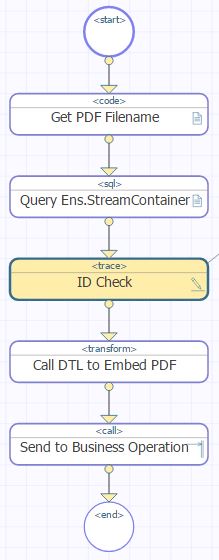
Notre objectif
Aujourd'hui, nous poursuivons le développement de notre dernier article et présentons des informations sur certaines fonctionnalités que nous avons ajoutées à notre portail. Nous inclurons une petite partie de CSS pour mieux visualiser les données disponibles et les exporter. Enfin, nous examinerons comment ajouter des options de filtrage et de classement. Lorsque vous aurez terminé cet article, vous pourrez afficher une requête simple et complète de manière élégante.
Précédemment, dans "Un portail pour gérer la mémoire réalisé avec Django"...
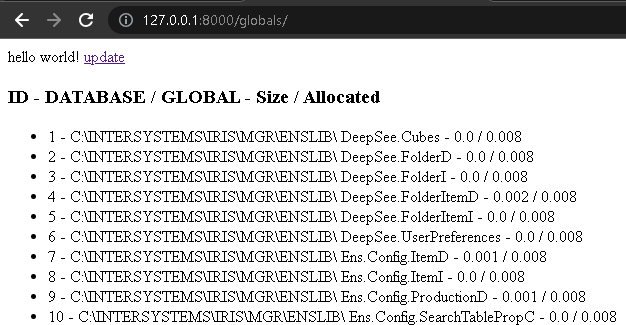
Il nous faut reprendre là où nous nous sommes arrêtés avant de passer au développement du portail. Nous avons précédemment créé la base du projet sur la ligne de commande avec certaines commandes intégrées de Django telles que startproject. Ensuite, nous avons ajouté les exigences de connexion à la base de données au fichier requirements.txt et ses paramètres au fichier settings.py pour simplifier l'installation. Plus tard, nous avons créé une application de globales "Globals" avec les URL et les chemins appropriés, dirigeant les utilisateurs du projet principal vers les vues qui communiquent avec les données au moyen de modèles. Nous avons également créé un dossier API avec quelques méthodes qui permettent d'obtenir des informations à partir d'une base de données distante. Avec tout ce qui précède, nous avons laissé à la disposition des utilisateurs une option permettant de créer une communication entre différentes instances d'IRIS. Enfin, nous avons créé le fichier index.html pour l'afficher sur le lien index.html to display it on the link http://127.0.0.1:8000/globals/.
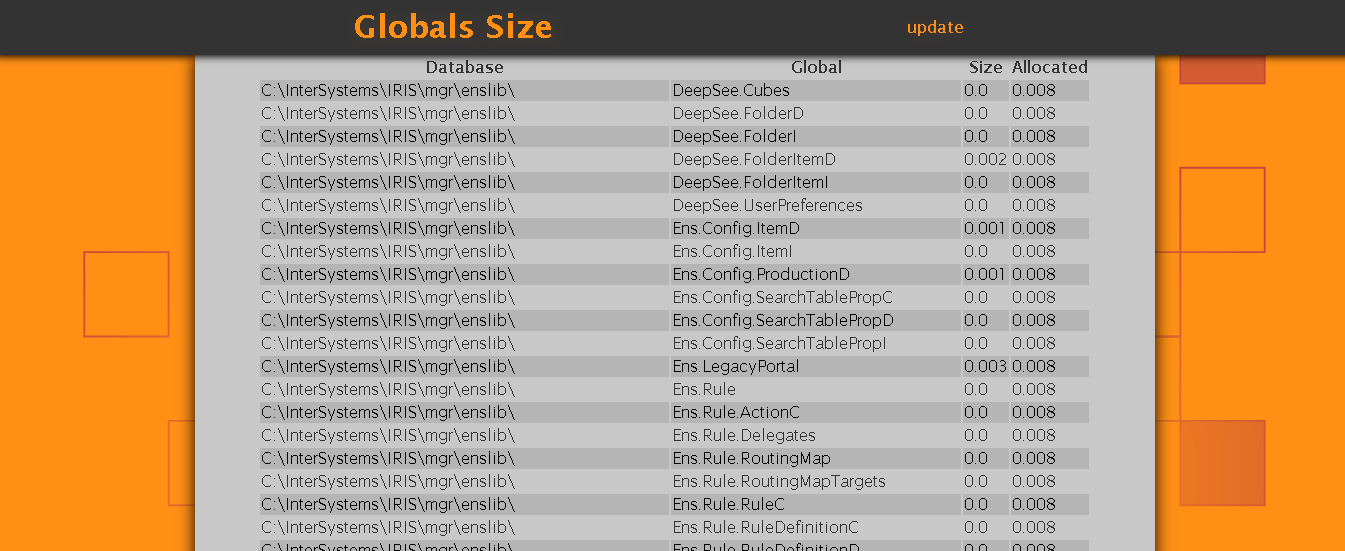
À ce stade, l'interface devraient ressembler à l'image ci-dessous.
