) As %DynamicObject
{
// Créer un nouvel objet dynamique pour stocker les résultats
Définir les résultats = {}
set char = ##class(TTRPG.Character).GetCharByName(charName)
if char {
set charInfo = {}
set charInfo.Name = char.Name
set charInfo.Class = char.Class
set charInfo.Race = char.Race
set charInfo.Level = char.Level
set results.Character = charInfo
Set results.Status = "success"
}
// Si aucun caractère n'a été trouvé, un message d'erreur est affiché dans l'objet de résultats.
else {
Set results.Status = "error"
Set results.Message = "No characters found"
}
// Renvoyer l'objet de résultats
Quit results
}
Mais c'est juste votre caractère. Qu'en est-il de tous les autres caractères créés par d'autres personnes ? Nous pouvons visualiser ces caractères en utilisant la méthode GetCharacterList. Il consomme une requête HTTP GET vers le point de terminaison /characters pour compiler et renvoyer une liste de tous les caractères de la base de données.
ClassMethod GetCharacterList() As %DynamicObject
{
// Créer un nouvel objet dynamique pour stocker les résultats
Définir les résultats = {}
set query = "SELECT Name, Class, Race, ""Level"" FROM TTRPG.""Character"""
set tStatement = ##class(%SQL.Statement).%New()
set qstatus = tStatement.%Prepare(query)
if qstatus '= 1 { Do ##class(TTRPG.impl).%WriteResponse("Error: " _ $SYSTEM.Status.DisplayError(qstatus)) }
set rset = tStatement.%Execute()
Set characterList = []
while rset.%Next(){
Set characterInfo = {}
Set characterInfo.Name = rset.Name
set characterInfo.Race = rset.Race
Set characterInfo.Class = rset.Class
Set characterInfo.Level = rset.Level
Do characterList.%Push(characterInfo)
}
if (rset.%SQLCODE < 0) {write "%Next failed:", !, "SQLCODE ", rset.%SQLCODE, ": ", rset.%Message quit}
set totalCount = rset.%ROWCOUNT
// Définit les propriétés status, totalCount et characterList dans l'objet de résultats
Set results.Status = "success"
Set results.TotalCount = totalCount
Set results.CharacterList = characterList
// Renvoyer l'objet de résultats
Quit results
}
C'est notre API! La spécification actuelle ne fournit pas de moyen de mettre à jour ou de supprimer des caractères de la base de données, et cela reste un exercice pour le lecteur!
Configuration IRIS
Maintenant que notre API REST est implémentée, comment pouvons-nous la faire communiquer avec IRIS ? Dans le portail de gestion, si vous allez sur la page Administration du système > Sécurité > Applications > Applications Web, vous pouvez créer une nouvelle application Web. Le nom de l'application est le point de terminaison que vous utiliserez lors de vos requêtes. Par exemple, si vous l'avez nommée /api/TTRPG/, les requêtes pour l'API iront à http://localhost:52773/api/TTRPG/RPG/{endpoint}. Pour une installation locale de sécurité normale d'IRIS, cela ressemble à http://localhost:52773/api/TTRPG/{endpoint}. Donnez-lui une belle description, définissez l'espace de noms souhaité et cliquez sur le bouton radio pour REST. Pour activer l'authentification JWT, cochez la case "Use JWT Authentication". Le délai d'expiration du jeton d'accès JWT détermine la fréquence à laquelle un utilisateur devra recevoir un nouveau JWT. Si vous prévoyez de tester l'API pendant une période prolongée, je vous recommande de fixer cette valeur à une heure (3 600 secondes) et le délai d'expiration du jeton JWT (JWT Refresh Token Timeout) (la période pendant laquelle vous pouvez renouveler votre jeton avant qu'il n'expire définitivement) à 900 secondes.
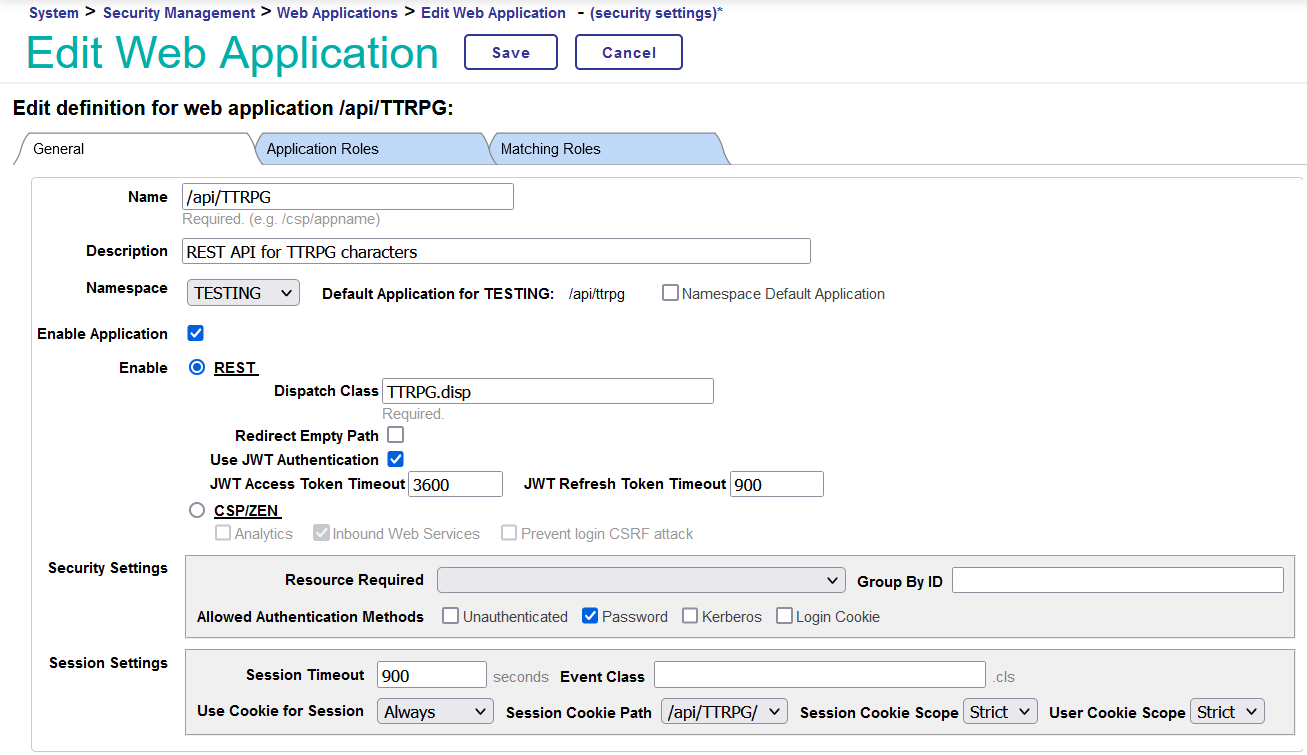
Maintenant que l'application est configurée, nous devons configurer IRIS lui-même pour permettre l'authentification JWT. Vous pouvez configurer cette option dans Administration système > Sécurité > Sécurité du système > Authentification/Options de session Web. Le champ de l'émetteur du JWT et l'algorithme de signature à utiliser pour signer et valider les JWT se trouvent en bas de la page. Le champ émetteur apparaît dans la section de demande d'indemnisation du JWT et a pour but d'indiquer qui vous a donné ce jeton. Vous pourriez le définir sur "InterSystems".

