Parmi les points problématiques de la maintenance des interfaces HL7 figure la nécessité d'effectuer un test de régression fiable lors du déploiement dans de nouveaux environnements et après les mises à jour. La classe %UnitTest permet de créer des tests unitaires et de les intégrer au code de l'interface. Les données de test peuvent également être enregistrées au sein de la classe de test unitaire, ce qui permet de réaliser rapidement et facilement des tests de fumée et des tests de régression.
##Ressources:
##Scénario:
Une classe de test unitaire sera créée pour chaque flux entrant en fonction des exigences en matière de profilage, de routage et de mappage des données.
- Exigences relatives aux échantillons:*
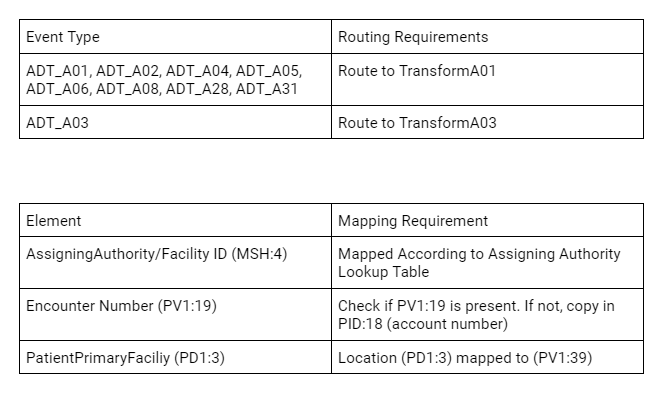
Pour tester chaque scénario, nous devons lancer un échantillon pour chaque type d'événement et confirmer les règles de routage. Il nous faut également confirmer les exigences spécifiques en matière de mappage et trouver des exemples de données pour chaque scénario.
##Production HL7
L'objectif de ce UnitTest-RuleSet est de tester un pipeline HL7 : Service métier → Règles de routage → Transformation.
Dans cet exemple créé pour la production illustrée ci-dessous, le flux de processus ADT passe par plusieurs sauts supplémentaires. Une classe étendant UnitTest.RuleSet.HL7 a été modifiée pour permettre de traiter des flux de processus plus complexes.
Flux de processus: FromHSROUTER.TESTAdt → FromTESTAdt.ReorgSegmentProcess → RouteTESTAdt → TEST.ADTTransform → HS.Gateway.HL7.InboundProcess

##Création d'une Classe de Test Unitaire
Créez une classe TestAdtUnitTest qui étend UnitTest.RuleSet.HL7. (UnitTest.RuleSet.Example dans le référentiel UnitTest-RuleSet contient un exemple d'une telle classe.
*Remarque: Dans cet exemple, tout a été déplacé sous HS.Local dans HSCUSTOM pour faciliter les tests. *
Signature:Class HS.Local.EG.UnitTest.TestAdtUnitTest Extends HS.Local.Util.UnitTest.RuleSet.HL7
##Aperçu de la structure des classes
La classe de test unitaire est organisée de la manière suivante:

##Paramètres de configuration
Ces paramètres de classe sont utilisés pour configurer les tests.
// Espace de noms où la production est située
Parameter Namespace = "EGTEST";
// Répertoire de base pour les tests unitaires
Parameter TestDirectory = "/tmp/unittest";
// nom du sous-répertoire pour les tests unitaires
Parameter TestSuite = "TEST-HL7ADT";
/// Remplacement pour un schéma différent
Parameter HL7Schema = "2.5.1:ADT_A01";
/// Remplacement par le nom du service existant en production
Parameter SourceBusinessServiceName = "FromHSROUTER.TESTAdt";
/// Remplacer par le nom du moteur de routage de processus métier existant en production
Parameter TargetConfigName = "FromTESTAdt.ReorgSegmentProcess";
/// Nom du processus de routage primaire en production
Parameter PrimaryRoutingProcessName = "RouteTESTAdt";
/// Nom du processus de routage secondaire en production
Parameter SecondaryRoutingProcessName = "TEST.ADTTransform";
Remarque: Les processus de routage primaire et secondaire sont référencés dans les différentes méthodes de test afin de tester la sortie et les résultats de deux processus de routage enchaînés.
##Création d'exemples de messages d'entrée
Pour créer une classe de test unitaire réutilisable, il faut enregistrer des échantillons anonymes pour chaque type d'événement et tout message supplémentaire nécessaire à la réalisation des scénarios de test dans la classe de test unitaire, dans des blocs XDATA au bas du fichier.