.png)
.png)
Cependant, moins précise que l'illustration précédente, l'interface ressemble à la capture d'écran suivante.
.png)
Ajout de CSS
Les feuilles de style en cascade (CSS) permettent de transformer ce projet en quelque chose de plus présentable, de plus beau et de plus agréable à travailler. Dans cette section, vous apprendrez à utiliser les feuilles de style en cascade dans votre projet. Nous vous présenterons également quelques concepts de base de ce langage. Cependant, notre objectif principal sera de relier le fichier de styles et le projet.
Tout d'abord, il faut créer un dossier appelé "static" dans le répertoire /globals. Il sera nécessaire pour y stocker tous nos fichiers statiques par la suite. Vous pouvez ajouter le fichier styles.css à ce dossier.
.png)
À présent, nous pouvons enfin mettre de l'ordre et de la couleur. Cependant, si vous ne connaissez rien au CSS, ne vous inquiétez pas ! Voici quelques bonnes nouvelles pour vous ! Pour commencer, c'est relativement intuitif. Il suffit d'écrire l'élément et d'ajouter le design entre les crochets. Vous pouvez accéder aux classes après un point, et aux ID après un hashtag. Si vous voulez un conseil de pro, vous pouvez utiliser un astérisque pour ajouter le style à chaque élément du fichier HTML.
Par exemple, si nous ajoutons un identifiant et une classe aux trois derniers paragraphes du fichier index.html, nous pourrons y accéder séparément et y ajouter des couleurs, des arrière-plans et des polices différents.
<p>showing results for {{globals.count}} globals</p><pclass="totalSize">total size: {{sumSize.size__sum}}</p><pid="allocatedSize">total allocated size: {{sumAllocated.allocatedsize__sum}}</p>
* {
font-family: 'Lucida Sans';
}
p {
background-color: yellow;
}
.totalSize {
color: brown;
}
#allocatedSize {
font-weight: bold;
}
Selon cet actif, après avoir configuré les connexions appropriées, chaque police affichée sur la page devrait faire partie de la famille Lucida Sans, les trois paragraphes devraient avoir un arrière-plan jaune, le paragraphe avec la classe _totalSize_ devrait être en caractères bruns, et le paragraphe avec l'ID _allocatedSize_ devrait être en caractères gras.
.png)
Vous devriez remarquer quelques particularités si vous jouez avec les éléments, en y ajoutant des ID, des classes et des styles. Premièrement, il y a une hiérarchie : les définitions des identifiants remplacent les classes qui, à leur tour, remplacent les styles généraux. Deuxièmement, plusieurs éléments peuvent partager une même classe. De plus, les éléments enfants hériteront généralement du style de leurs parents (certaines choses ne seront cependant pas héritées, mais il s'agit d'un sujet plus avancé que nous n'aborderons pas ici). Si vous le souhaitez, vous pouvez nous faire part, dans la section des commentaires, des comportements que vous avez remarqués et dont vous n'aviez pas connaissance auparavant.
Ensuite, nous devons faire en sorte que le projet puisse comprendre ce qu'est un fichier de style et où le trouver. Ensuite, nous pouvons obtenir le fichier HTML faisant référence au fichier _styles.css_.
Tout d'abord, accédez à _settings.py_, recherchez la variable STATIC_URL, et modifiez sa valeur de la manière suivante.
STATIC_URL = '/static/'
Cette configuration doit indiquer au projet que tous les fichiers statiques se trouvent dans un dossier appelé "static" à l'intérieur du dossier de l'application. Dans ce cas, il s'agit du répertoire _/globals/static_. Si nous avions une autre application utilisée par ce projet, elle ne reconnaîtrait que son dossier "static" interne (à moins qu'il ne soit spécifié qu'il s'agit d'un dossier général).