Temps de test
Tout est configuré et mis en œuvre, alors lançons-nous ! Chargez votre outil favori de création de requêtes API (j'utiliserai une extension Firefox appelée RESTer dans les exemples) et nous allons construire des requêtes API REST.
Tout d'abord, essayons de répertorier tous les caractères qui existent.
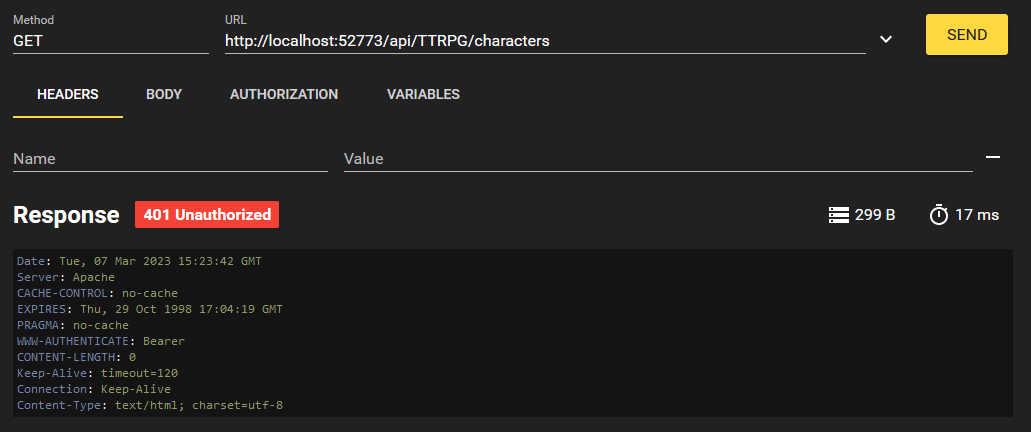
Nous avons reçu une erreur "HTTP 401 Unauthorized". C'est parce que nous ne sommes pas connectés. Vous vous dites peut-être, Elliott, nous n'avons pas implémenté de fonctionnalité de connexion à cette API REST. Ce n'est pas grave, car InterSystems IRIS s'en charge pour nous lorsque nous utilisons l'authentification JWT. Il fournit quatre points de terminaison que nous pouvons utiliser pour gérer notre session. Il s'agit de /login, /logout /revoke et /refresh. Ils peuvent être personnalisés dans le fichier disp.cls comme dans l'exemple ci-dessous :
Parameter TokenLoginEndpoint = "mylogin";
Parameter TokenLogoutEndpoint = "mylogout";
Parameter TokenRevokeEndpoint = "myrevoke";
Parameter TokenRefreshEndpoint = "myrefresh";
Accédons maintenant au point de terminaison /login.
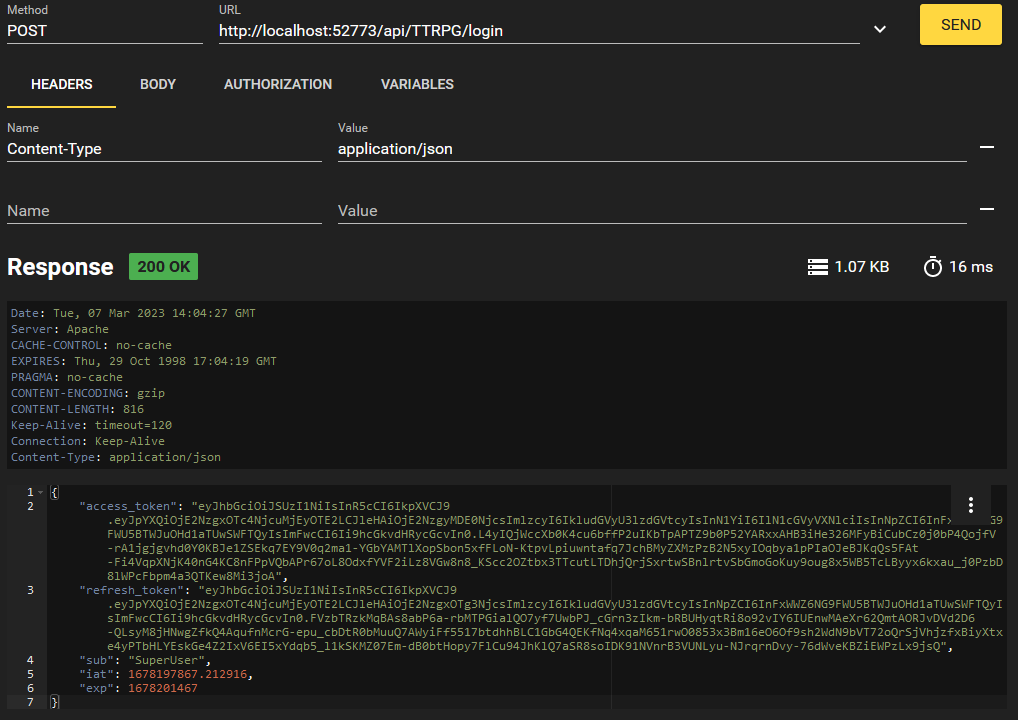
Le corps de cette demande n'est pas affiché pour des raisons de sécurité, mais il reprend la structure JSON :
{"user":"{YOURUSER}", "password":"{YOURPASSWORD}"}
En échange de notre mot de passe, nous recevons un JWT! C'est la valeur de "access_token". Nous allons copier ceci et l'utiliser dans nos demandes à l'avenir afin de ne pas avoir à transmettre notre mot de passe tout le temps.