Le nom *SourceMessageA01 * est utilisé pour référencer le bloc XDATA spécifique.
XData SourceMessageA01
{
<![CDATA[
MSH|^~\&|Epic|TEST||TEST|20230911060119|RUBBLE|ADT^A01|249509431|P|2.2
EVN|A01|20230911060119||ADT_EVENT|RUBBLE^MATTHEW^BARNEY^D^^^^^TEST^^^^^UH|20230911060000|PHL^PHL^ADTEDI
ZVN||LS23450^LS-23450^^^^RTL
PID|1|000163387^^^MRN^MRN|000163387^^^MRN^MRN||FLINTSTONE^ANNA^WILMA||19690812|F|MURRAY^ANNA~FLINTSTONE^ANNA^R~FLINTSTONE^ANNA|B|100 BEDROCK WAY^^NORTH CHARLESTON^SC^29420-8707^US^P^^CHARLESTON|CHAR|(555)609-0969^P^PH^^^555^6090969~^NET^Internet^ANNAC1@YAHOO.COM~(555)609-0969^P^CP^^^555^6090969||ENG|M|CHR|1197112023|260-61-5801|||1|||||Non Veteran|||N
ZPD||MYCH||AC|||N||N
PD1|||TEST HOLLINGS CANCER CENTER^^10003|1134107873^LINK^MICHAEL^J^^^^^EPIC^^^^PNPI
ROL|1|UP|GENERAL|1134107873^LINK^MICHAEL^J^^^^^EPIC^^^^PNPI|20211115
NK1|1|GABLE^BETTY|PARENT||(555)763-5651^^PH^^^555^7635651||Emergency Contact 1
NK1|2|FLINTSTONE^FRED|Spouse|100 Bedrock way^^REMBERT^SC^29128^US|(888)222-2222^^PH^^^888^2222222|(888)222-3333^^PH^^^888^2223333|Emergency Contact 2
PV1|1|O|R1OR^RTOR^07^RT^R^^^^TEST RT OR|EL|||1386757342^HALSTEAD^LUCINDA^A.^^^^^EPIC^^^^PNPI|1386757342^HALSTEAD^LUCINDA^A.^^^^^EPIC^^^^PNPI||OTO||||PHYS|||1386757342^HALSTEAD^LUCINDA^A.^^^^^EPIC^^^^PNPI|SO||BCBS|||||||||||||||||||||ADMCONF|||20230911060000
PV2||PRV||||||20230911||||HOSP ENC|||||||||N|N||||||||||N
ZPV||||||||||||20230911060000
OBX|1|NM|PRIMARYCSN|1|1197112023||||||F
AL1|1|DA|900525^FISH CONTAINING PRODUCTS^DAM|3|Anaphylaxis|20210823
AL1|2|DA|568^PEANUT^HIC|3|Anaphylaxis|20221209
AL1|3|DA|12753^TREE NUT^HIC|3|Anaphylaxis|20221209
AL1|4|DA|1193^TREE NUTS^DAM|3|Anaphylaxis|20130524
AL1|5|DA|1554^HYDROCODONE^HIC||Other|20210728
AL1|6|DA|3102^POLLEN EXTRACTS^HIC||Other|20201204
AL1|7|DA|11754^SHELLFISH DERIVED^HIC||Other|20210728
DG1|1|I10|Q85.02^Neurofibromatosis, type 2^I10|Neurofibromatosis, type 2||ADMISSION DIAGNOSIS (CODED)
DG1|2|I10|D33.3^Benign neoplasm of cranial nerves^I10|Benign neoplasm of cranial nerves||ADMISSION DIAGNOSIS (CODED)
DG1|3|I10|J38.01^Paralysis of vocal cords and larynx, unilateral^I10|Paralysis of vocal cords and larynx, unilateral||ADMISSION DIAGNOSIS (CODED)
DG1|4||^NF2 (neurofibromatosis 2) [Q85.02]|NF2 (neurofibromatosis 2) [Q85.02]||ADMISSION DIAGNOSIS (TEXT)
DG1|5||^Acoustic neuroma [D33.3]|Acoustic neuroma [D33.3]||ADMISSION DIAGNOSIS (TEXT)
DG1|6||^Unilateral complete paralysis of vocal cord [J38.01]|Unilateral complete paralysis of vocal cord [J38.01]||ADMISSION DIAGNOSIS (TEXT)
GT1|1|780223|FLINTSTONE^ANNA^WILMA^^^^L||100 BEDROCK WAY^^NORTH CHARLESTON^SC^29420-8707^US^^^CHARLESTON|(555)609-0969^P^PH^^^555^6090969~(555)763-5651^P^CP^^^555^7635651||19690812|F|P/F|SL|248-61-5801|||||^^^^^US|||Full
ZG1||||1
IN1|1|BL90^BCBS/STATE EMP^PLANID||BCBS STATE|ATTN CLAIMS PROCESSING^PO BOX 100605^COLUMBIA^SC^29260-0605||(800)444-4311^^^^^800^4444311|002038404||||20140101||NPR||FLINTSTONE^THOMAS^^V|Sp|19661227|3310 DUBIN RD^^NORTH CHARLESTON^SC^29420^US|||1|||||||||||||1087807|ZCS49984141|||||||M|^^^^^US|||BOTH