Les fichiers statiques sont ceux qui ne changent pas lorsque l'application est en cours d'exécution. Vous pouvez les utiliser pour stocker des fonctions, des définitions, des constantes et des images qui facilitent l'exécution du code (dans ce cas, des fichiers .py). En pratique, c'est dans ces fichiers que vous stockez le JavaScript et le CSS.
L'étape suivante consiste à y faire référence à partir du fichier index.html. Ajoutez une balise
avant le corps. À l'intérieur du corps, utilisez une balise
pour faire référence à une feuille de style de type
text/CSS, avec la référence "{% static 'styles.css' %}" et le média "screen". De plus, vous devez indiquer à Django de télécharger les éléments statiques. Rappelez-vous que nous pouvons "dire à Django" quelque chose via le fichier HTML en ajoutant du code entre les crochets et les signes de pourcentage, comme indiqué dans l'exemple : “{% votre code ici %}”.
<head>
{% load static %}
<linkrel="stylesheet"type="text/CSS"href="{% static 'styles.css' %}"media="screen"/></head>
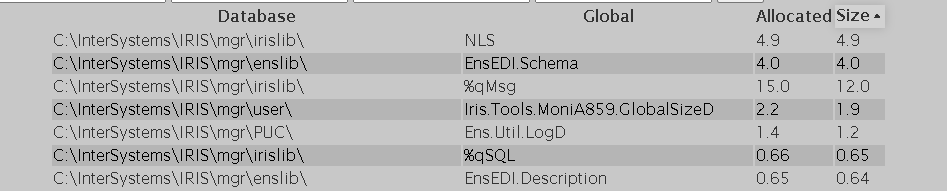
J'ai remplacé notre liste de globales par un tableau de globales avec une syntaxe similaire. Ensuite, j'ai ajouté au projet un espacement sympa entre les éléments ainsi que les couleurs de l'Innovatium. Vous pouvez consulter le fichier CSS que j'ai créé sur My GitHub et voir comment ce tableau a pris l'aspect illustré ci-dessous. Je ne suis pas un expert en CSS ou en conception de sites web. Cependant, si vous avez des questions, je serai heureux de les résoudre et même d'apprendre de nouvelles astuces ensemble. Laissez un commentaire ou envoyez-moi un message !
<table><thead><tr><th>Database</th><th>Global</th><th>Size</th><th>Allocated</th></tr></thead><tbody>
{% for global in globals %}
<tr><td>{{ global.database }}</td><td>{{ global.name }}</td><td>{{ global.size }}</td><td>{{ global.allocatedsize }}</td></tr>
{% endfor %}
</tbody></table>
PS. Si les fichiers statiques sont mis en cache, il est possible que les changements ne soient pas visibles lors du rechargement. Vous pouvez appuyer sur Ctrl+Shift+Delete et supprimer le cache stocké lorsque vous utilisez Google Chrome comme navigateur. Vous devez ensuite recharger votre page encore une fois. Si vous avez tout fait correctement, vous verrez ce qui suit dans votre terminal :
.png)
CONSEIL : pour éviter la nécessité de vider le cache à chaque fois que vous utilisez le programme, ajoutez la ligne suivante à l'en-tête de votre fichier HTML : <meta http-equiv="cache-control" content="no-cache" />. Cette balise devrait empêcher la page de stocker le cache.
Exportation de données
Dans cette section, nous revenons au back-end. Il vous sera utile de revoir la partie 1 de cette série d'articles si vous ne connaissez pas le chemin des requêtes (modèle -> URL -> vue -> base de données et retour).
Nous mettrons en place un formulaire permettant à l'utilisateur de choisir entre l'exportation au format CSV, XML ou JSON, car cela couvre la plupart des utilisations pour le transfert de données. Et vous pouvez ajouter tous les langages que vous souhaitez. Pour cela, nous aurons besoin d'un formulaire avec une méthode HTTP, un jeton de sécurité, trois entrées radio et un bouton "Soumettre".