Maintenant que nous avons un JWT pour l'authentification, essayons de créer un caractère!
Nous formatons notre demande comme ci-dessous:
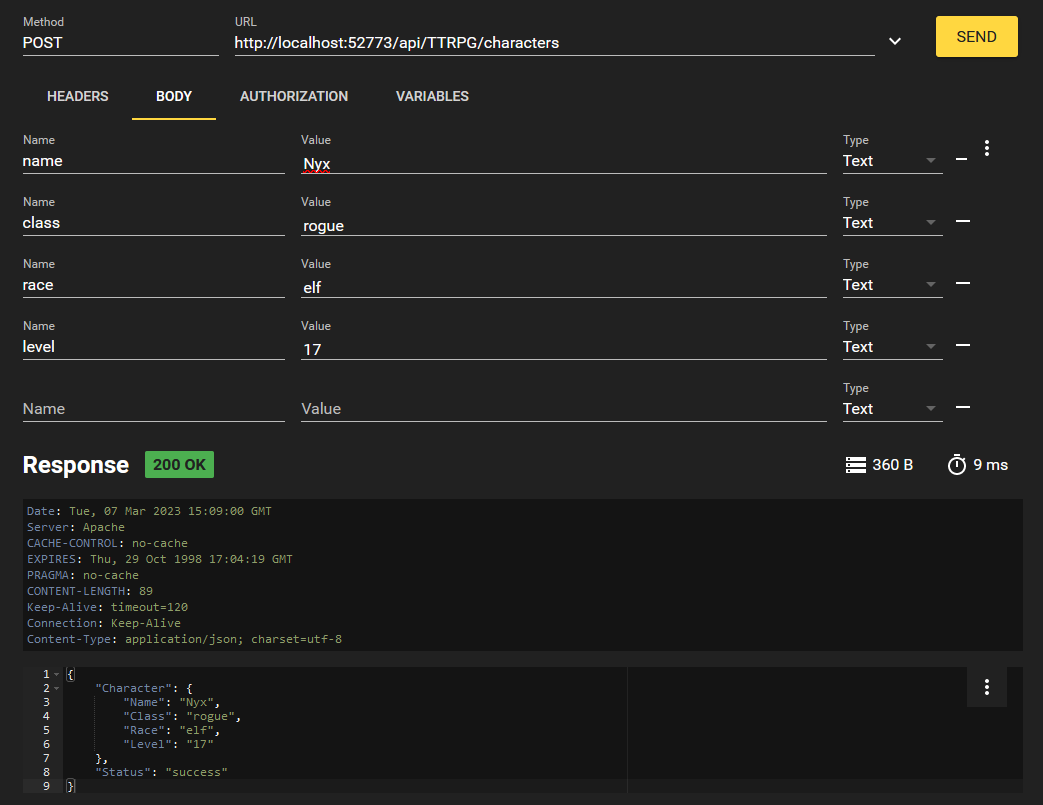
Utilisation du jeton "bearer token" en tant qu'en-tête au format "Authorization: Bearer {JWTValue}". Dans une requête curl, vous pouvez écrire ceci avec -H "Authorization: Bearer {JWTValue}"
Créons un autre caractère pour le plaisir, en utilisant les valeurs de votre choix.
Essayons maintenant de répertorier tous les caractères qui existent dans la base de données.
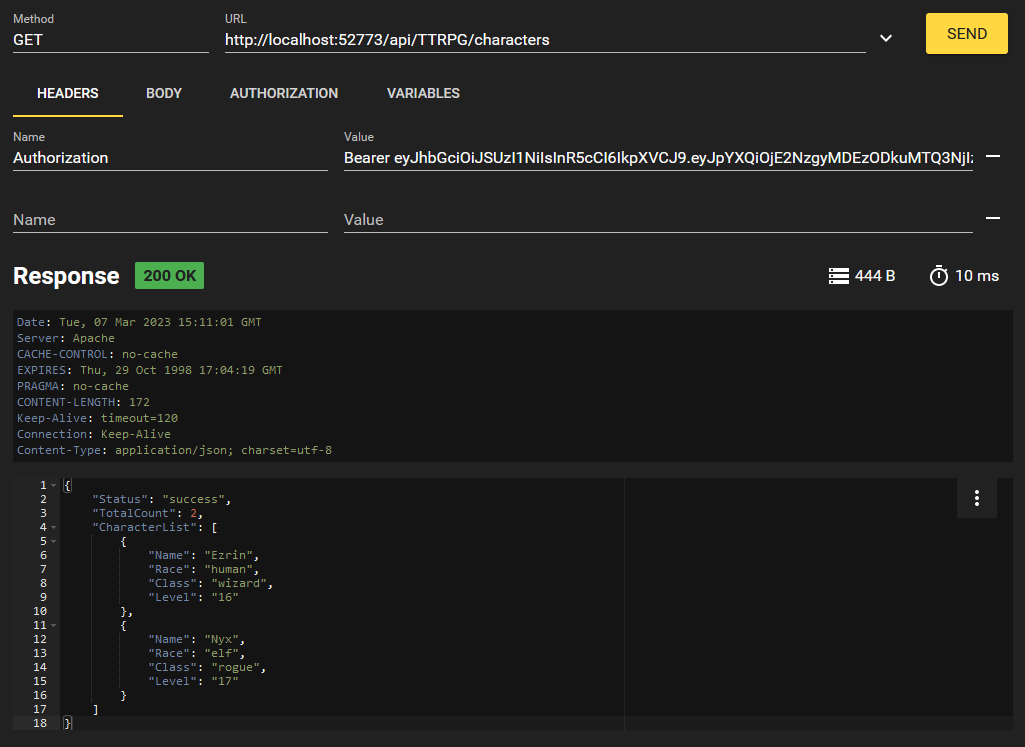
Nous récupérons nos deux caractères que nous avons créés! Mais qu'en est-il si nous voulons simplement accéder à l'un d'entre eux ? Eh bien, nous avons implémenté cela avec le point de terminaison /characters/{charName}. Nous pouvons formater cette requête comme ceci:
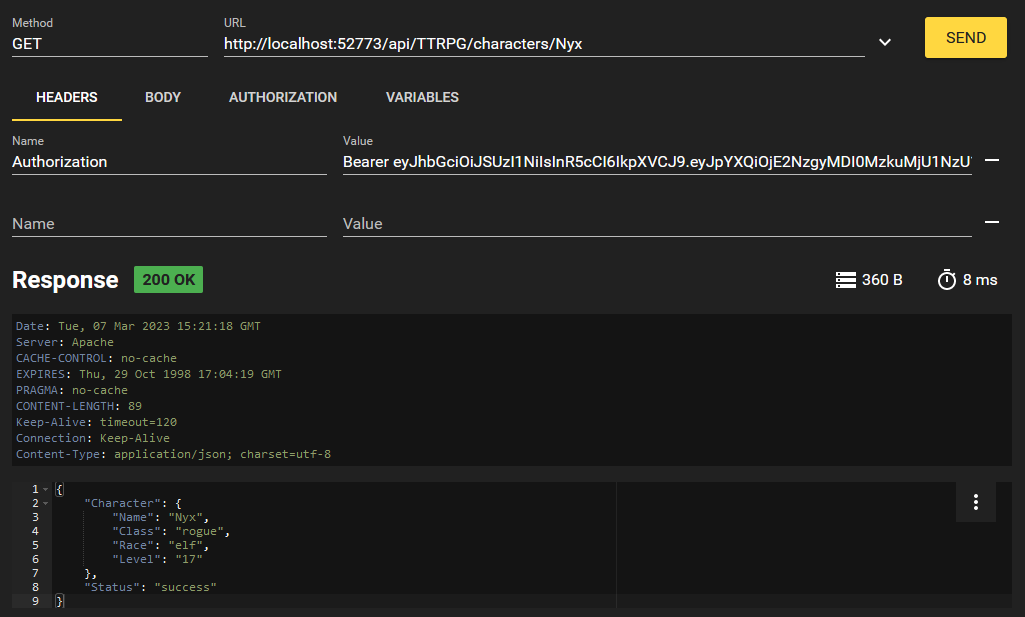
C'est notre API REST qui est à l'œuvre ! Lorsque vous avez terminé votre session, vous pouvez vous déconnecter au point de terminaison /logout en utilisant votre JWT. Ceci révoquera le JWT et le mettra sur une liste noire afin que vous ne puissiez plus l'utiliser.
Conclusion
Les versions 2022.2+ d'InterSystems IRIS offrent la possibilité de s'authentifier auprès d'une API REST à l'aide de jetons web (JWT) JSON. Cette fonctionnalité améliore la sécurité en limitant l'utilisation des mots de passe et en définissant une date d'expiration pour l'accès à l'API.
J'espère que cette présentation sur la génération d'une API REST et sa sécurisation avec des JWT via IRIS vous a été utile. Faites-moi savoir si c'était le cas! J'apprécie tout commentaire.
À partir de la sortie de la plateforme de données InterSystems IRIS® 2022.3, InterSystems a corrigé le mécanisme d'application des licences pour inclure les requêtes REST et SOAP. En raison de ce changement, les environnements dotés de licences non basées sur le cœur qui utilisent REST ou SOAP peuvent connaître une plus grande utilisation des licences après la mise à niveau. Pour déterminer si cet avis s'applique à votre licence InterSystems, suivez les instructions de la FAQ liée ci-dessous.