IN3|1|||2||20230911|20230911|RUBBLE^MATTHEW^BARNEY^D|||NOT|||||(800)999-0000^^^^^800^9990000~(888)444-5555^^^^^888^4445555
ZIN|||||||FLINTSTONE^THOMAS^^V|||||16871492
]]>
}
Exemple de code permettant d'extraire des données d'un bloc XDATA pour les utiliser dans le cadre de tests :
set xdata=##class(%Dictionary.CompiledXData).%OpenId(..%ClassName(1)_"||"_XDataName,0)
Voici un exemple de code de ** GetMessage**, une méthode d'assistance utilisée pour lire et renvoyer les données d'un bloc XDATA en fonction du nom du bloc.
ClassMethod GetMessage(XDataName As %String) As EnsLib.HL7.Message
{
#dim SourceMessage as EnsLib.HL7.Message
set xdata=##class(%Dictionary.CompiledXData).%OpenId(..%ClassName(1)_"||"XDataName,0)
quit:'$IsObject(xdata) $$$NULLOREF
set lines=""
while 'xdata.Data.AtEnd
{
set line=$ZSTRIP(xdata.Data.ReadLine(),"<w")
continue:line=""
continue:$Extract(line,1)="<" // ignorer les balises XML ouvrantes ou fermantes et commencer la balise CData
continue:$Extract(line,1)="]" // ignorer ]]> closing CDATA
set lines=lines($S($L(lines)=0:"",1:$C(..#NewLine)))_line
}
set SourceMessage=##class(EnsLib.HL7.Message).ImportFromString(lines,.tSC)
quit:$$$ISERR(tSC) $$$NULLOREF
set SourceMessage.DocType=..#HL7Schema
set tSC=SourceMessage.PokeDocType(..#HL7Schema)
quit SourceMessage
}
##Création de méthodes de test
La classe de test unitaire contient également une méthode de test qui configure chaque test de manière programmatique, injecte le message dans la production et vérifie que le message transformé qui en résulte correspond à ce qui est attendu.
L'exemple de test contient les méthodes de test suivantes :
- TestMessageA01
- TestMessageA02
- TestMessageA03
- TestMessageA04
- TestMessageA05
- TestMessageA06
- TestMessageA08
- TestMessageA28
- TestMessageA31
- TestCorrectAssigningAuthorityForA01
- TestEncoutnerNumberPresent
- TestPD1LocationMapped
Exemple de méthode: TestMessageA01
Méthode permettant de vérifier que les messages A01 sont traités sans erreur et routés vers la transformation correcte.
Method TestMessageA01()
{
Set ReturnA01 = ..#SecondaryRoutingProcessName_":HS.Local.EG.ProfSvcs.Router.Base.ADT.TransformA01"
#dim message as EnsLib.HL7.Message
// Télécharger un nouveau message HL7 par UnitTest
set ..HL7Message=..GetMessage("SourceMessageA01")
quit:'$IsObject(..HL7Message) $$$ERROR(5001,"Failed to correlate Xdata for Source Message")
set routingProcess = ..#PrimaryRoutingProcessName
set message=..HL7Message.%ConstructClone(1)
do message.PokeDocType(message.DocType)
do message.SetValueAt("SYSA","MSH:3.1")
set expectSuccess=1
set expectReturn="send:"_ReturnA01
set expectReason="rule#8"
do ..SendMessageToRouter(message,"TestMessageA01",routingProcess, expectSuccess, expectReturn, expectReason)
}
Remarque: SendMessageToRouter() est une méthode mise en œuvre dans le paquet UnitTest-RuleSet.
Exemple de méthode: TestEncounterNumberPresent
La méthode ci-dessous vérifie la présence de valeurs spécifiques dans le message après la transformation.