<formmethod="GET">
{% csrf_token %}
<inputtype="radio"name="exportLanguage"value="CSV"/><labelfor="CSV">CSV</label><inputtype="radio"name="exportLanguage"value="XML"/><labelfor="XML">XML</label><inputtype="radio"name="exportLanguage"value="JSON"/><labelfor="JSON">JSON</label><buttontype="submit"formaction="{% url 'export' %}"> Export </button></form>
Si vous désirez que les étiquettes affichent un texte "cliquable" pour la valeur correspondante, ajoutez la propriété onclick à l'étiquette avec la valeur getElementById(‘ID correspondant’).checked = true ainsi que les identifiants correspondants pour chaques option. La propriété formaction spécifiée dans le bouton renvoie à l'URL. Ainsi, vous pouvez avoir autant de boutons que vous le souhaitez pour indiquer différentes URL et soumettre le formulaire en conséquence.
Après avoir terminé l'étape précédente, nous pouvons ajouter le chemin qui nous dirige vers la vue sur urls.py et finalement créer la vue sur views.py. Cette vue peut sembler un peu plus complexe que celles que nous avons réalisées précédemment, mais, étape par étape, nous y parviendrons ensemble.
from .views import home, update, export
urlpatterns = [
path('', home),
path('update', update, name="update"),
path('export', export, name="export")
]
Il faut d'abord assigner une variable pour référencer les globales. Ensuite, nous devons créer un chemin où le fichier apparaîtra lorsque l'utilisateur cliquera sur le bouton d'exportation ( il pourra être modifié ultérieurement du côté client). Enfin, nous devons savoir quelle langage a été sélectionnée et procéder à l'exportation adéquate pour chacun d'entre eux.
import os
defexport(request):
globals = irisGlobal.objects.all()
cd = os.getcwd()
language = request.GET.get("exportLanguage") if language == "CSV":
passelif language == "XML":
passelif language == "JSON":
passreturn redirect(home)
Pour les CSV, il suffit de mettre chaque enregistrement sur une ligne et de séparer chaque colonne par une virgule. La manière la plus logique de procéder serait de concaténer toutes les informations relatives à chaque groupe dans une chaîne de caractères entre virgules, suivie d'un terminateur de ligne, et d'écrire chaque ligne dans le fichier.
if language == "CSV":
with open(cd+"\\test.csv", "w") as file:
for eachGlobal in globals:
row = eachGlobal.database+", "+eachGlobal.name+", "+str(eachGlobal.size)+", "+str(eachGlobal.allocatedsize)+"\n"
file.write(row)
Pour JSON et XML, les convertisseurs série de Django sont nécessaires. Ils peuvent sembler complexes, mais en réalité, ils sont assez simples. Le module convertisseur série possède deux méthodes: sérialisation and désérialisation, qui permettent de convertir des informations depuis et vers votre langage préféré. Heureusement, XML et JSON sont des options intégrées.
from django.core import serializers
[...]
elif language =="XML":
with open(cd+"\test.xml", "w") as file:
globals = serializers.serialize("xml", globals)
file.write(globals)
elif language =="JSON":
with open(cd+"\test.json", "w") as file:
globals = serializers.serialize("json", globals)
file.write(globals)
Bien joué ! L'application est enfin prête à être rechargée et testée. Après l'exportation, votre espace de travail devrait ressembler à l'image ci-dessous.
.png)
Filtres
Commençons par appliquer un filtre à une base de données. Nous devons créer une balise de formulaire avec une entrée de texte pour saisir le nom de la base de données et une référence à l'URL. Nous pouvons utiliser l'affichage d'accueil avec quelques adaptations.
<formmethod="GET"action="{% url 'home' %}">
{% csrf_token %}
<inputtype="text"name="database"placeholder="Database"/></form>
Puisque nous nous référons maintenant au chemin d'accès à partir de l'index, il faut le nommer sur les modèles, sur urls.py.
path('', home, name="home"),
Rappelez-vous que dans l'affichage d'accueil, nous obtenons toutes les globales du modèle avec irisGlobal.objects.all() et nous les renvoyons à l'index. À ce moment-là, nous ne devons renvoyer qu'un ensemble filtré de ces valeurs globales au lieu de toutes les valeurs. La bonne nouvelle est que nous allons résoudre ce problème avec quatre lignes de code seulement.