Ce tableau résume l'application :
Salut la communauté !
Nous sommes très heureux de vous inviter à l'événement LinkedIn Live dédié à l'apprentissage en ligne !
🌐 Deux décennies d'innovation dans l'apprentissage et le développement 🌐
📅 Jeudi 30 mai, 10 h ET | 16h00 CEST
🗣 Présentateurs:
- @John Paladino, Head of Client Services, InterSystems
- @James Breen, Director of Global Learning, InterSystems
.jpg)
Êtes-vous nouveau dans le développement avec la plateforme de données InterSystems IRIS® ?
👩💻 Apprenez à commencer à développer une application avec InterSystems ObjectScript et dans le langage de votre choix (programme, 20h).
🥇 Gagnez un badge numérique en démontrant vos compétences lors de l'évaluation finale !
Besoin d'apprendre à mettre en œuvre InterSystems IRIS ?
👨💻 Familiarisez-vous avec l'intégration et la programmation d'InterSystems IRIS (programme, 26h). Des badges numériques sont disponibles pour certains parcours d'apprentissage de ce programme.
Comme la plupart d'entre vous l'ont déjà entendu, InterSystems a annoncé l'abandon de Studio avec la sortie d'IRIS 2023.2. Un plan de dépréciation détaillé a été révélé en novembre, et nous atteignons maintenant la première étape de ce plan. À partir des kits de préversion 2024.2, les kits Windows ne contiendront plus Studio. Cela signifie que les nouvelles installations utilisant ce kit n'installeront pas Studio et que la mise à niveau d'une instance existante vers la version 2024.2 (ou ultérieure) supprimera Studio du répertoire bin de l'instance.
Configuration de Production
Cette démo comporte une production d'interopérabilité contenant 16 composants. 
Configuration de Production HL7 + Kafka Producer
La première partie de cette démonstration consiste à envoyer un fichier HL7 SIU qui sera transmis aux 2 autres flux HL7 (HTTP et TCP), et transformé et transmis au serveur Kafka. Les flux HTTP et TCP transformeront les messages HL7 de la même manière avant de les envoyer également à Kafka.
Bonjour La Communauté,
Quelle est la syntaxe correcte dans un fichier merge.cpf pour créer une base de données avec sa ressource associée ?