Method TestEncounterNumberPresent()
{
#dim message as EnsLib.HL7.Message
// Télécharger un nouveau message HL7 par UnitTest
set ..HL7Message=..GetMessage("SourceMessageA01")
quit:'$IsObject(..HL7Message) $$$ERROR(5001,"Failed to correlate Xdata for Source Message")
// source du processus de transformation
set routingProcess = ..#SecondaryRoutingProcessName
set message=..HL7Message.%ConstructClone(1)
do message.PokeDocType(message.DocType)
do message.SetValueAt("SYSA","MSH:3.1")
// Vérifier que la sortie PV1:19 n'est pas vide
set expectSuccess=1
set expectElement="PV1:19"
set expectReturnVal="1197112023"
do ..SendMessageReturnOutput(message,"TestMessageA01", routingProcess, expectSuccess, expectElement, expectReturnVal)
}
Remarque: SendMessageReturnOutput() est une méthode modifiée pour renvoyer le message résultatif pour évaluation.
##Comment exécuter le UnitTest
Les mises en œuvre de la classe %UnitTest dépend de la globale ^UnitTestRoot pour l'emplacement des dossiers de travail des tests unitaires.
Il y a deux paramètres utilisés pour définir les dossiers:
// Répertoire de base pour les tests unitaires
Parameter TestDirectory = "/tmp/unittest";
// nom du sous-répertoire pour les tests unitaires
Parameter TestSuite = "TEST-HL7ADT";
Dans ce cas, la classe s'attend à ce que le dossier : /tmp/unittest/TEST-HL7ADT soit présent dans l'environnement où la classe de test unitaire est exécutée.
En outre, la mise en œuvre personnalisée définit la globale ^UnitTestRoot et passe à l'espace de noms spécifique dans le paramètre d'espace de noms Namespace.
Pour le lancement depuis le terminal:
HSCUSTOM> do ##class(HS.Local.EG.UnitTest.TestAdtUnitTest).Debug()
Les résultats du lancement seront envoyés à la console. Si l'un des tests échoue, tout le test est considéré comme ayant échoué. Outre le terminal, on peut également consulter les résultats à partir du portail de gestion. Pour ouvrir l'URL, utilisez le lien figurant dans le résultat.
##Extrait du résultat de la Console
TestMessageA31 passed
TestPD1LocationMapped() begins ...
14:50:20.104:...t.TestAdtUnitTest: TestPD1Location Sent
LogMessage:SessionId was 130
LogMessage:Source Config Name name is :TEST.ADTTransform
LogMessage:Message Body Id was 94
LogMessage:Expect Success is 0
LogMessage:Testing for value PV1:39
LogMessage:Found value
AssertNotEquals:Expect No Match:TestPD1Location:ReturnValue= (failed) <<==== FAILED TEST-HL7ADT:HS.Local.EG.UnitTest.TestAdtUnitTest:TestPD1LocationMapped
LogMessage:Duration of execution: .033106 sec.
TestPD1LocationMapped failed
HS.Local.EG.UnitTest.TestAdtUnitTest failed
Skipping deleting classes
TEST-HL7ADT failed
Use the following URL to view the result:
http://192.168.1.229:52773/csp/sys/%25UnitTest.Portal.Indices.cls?Index=3&$NAMESPACE=EGTEST
Some tests FAILED in suites:
TEST-HL7ADT
##Affichage des résultats dans le portail de gestion
Utilisez l'URL affichée sur le terminal et copiez-la dans un navigateur pour voir les résultats. En cliquant sur le nom du test, vous obtiendrez des détails supplémentaires.