Tout d'abord, comme nous l'avons fait avec l'exportation, nous devons obtenir des informations de l'entrée avec request.GET.get() et réduire notre ensemble de globales en fonction de ce que notre utilisateur souhaite. Grâce à l'objet de requête de Django.db.models, nous pourrons utiliser la fonction de filtrage pour atteindre notre objectif.
from django.db.models import Sum, Q
from .models import irisGlobal
def home(request):
globals = irisGlobal.objects.all()
databaseFilter = request.GET.get("database")
if databaseFilter:
query = Q(database__contains=databaseFilter)
globals = globals.filter(query)
Le Q() est l'objet de requête. Au sein de cet objet, vous pouvez ajouter le nom d'une colonne, deux soulignements et une instruction SQL pour affiner la recherche. Ensuite, vous pouvez passer tous les objets Q nécessaires comme arguments de la fonction de filtrage, et ils seront unis par les opérateurs "AND" (à moins qu'il ne soit spécifié le contraire). Il y a beaucoup d'autres choses que vous pouvez faire avec la classe Q. Pour en savoir plus sur cette classe et sur d'autres façons d'effectuer des requêtes avec Django, consultez la documentation officielle).
Vous pouvez maintenant recharger et tester vos filtres. N'oubliez pas de prêter attention à la façon dont les agrégateurs à la fin de la page s'adaptent aux filtres puisque nous les avons construits à partir de la variable de globales globals .
Plus de filtres !
Si vous êtes à l'aise avec la dernière section, le sujet peut être abordé avec plus d'assurance. Il est temps d'ajouter d'autres filtres et de les combiner. Pour commencer, ajoutez quelques entrées supplémentaires à notre formulaire.
<formmethod="GET">
{% csrf_token %}
<inputtype="text"name="database"placeholder="Database"/><inputtype="text"name="global"placeholder="Global name"/><inputtype="number"name="size"placeholder="Size"step="0.001"/><inputtype="number"name="allocated"placeholder="Allocated size"step="0.001"/><buttontype="submit"formaction="{% url 'home' %}"> Filter </button></form>
à l'affichage, ajoutez les nouveaux filtres à la variable globals. Ils doivent s'enchaîner et être équivalents à l'instruction SQL ci-dessous.
On the view, add the new filters to the variable globals. They should chain and be equivalent to the SQL statement below.
SELECT * FROM globals
WHERE database LIKE ‘%databaseFilter%’ AND
globals LIKE ‘%globalsFilter%’ AND
size >=sizeFilter AND
allocatedsize>=allocFilter
globals = irisGlobal.objects.all()
databaseFilter = request.GET.get("database")
globalFilter = request.GET.get("global")
sizeFilter = request.GET.get("size")
allocFilter = request.GET.get("allocated")
if databaseFilter:
globals = globals.filter(Q(database__contains=databaseFilter))
else:
databaseFilter=""if globalFilter:
globals = globals.filter(Q(name__contains=globalFilter))
else:
globalFilter=""if sizeFilter:
globals = globals.filter(Q(size__gte=sizeFilter))
else:
sizeFilter=""if allocFilter:
globals = globals.filter(Q(allocatedsize__gte=allocFilter))
else:
allocFilter=""
Le filtre fonctionne déjà, mais il peut encore être quelque peu amélioré. Si nous transmettons les variables reçues au retour, nous pourrons les utiliser comme valeurs dans les entrées. Elles ne disparaîtront pas non plus lorsque nous rechargerons la page ou que nous appuierons sur le bouton filtre.
return render(request, "index.html", {"globals": globals,
"sumSize": sumSize,
"sumAllocated":sumAllocated,
"database":databaseFilter
"global":globalFilter
"size":sizeFilter,
"allocated":allocFilter
})
<formmethod="GET">
{% csrf_token %}
<inputtype="text"name="{{database}}"placeholder="Database"/><inputtype="text"name="{{global}}"placeholder="Global name"/><inputtype="number"name="{{size}}"placeholder="Size"step="0.001"/><inputtype="number"name="{{allocated}}"placeholder="Allocated size"step="0.001"/><buttontype="submit"formaction="{% url 'home' %}"> Filter </button></form>
Nous pouvons fournir aux filtres des options pour les mises à jour inférieures ou égales à une valeur spécifique. Nous pouvons même programmer des mises à jour en direct (mise à jour à chaque touche sur laquelle l'utilisateur appuie pendant la saisie des données). Pour l'instant, nous nous contenterons de garder ces idées à l'esprit et nous passerons à l'ajout d'un ordre.
Exportation d'un ensemble filtré
Après tout ce que nous avons fait, il est logique que vous souhaitiez adapter l'affichage de l'exportation pour utiliser tous les filtres que nous avons ajoutés.