Bonjour la Communauté,
Cliquez sur play et plongez-vous dans notre nouvelle vidéo sur InterSystems Developers YouTube:
⏯ HealthShare Health Connect - Upgrade Automation with Production Validator @ Global Summit 2023
Salut la communauté!
Souvent, lorsque nous développons des solutions commerciales, il est nécessaire de déployer des solutions sans code source, par exemple afin de préserver la propriété intellectuelle.
L'une des manières d'y parvenir est d'utiliser InterSystems Package Manager.
Ici, j'ai demandé à Midjourney de peindre la propriété intellectuelle d'un logiciel :

Illustration numérique de l'espace de travail d'un développeur de logiciels axé sur la protection de la propriété intellectuelle.
La scène montre un développeur de logiciels à son bureau, avec un écran d'ordinateur affichant un code complexe recouvert de verrous et de boucliers lumineux.
Sur le bureau se trouve un document de brevet avec un sceau et un ruban, symbolisant la protection d'innovations logicielles uniques.
A proximité, se trouvent des boîtes de produits logiciels avec des symboles de marque (™ ou ®) et des papiers avec des symboles de droit d'auteur (©), représentant la protection de l'identité de la marque et des œuvres originales.
Le cadre est moderne et bien éclairé, générant un sentiment de sécurité et d'innovation.Comment y parvenir avec IPM ?
En fait, c'est très simple ; ajoutez simplement la clause Deploy="true" dans l'élément Resource de votre manifeste module.xml. Documentation.
J'ai décidé de fournir l'exemple le plus simple possible pour illustrer son fonctionnement et également de vous donner un modèle d'environnement de développement pour vous permettre de commencer à créer et à déployer vos propres modules sans code source. On y va !
Chez InterSystems, nous nous efforçons de vous offrir la meilleure qualité en tout. Y compris la réalisation de notre programme Global Masters.
Le fournisseur de cette plateforme a été racheté par une autre société et malheureusement, nous ne pourrons plus continuer à héberger notre estimé programme Global Masters sur cette plateforme. Nous évaluons actuellement de nouveaux fournisseurs de plateformes pour faciliter la transition du Global Masters Advocate Hub.
À partir du 26 avril, nous suspendrons temporairement l'accès au programme Global Masters lors de la transition vers une nouvelle plateforme.

FAQ:
Cette fois, je ne veux pas parler d’une fonctionnalité géniale d’IRIS (qui en possède de nombreuses), mais plutôt d’une fonctionnalité qui manque cruellement.Aujourd’hui, parler de POO n’est pas sexy. Bien que presque tous les langages de programmation modernes implémentent une sorte de POO, les discussions sur les problèmes fondamentaux du développement logiciel ne sont pas très courantes entre les développeurs de technologies telles que les développeurs. En fait, l’informatique dans son ensemble n’est pas un sujet courant parmi les développeurs, ce qui devrait l’être à mon avis.Dans cette
Comme vous avez pu le constater dans les dernières publications de la communauté, InterSystems IRIS inclut depuis la version 2024.1 la possibilité d'inclure des types de données vectorielles dans sa base de données et sur la base de ce type de données, des recherches vectorielles ont été mises en œuvre. Eh bien, ces nouvelles fonctionnalités m'ont rappelé l'article que j'ai publié il y a quelque temps et qui était basé sur la reconnaissance faciale utilisant Embedded Python.
Introduction
Bonjour la communauté,
Nous sommes heureux d'inviter tous les développeurs au prochain webinaire de lancement du concours Vector Search, GenAI et ML !
Découvrez les défis et opportunités qui attendent les passionnés de GenAI et de ML dans ce concours. Nous discuterons des sujets que nous attendons des participants et vous montrerons comment développer, créer et déployer des applications à l'aide de la plate-forme de données InterSystems IRIS. Il y aura également une démonstration de InterSystems IRIS Vector Search que vous pouvez utiliser dans vos projets.
Date et heure : lundi 22 avril – 12 h EDT | 18h00 CEST
.jpg)
Bonjour les développeurs,
Regardez la dernière vidéo sur InterSystems Developers YouTube:
Dans cet article, nous aborderons les sujets ci-dessous :
- Qu’est-ce que Kubernetes ?
- Principaux composants Kubernetes (K8s)
Qu’est-ce que Kubernetes?
Kubernetes est un framework d'orchestration de conteneurs open source développé par Google. Essentiellement, il contrôle la vitesse des conteneurs et vous aide à gérer des applications composées de plusieurs conteneurs. De plus, il vous permet de les exploiter dans différents environnements, par exemple des machines physiques, des machines virtuelles, des environnements Cloud ou même des environnements de déploiement hybrides.
Si vous exécutez IRIS dans une configuration miroir pour HA dans Azure, la question de la fourniture de Mirror VIP (adresse IP virtuelle) devient pertinente. L'adresse IP virtuel permet aux systèmes en aval d'interagir avec IRIS en utilisant une seule adresse IP. Même en cas de basculement, les systèmes en aval peuvent se reconnecter à la même adresse IP et continuer à fonctionner.
Le principal problème, lors du déploiement sur Azure, est qu'un VIP IRIS doit être essentiellement un administrateur de réseau, conformément aux docs.
Pour obtenir l'HA, les membres du miroir IRIS doivent être déployés dans différentes zones de disponibilité d'un sous-réseau (ce qui est possible dans Azure car les sous-réseaux peuvent s'étendre sur plusieurs zones). L'une des solutions pourrait être les équilibreurs de charge, mais ils coûtent bien sûr plus cher et nécessitent d'être administrés.
Dans cet article, j'aimerais fournir un moyen de configurer un VIP miroir sans utiliser les équilibreurs de charge suggérés dans la plupart des autres architectures de référence Azure.
Architecture
Nous avons un sous-réseau qui s'étend sur deux zones de disponibilité (je simplifie ici - bien sûr, vous aurez probablement des sous-réseaux publics, un arbitre dans une autre zone, et ainsi de suite, mais il s'agit d'un minimum absolu suffisant pour démontrer cette approche). La notation CIDR du sous-réseau est 10.0.0.0/24, ce qui signifie que les adresses IP 10.0.0.1 à 10.0.0.255 lui sont allouées. Puisque Azure réserve les quatre premières adresses et la dernière adresse, nous pouvons utiliser 10.0.0.4 à 10.0.0.254.
Nous mettrons en œuvre des VIP publics et privés en même temps. Si vous voulez, vous pouvez implémenter uniquement le VIP privé.
Idée
Les machines virtuelles dans Azure ont des Interfaces réseau. Ces interfaces réseau ont des Configurations IP. La configuration IP est une combinaison d'IP publiques et/ou privées, et elle est acheminée automatiquement vers la Machine virtuelle associée à l'Interface réseau. Il n'est donc pas nécessaire de mettre à jour les routes. Lors d'un basculement de miroir, nous allons supprimer la configuration IP VIP de l'ancien primaire et la créer pour un nouveau primaire. Toutes les opérations nécessaires à cette fin prennent de 5 à 20 secondes pour une IP VIP privée uniquement, de 5 secondes à une minute pour une combinaison d'IP VIP publique/privée.
Mise en œuvre de VIP
- Allocation de l'IP externe à utiliser en tant que VIP public. Ignorez cette étape si vous souhaitez uniquement un VIP privé. Si vous attribuez le VIP, il doit résider dans le même groupe de ressources et dans la même région et se trouver dans toutes les zones avec le primaire et le backup. Vous aurez besoin d'un nom IP externe.
- Choisissez une valeur VIP privée. J'utiliserai la dernière adresse IP disponible
'10.0.0.254' - Sur chaque machine virtuelle, attribuez l'adresse IP VIP privée sur l'interface réseau
eth0:1.
cat << EOFVIP >> /etc/sysconfig/network-scripts/ifcfg-eth0:1
DEVICE=eth0:1
ONPARENT=on
IPADDR=10.0.0.254
PREFIX=32
EOFVIP
sudo chmod -x /etc/sysconfig/network-scripts/ifcfg-eth0:1
sudo ifconfig eth0:1 up
Si vous voulez juste faire un test, exécutez-le (mais il ne survivra pas au redémarrage du système) :
sudo ifconfig eth0:1 10.0.0.254
Selon le système d'exploitation que vous devrez peut-être exécuter:
ifconfig eth0:1
systemctl restart network
- Pour chaque machine virtuelle, activez Identité attribuée au système ou à l'utilisateur.
- Pour chaque identité, attribuez les autorisations de modifier les interfaces réseau. Pour ce faire, créez un rôle personnalisé. Dans ce cas, les autorisations minimales sont les suivantes :
{
"roleName": "custom_nic_write",
"description": "IRIS Role to assign VIP",
"assignableScopes": [
"/subscriptions/{subscriptionid}/resourceGroups/{resourcegroupid}/providers/Microsoft.Network/networkInterfaces/{nicid_primary}",
"/subscriptions/{subscriptionid}/resourceGroups/{resourcegroupid}/providers/Microsoft.Network/networkInterfaces/{nicid_backup}"
],
"permissions": [
{
"actions": [
"Microsoft.Network/networkInterfaces/write",
"Microsoft.Network/networkInterfaces/read"
],
"notActions": [],
"dataActions": [],
"notDataActions": []
}
]
}
Pour les environnements non productifs, vous pouvez utiliser un rôle système Contributeur réseau sur le groupe de ressources, mais ce n'est pas une approche recommandée car Contributeur réseau est un rôle très large.
- Chaque interface réseau dans Azure peut avoir un ensemble de configurations IP. Lorsqu'un membre miroir actuel devient primaire, nous utilisons un callback ZMIRROR pour supprimer une configuration IP VIP sur l'interface réseau d'un autre membre miroir et créer une configuration IP VIP pointant sur lui-même :
Voici les commandes Azure CLI pour les deux nœuds en supposant le groupe de ressources rg, la configuration IP vip et l'IP externe my_vip_ip :
az login --identity
az network nic ip-config delete --resource-group rg --name vip --nic-name mirrorb280_z2
az network nic ip-config create --resource-group rg --name vip --nic-name mirrora290_z1 --private-ip-address 10.0.0.254 --public-ip-address my_vip_ip
et
az login --identity
az network nic ip-config delete --resource-group rg --name vip --nic-name mirrora290_z1
az network nic ip-config create --resource-group rg --name vip --nic-name mirrorb280_z2 --private-ip-address 10.0.0.254 --public-ip-address my_vip_ip
Et le même code qu'une routine ZMIRROR :
ROUTINE ZMIRROR
NotifyBecomePrimary() PUBLIC {
#include %occMessages
set rg = "rg"
set config = "vip"
set privateVIP = "10.0.0.254"
set publicVIP = "my_vip_ip"
set nic = "mirrora290_z1"
set otherNIC = "mirrorb280_z2"
if ##class(SYS.Mirror).DefaultSystemName() [ "MIRRORB" {
// we are on mirrorb node, swap
set $lb(nic, otherNIC)=$lb(otherNIC, nic)
}
set rc1 = $zf(-100, "/SHELL", "export", "AZURE_CONFIG_DIR=/tmp", "&&", "az", "login", "--identity")
set rc2 = $zf(-100, "/SHELL", "export", "AZURE_CONFIG_DIR=/tmp", "&&", "az", "network", "nic", "ip-config", "delete", "--resource-group", rg, "--name", config, "--nic-name", otherNIC)
set rc3 = $zf(-100, "/SHELL", "export", "AZURE_CONFIG_DIR=/tmp", "&&", "az", "network", "nic", "ip-config", "create", "--resource-group", rg, "--name", config, "--nic-name", nic, "--private-ip-address", privateVIP, "--public-ip-address", publicVIP)
quit 1
}
La routine est la même pour les deux membres du miroir, nous échangeons simplement les noms des cartes réseau en fonction du nom du membre du miroir actuel. Vous pourriez ne pas avoir besoin du paramètre export AZURE_CONFIG_DIR=/tmp, mais parfois az cherche à écrire les informations d'identification dans le répertoire personnel de la racine, ce qui peut échouer. Au lieu de /tmp, il est préférable d'utiliser le sous-répertoire personnel de l'utilisateur d'IRIS (ou vous pouvez même ne pas avoir besoin de cette variable d'environnement, en fonction de votre configuration).