Nous pouvons placer toute la logique que nous avons ajoutée à partir des filtres dans une fonction que nous appellerons handle_filters, et au lieu d'utiliser le tableau créé à partir de irisGlobals.objects.all() pour obtenir les informations, nous utiliserons le tableau créé par cette fonction. Pour que tout cela fonctionne, nous devons assembler les deux formulaires.
defhandle_filters(request):
globals = irisGlobal.objects.all()
databaseFilter = request.GET.get("database")
globalFilter = request.GET.get("global")
sizeFilter = request.GET.get("size")
allocFilter = request.GET.get("allocated")
<span class="hljs-keyword">if</span> databaseFilter:
globals = globals.filter(Q(database__contains=databaseFilter))
<span class="hljs-keyword">else</span>:
databaseFilter=<span class="hljs-string">""</span>
<span class="hljs-keyword">if</span> globalFilter:
globals = globals.filter(Q(name__contains=globalFilter))
<span class="hljs-keyword">else</span>:
globalFilter=<span class="hljs-string">""</span>
<span class="hljs-keyword">if</span> sizeFilter:
globals = globals.filter(Q(size__gte=sizeFilter))
<span class="hljs-keyword">else</span>:
sizeFilter=<span class="hljs-string">""</span>
<span class="hljs-keyword">if</span> allocFilter:
globals = globals.filter(Q(allocatedsize__gte=allocFilter))
<span class="hljs-keyword">else</span>:
allocFilter=<span class="hljs-string">""</span>
<span class="hljs-keyword">return</span> globals, databaseFilter, globalFilter, sizeFilter, allocFilter</code></pre>
defexport(request):
globals = handle_filters(request)[0]
<formmethod="GET">
{% csrf_token %}
<inputtype="radio"name="exportLanguage"value="CSV"/><labelfor="CSV">CSV</label><inputtype="radio"name="exportLanguage"value="XML"/><labelfor="XML">XML</label><inputtype="radio"name="exportLanguage"value="JSON"/><labelfor="JSON">JSON</label><buttontype="submit"formaction="{% url 'export' %}"> Export </button><br/><inputtype="text"name="{{database}}"placeholder="Database"/><inputtype="text"name="{{global}}"placeholder="Global name"/><inputtype="number"name="{{size}}"placeholder="Size"step="0.001"/><inputtype="number"name="{{allocated}}"placeholder="Allocated size"step="0.001"/><buttontype="submit"formaction="{% url 'home' %}"> Filter </button></form>
Order table (with JavaScript)
This section will show you how I added order options to the table. There are many ways to do it, but today we will use JavaScript to learn something different from what we have done previously. Of course, it would be better if you had some knowledge of the language’s basics, but you will be able to follow up anyway. Nevertheless, the main focus is to understand the connections. They will be very similar to the CSS’s and will open even more doors for you to manage data from the portal.
Let’s begin! Open the index.html and add two <script> tags at the very bottom of the body. The first one should reference the dependencies. The second one will point to a .js file in our project (we will create it in the next step). Since we already added ‘{% load static %}’, this will be enough for the JavaScript file to start working.
<scriptsrc="https://ajax.googleapis.com/ajax/libs/jquery/1.11.1/jquery.min.js"></script><scriptsrc="{% static 'index.js'%}"></script>
Tableau de commandes (avec JavaScript)
Cette section vous montrera la manière dont j'ai ajouté des options de commande au tableau. Il existe de nombreuses façons de le faire, mais aujourd'hui nous allons utiliser JavaScript pour apprendre quelque chose de différent de ce que nous avons fait précédemment. Bien sûr, il serait préférable que vous ayez une certaine connaissance des bases du langage, mais vous pourrez suivre de toute façon. Néanmoins, l'objectif principal est de comprendre les connexions. Elles seront très similaires à celles du CSS et vous offriront encore plus de possibilités pour gérer les données du portail.
Commençons ! Ouvrez le fichier index.html et ajoutez deux balises tout en bas du corps. La première doit faire référence aux dépendances. La deuxième pointera vers un fichier .js dans notre projet (nous le créerons à l'étape suivante). Comme nous avons déjà ajouté "{% load static %}", cela suffira pour que le fichier JavaScript démarre.
<scriptsrc="https://ajax.googleapis.com/ajax/libs/jquery/1.11.1/jquery.min.js"></script><scriptsrc="{% static 'index.js'%}"></script>
Une fois la connexion établie, créez un fichier dans le dossier /static, et nommez-le index.js (ou quel que soit le nom que vous lui avez donné dans la référence). Si, à cette étape, vous ajoutez un console.log(“Hello world!”); au fichier et rechargez la page, vous verrez qu'il fonctionne déjà. Cela signifie que nous pouvons enfin commencer à créer la logique de commande.
Nous voulons que le tableau soit dans l'ordre lorsque l'utilisateur clique sur un en-tête. Pour ce faire, il nous faut que l'affichage obéisse à l'utilisateur chaque fois qu'il clique sur l'un de ces en-têtes. Nous disposons du document à partir duquel nous sélectionnons chaque
élément du tableau et, pour chacun d'entre eux, nous voulons savoir quand il est cliqué.
<pre class="codeblock-container" idlang="5" lang="JavaScript" tabsize="4"><code class="language-javascript hljs"><span class="hljs-built_in">document</span>.querySelectorAll(<span class="hljs-string">"table th"</span>).forEach(<span class="hljs-function"><span class="hljs-params">header</span> =></span> {
header.addEventListener(<span class="hljs-string">"click"</span>, () => {
});
}) Nous pouvons maintenant lui communiquer ce qu'il doit faire une fois qu'il a reçu l'événement "click". Nous aurons besoin du tableau (le parent de , qui est le parent de , qui est le parent du "cliqué" | ) et d'un nombre indiquant quel en-tête a été sélectionné. Nous devons également savoir si le tableau est déjà dans l'ordre croissant pour cette colonne. Nous pouvons alors appeler une fonction pour trier le tableau.
| <pre class="codeblock-container" idlang="5" lang="JavaScript" tabsize="4"><code class="language-javascript hljs"><span class="hljs-built_in">document</span>.querySelectorAll(<span class="hljs-string">"table th"</span>).forEach(<span class="hljs-function"><span class="hljs-params">header</span> =></span> {
header.addEventListener(<span class="hljs-string">"click"</span>, () => {
<span class="hljs-keyword">const</span> table = header.parentElement.parentElement.parentElement;
<span class="hljs-keyword">const</span> columnIndex = <span class="hljs-built_in">Array</span>.prototype.indexOf.call(header.parentElement.children, header);
<span class="hljs-keyword">const</span> isAscending = header.classList.contains(<span class="hljs-string">"ascending"</span>);
sortTable(table, columnIndex+<span class="hljs-number">1</span>, !isAscending);
});
}) Il existe de nombreux algorithmes prédéfinis pour le tri des tableaux. Vous pouvez même télécharger et utiliser certains d'entre eux. Je veux éviter d'ajouter d'autres dépendances à ce projet. C'est pourquoi je m'en tiendrai à l'algorithme suivant. document.querySelectorAll("table th").forEach(header => {
header.addEventListener("click", () => {
const table = header.parentElement.parentElement.parentElement;
const columnIndex = Array.prototype.indexOf.call(header.parentElement.children, header);
const isAscending = header.classList.contains("ascending");
sortTable(table, columnIndex+1, !isAscending);
});
})
There are many pre-built sorting table algorithms. You can even download and use some of them. I want to avoid adding more dependencies to this project. For that reason, I will stick to using the following algorithm. functionsortTable(table, columnIndex, ascending = true) {
const direction = ascending ? 1 : -1; const header = $('th:nth-child('+columnIndex+')'); const body = table.children[1] const rows = Array.from(body.querySelectorAll("tr"));
table.querySelectorAll("th").forEach(th => th.classList.remove("ascending", "descending"));
<span class="hljs-comment">// adds the order to the clicked header</span>
header[<span class="hljs-number">0</span>].classList.toggle(<span class="hljs-string">"ascending"</span>, ascending);
header[<span class="hljs-number">0</span>].classList.toggle(<span class="hljs-string">"descending"</span>, !ascending);
<span class="hljs-comment">// algorithm for sorting the rows</span>
<span class="hljs-keyword">const</span> sorted = rows.sort(<span class="hljs-function">(<span class="hljs-params">a, b</span>) =></span> {
<span class="hljs-keyword">const</span> aColumn = a.querySelector(<span class="hljs-string">'td:nth-child('</span>+columnIndex+<span class="hljs-string">')'</span>).textContent;
<span class="hljs-keyword">const</span> bColumn = b.querySelector(<span class="hljs-string">'td:nth-child('</span>+columnIndex+<span class="hljs-string">')'</span>).textContent;
<span class="hljs-keyword">return</span> aColumn > bColumn ? (<span class="hljs-number">1</span>*direction) : (<span class="hljs-number">-1</span>*direction);
});
<span class="hljs-comment">// removes the rows from the body and add the sorted rows</span>
<span class="hljs-keyword">while</span> (body.firstChild) {
body.removeChild(body.firstChild);
}
body.append(...sorted);
}
La référence suivante explique l'algorithme susmentionné. https://dcode.domenade.com/tutorials/how-to-easily-sort-html-tables-with-css-and-javascript Maintenant, avec un peu de CSS, vous avez un tableau parfaitement ordonné.