Et si vous voulez utiliser Embedded Python, voici le code Azure Python SDK:
from azure.identity import DefaultAzureCredential
from azure.mgmt.network import NetworkManagementClient
from azure.mgmt.network.models import NetworkInterface, NetworkInterfaceIPConfiguration, PublicIPAddress
sub_id = "AZURE_SUBSCRIPTION_ID"
client = NetworkManagementClient(credential=DefaultAzureCredential(), subscription_id=sub_id)
resource_group_name = "rg"
nic_name = "mirrora290_z1"
other_nic_name = "mirrorb280_z2"
public_ip_address_name = "my_vip_ip"
private_ip_address = "10.0.0.254"
vip_configuration_name = "vip"
# remove old VIP configuration
nic: NetworkInterface = client.network_interfaces.get(resource_group_name, other_nic_name)
ip_configurations_old_length = len(nic.ip_configurations)
nic.ip_configurations[:] = [ip_configuration for ip_configuration in nic.ip_configurations if
ip_configuration.name != vip_configuration_name]
if ip_configurations_old_length != len(nic.ip_configurations):
poller = client.network_interfaces.begin_create_or_update(
resource_group_name,
other_nic_name,
nic
)
nic_info = poller.result()
# add new VIP configuration
nic: NetworkInterface = client.network_interfaces.get(resource_group_name, nic_name)
ip: PublicIPAddress = client.public_ip_addresses.get(resource_group_name, public_ip_address_name)
vip = NetworkInterfaceIPConfiguration(name=vip_configuration_name,
private_ip_address=private_ip_address,
private_ip_allocation_method="Static",
public_ip_address=ip,
subnet=nic.ip_configurations[0].subnet)
nic.ip_configurations.append(vip)
poller = client.network_interfaces.begin_create_or_update(
resource_group_name,
nic_name,
nic
)
nic_info = poller.result()
Lancement initial
NotifyBecomePrimary est aussi appelé automatiquement au démarrage du système (après la reconnexion de miroirs), mais si vous voulez que vos environnements non-miroirs acquièrent VIP de la même manière, utilisez la routine ZSTART:
SYSTEM() PUBLIC {
if '$SYSTEM.Mirror.IsMember() {
do NotifyBecomePrimary^ZMIRROR()
}
quit 1
}
Conclusion
Et c'est tout! Nous changeons la configuration IP qui pointe vers un miroir primaire actuel lorsque l'événement NotifyBecomePrimary se produit.

L'invention et la vulgarisation des grands modèles de langage (tels que GPT-4 d'OpenAI) ont lancé une vague de solutions innovantes capables d'exploiter de grands volumes de données non structurées qui étaient peu pratiques, voire impossibles, à traiter manuellement jusqu'à récemment. Ces applications peuvent inclure la récupération de données (voir le cours ML301 de Don Woodlock pour une excellente introduction à Retrieval Augmented Generation), l'analyse des sentiments, et même des agents d'IA entièrement autonomes, pour n'en nommer que quelques-uns !
Nous avons récemment mis en ligne sur OpenExchange une petite application que j'ai développée il y a quelque temps (et que @Jose-Tomas.Salvador a améliorée et peaufinée) que j'utilise souvent lorsque j'ai besoin de générer de gros volumes de messagerie HL7.
InterSystems rubrique FAQ
Vous pouvez utiliser la classe %IndexBuilder pour effectuer la reconstruction d'index dans plusieurs processus parallèles.
Voici un exemple dans le but de définir l'index standard HomeStateIdx pour la colonne Home_State (informations de l'État de l'adresse du domicile) de Sample.Person.
Les étapes sont les suivantes:
1. Masquez le nom de l'index à ajouter/reconstruire à partir de l'optimiseur de requêtes.
>write$system.SQL.SetMapSelectability("Sample.Person","HomeStateIdx",0)
1Définition de la variable d'environnement TZ sur Linux
La liste de contrôle de la mise à jour (Update Checklist) pour v2015.1 recommande de définir la variable d'environnement TZ sur les plates-formes Linux et renvoie à la page de manuel de tzset. Cette recommandation vise à améliorer les performances des fonctions de Cache liées à l'heure. Vous pouvez en savoir plus à ce sujet ici:
https://community.intersystems.com/post/linux-tz-environment-variable-not-being-set-and-impact-caché
La page de manuel de mon système de test CentOS 7 ( la même chose pour RHEL 6) indique ce qui suit:
“La fonction tzset() initialise la variable tzname à partir de la variable d'environnement TZ. Cette fonction est automatiquement appelée par les autres fonctions de conversion de l'heure qui dépendent du fuseau horaire.”
Alors, comment définissez-vous TZ? Comment affecte-t-elle les horaires sur un serveur Linux? Voici ce que nous pouvons apprendre:
Le fuseau horaire du système --
Pour mon test, j'utilise Ensemble 2016.1 sur un système virtuel CentOS. Tout d'abord, vérifions le fuseau horaire du système. Pour cela, il faut utiliser l'utilitaire system-config-date.

Qu'en est-il de "L'horloge du système utilise l'UTC" ? Il s'agit de l'horloge matérielle du serveur. Sur un serveur dédié, l'UTC est très répandu. Lorsque Linux est utilisé dans une configuration à double démarrage avec Windows, ce n'est pas le cas (Windows utilise l'heure locale pour son horloge système).
Comme les configurations à double démarrage ne sont pas courantes pour les installations de Cache' et d'Ensemble, la question n'est pas abordée plus en détail. Les idées clés ici consistent à régler le fuseau horaire du système sur celui du serveur et à régler correctement l'heure de l'horloge matérielle.
L'heure et la date vues par les utilisateurs –
Jetons un coup d'œil. Voici un extrait de ma session de Terminal:

Tout semble en ordre. Mon processus shell (qui exécute la commande date) et mon processus Cache' affichent la même heure à l'exception des quelques secondes nécessaires à la saisie de la commande WRITE.
Définition de la variable TZ --
Maintenant, définissons TZ dans l'environnement. La commande à utiliser est tzselect. Voici un script de la sortie de la commande pour définir TZ
[ehemdal@localhost ~]$ tzselectVeuillez indiquer un lieu afin que les règles relatives au fuseau horaire puissent être définies correctement.