.ascending::after {
content: "\25be";
}
.descending::after {
content: "\25b4";
} .ascending, .descending {
background-color: #ffffff30;
box-shadow: .1px .1px10.px #aaa;
}
Une approche différente de l'ajout d'ordre Une autre façon d'ajouter de l'ordre serait de créer un formulaire avec une option pour choisir chaque colonne (avec un peu de JavaScript, vous pouvez également utiliser les en-têtes pour la sélection), de le diriger vers un affichage qui utilise la fonction .order_by(“nom de la colonne”) sur l'objet globals, et de le renvoyer ordonné sur la fonction de rendu. Les deux options sont implémentées sur mon GitHub si vous voulez le vérifier. Faites attention au fait que dans la première méthode, nous ne changeons pas les données ou l'ensemble des résultats. Puisque nous ajustons seulement la façon dont elles sont affichées, cela n'affectera pas l'exportation. Un autre conseil sur JavaScript J'ai préparé pour vous une dernière chose qui pourrait être utile à connaître lorsque vous utilisez Django et JavaScript. Si vous voulez rediriger vers une URL (par exemple, la mise à jour), vous pouvez utiliser document.location.href = “update”; dans le fichier .js. Si je suis un IRIS Dev, pourquoi voudrais-je savoir cela ?Vous avez peut-être observé que l'ensemble de cet article n'utilise pas directement IRIS. Les tutoriels de la partie 2 seraient très similaires si nous utilisions n'importe quelle autre base de données. Cependant, si nous construisons tout ce qui est décrit ci-dessus en utilisant la technologie d'InterSystems comme base, nous aurons la possibilité d'adapter ce portail pour exécuter ou montrer beaucoup plus de choses en toute simplicité. Si vous êtes déjà un développeur IRIS, vous pouvez facilement imaginer comment ce simple portail peut combiner des informations provenant d'origines multiples (pas nécessairement globales), en plus de la capacité à fournir toutes sortes de traitements et d'analyses de données, avec les outils Cloud, IntegratedML (Machine Learning), Business Intelligence, Text Analytics et Natural Language Processing (NLP), etc. Lorsque tous les outils fournis par InterSystems offrent une interactivité complète, facile et magnifique avec les utilisateurs, à condition que toute la sécurité nécessaire soit en place, les possibilités dépassent l'imagination. J'ai rassemblé ici quelques exemples pour illustrer mon point de vue. Vous pouvez avoir un capteur qui envoie des informations à l'API Callin d'InterSystems, intégré à un programme en C++. Ces données peuvent être interprétées, traitées et stockées dans IRIS, et leur analyse peut être affichée avec Django, ce qui permet à l'utilisateur de l'utiliser. Combiné avec InterSystems IRIS for Health et HealthShare, ce portail devient un outil de suivi des patients en thérapie. Il peut utiliser l'apprentissage automatique et la BI pour détecter et prédire les changements dangereux et envoyer des alertes avec SAM (System Alerting and Monitoring) au médecin responsable, qui peut être affiché sur le portail avec toutes les informations relatives au cas requises pour prendre une décision rapide. Dans un autre contexte, mais avec une logique similaire, InterSystems IRIS for Supply Chain peut être utilisé avec ce portail pour permettre à l'utilisateur de voir ce qui pourrait compromettre le fonctionnement du système. Cette collaboration nous permet de prendre et de transmettre des décisions d'une manière qui rend l'ensemble de l'opération facilement compréhensible et contrôlable.
|
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)



.png)


.png)

.png)



.png)
.png)

.png)

.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)





.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)

.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)














.png)
.png)
.png)











.png)
.png)
.png)