Veuillez sélectionner un continent ou un océan.
Afrique
Amériques
Antarctique
Océan Arctique
Asie
Océan Atlantique
Australie
Europe
Océan Indien
Océan Pacifique
aucun - Je veux spécifier le fuseau horaire en utilisant le format Posix TZ.
#? 2
Veuillez sélectionner un pays.
Anguilla 19) République dominicaine 37) Pérou
Antigua -et-Barbuda & 20) Équateur 38) Porto Rico
Argentine 21) Salvador 39) Saint-Barthélemy
Aruba 22) Guyane française 40) Saint-Christophe-et-Niévès;
Bahamas 23) Groenland 41) Sainte-Lucie
Barbade 24) Grenade 42) Saint-Martin (Néerlandais)
Bélize 25) Guadeloupe 43) Saint-Martin (Français)
Bolivie 26) Guatemala 44) Saint-Pierre-et-Miquelon;
Brésil 27) Guyane 45) Saint Vincent
Canada 28) Haïti 46) Suriname
Caraïbes NL 29) Honduras 47) Trinité-et-Tobago;
Îles Caïmans 30) Jamaïque 48) Îles Turques et Caïques Est
Chili 31) Martinique 49) États-Unis
Colombie 32) Mexique 50) Uruguay
Costa Rica 33) Montserrat 51) Vénézuéla
Cuba 34) Nicaragua 52) Îles Vierges britanniques
Curaçao 35) Panama 53) Îles Vierges (États-Unis)
Dominique 36) Paraguay
#? 49
Veuillez sélectionner l'une des régions de fuseau horaire suivantes.
Est (la plupart des régions) 16) Centre-ND (Morton rural)
Est-MI (la plupart des régions) 17) Centre-ND (Mercer)
Eastern - KY (région de Louisville) 18) Montana (la plupart des régions)
Est - KY (Wayne) 19) Montana - ID (sud); OR (est)
Est - IN (la plupart des régions) 20) MST - Arizona (sauf Navajo)
Est - IN (Da, Du, K, Mn) 21) Pacifique
Est - IN (Pulaski) 22) Alaska (la plupart des régions)
Est - IN (Crawford) 23) Alaska - région de Juneau
Est - IN (Pike) 24) Alaska - région de Sitka
Est - IN (Switzerland) 25) Alaska - Île d'Annette
Centre (la plupart des régions) 26) Alaska - Yakutat
Centre - IN (Perry) 27) Alaska (ouest)
Centre - IN (Starke) 28) Îles Aléoutiennes
Centre - MI (frontière du Wisconsin) 29) Hawaï
Centre - ND (Oliver)
#? 1
Les informations suivantes ont été données:
États-Unis Est (la plupart des régions)Par conséquent, TZ='America/New_York' sera utilisé.
L'heure locale est maintenant: Mar 31 mai 11:21:04 EDT 2016.
Le temps universel est maintenant: Mar 31 mai 15:21: 04 UTC 2016.
Les informations ci-dessus sont-elles correctes?
Oui
Non
#? 1
Vous pouvez rendre cette modification permanente par vous-même en ajoutant la ligne
TZ='America/New_York'; export TZdans le fichier '.profile' dans votre répertoire personnel, puis déconnectez-vous et reconnectez-vous.
Voici à nouveau la valeur de TZ, cette fois sur la sortie standard, afin que vous
puissiez utiliser la commande /usr/bin/tzselect dans des scripts shell:
America/New_York
[ehemdal@localhost ~]$
Le fichier ~/.profile (s'il existe) est exécuté lorsque vous vous connectez et définit la variable TZ pour vous. Vous pouvez utiliser un fichier d'initialisation différent si vous utilisez un shell autre que /bin/sh ou /bin/bash. J'ai défini cette variable et je me suis reconnecté. Si vous mettez à jour un fichier comme /etc/profile, vous pouvez appliquer cela à tous les utilisateurs.

Ici, vous pouvez voir que la TZ est définie pour mon utilisateur (ehemdal), mais PAS pour l'utilisateur root.
TZ et l'heure et la date vues par les utilisateurs –
Que se passe-t-il si un utilisateur se connecte à votre serveur depuis un autre fuseau horaire ? La variable TZ permet de conserver l'heure locale de l'utilisateur tout en laissant la gestion des fuseaux horaires et de l'heure d'été au système d'exploitation. Cela affecte également l'heure utilisée par Cache'. Par exemple, j'ai décidé de changer mon fuseau horaire pour celui d'Honolulu.
Voici deux captures d'écran qui montrent le résultat.

Le processus de mon utilisateur a défini le fuseau horaire sur Pacifique/Honolulu. Le processus root n'a pas défini de TZ (il utilise donc le fuseau horaire du système America/New_York). Au niveau du système d'exploitation (avec la commande date), l'affichage reflète l'heure locale pour les deux utilisateurs. La commande date reflète l'heure locale de l'utilisateur (HST pour l'utilisateur ehemdal et EDT pour root). Comme $HOROLOG obtient sa valeur à partir de l'heure du système d'exploitation disponible pour le processus utilisateur, les valeurs de $H sont DIFFÉRENTES pour les deux utilisateurs.
J'ai choisi l'heure d'Honolulu comme exemple intéressant car Hawaï n'observe pas l'heure d'été. En paramétrant correctement TZ pour tous les utilisateurs, l'heure locale peut "avancer et reculer" pour les utilisateurs qui observent l'heure d'été, et rester stable pour ceux qui n'observent pas l'heure d'hiver.
Quels sont les avantages/inconvénients à utiliser la ressource Person avec un lien vers les ressources Patient et Practitioner, plutôt qu'utiliser directement les ressources Patient et Practitioner sans avoir recours aux ressources Person ?
Salut les développeurs,
Obtenez une présentation d'InterSystems IRIS dans les différents rôles dans OAuth 2.0 et les menus de configuration de ces rôles. Regardez des démonstrations pratiques d'InterSystems IRIS dans ces rôles et voyez comment ils se connectent aux concepts OAuth 2.0 :
⏯ OAuth 2.0 en pratique avec les produits InterSystems au Global Summit 2023