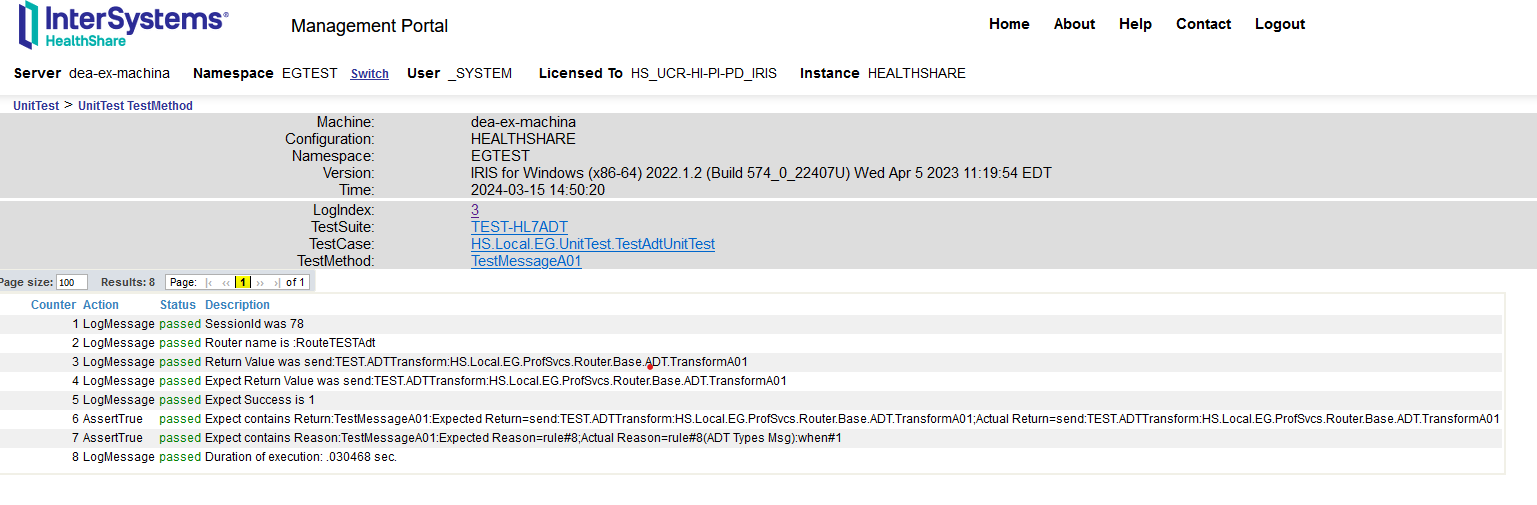
En cliquant sur le lien de chaque test, vous obtiendrez plus d'informations sur le test :
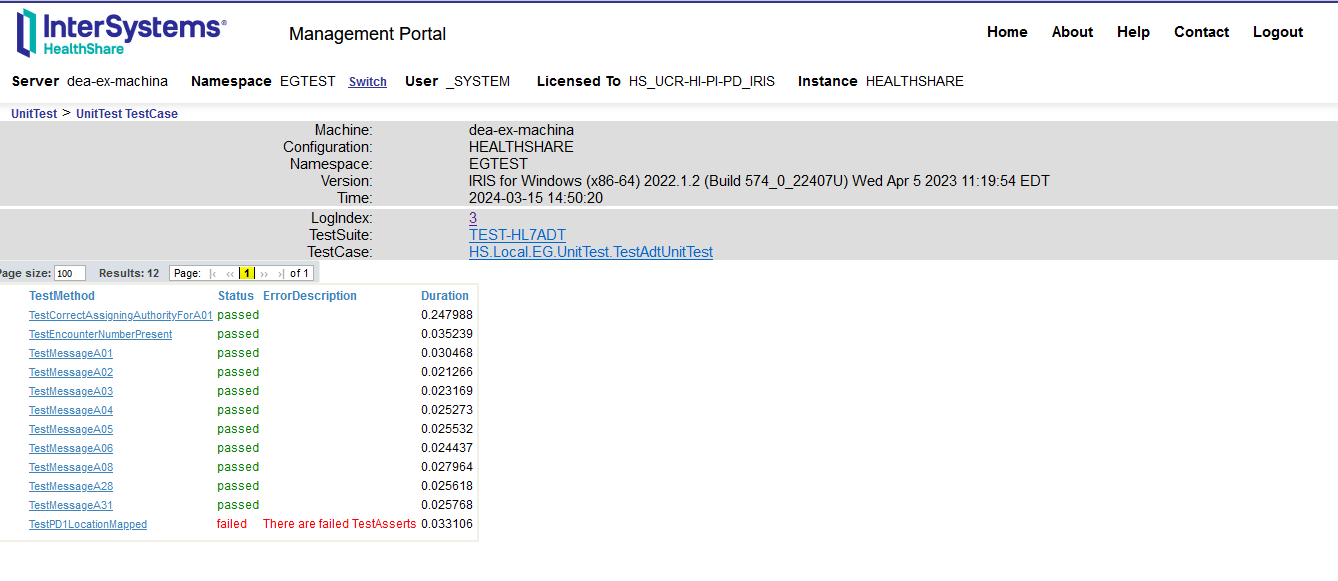
##Conclusion
La création de classes de tests unitaires pour chaque interface HL7 et leur intégration dans le code de l'interface permettent de documenter le processus de test et les échantillons de données, ainsi que de tester rapidement la régression de toute mise à jour ou modification des données ou de leur mise en œuvre.
Lors du déploiement, la classe de test unitaire sert de test de fumée autonome pour confirmer que l'interface est complète et fonctionnelle.
##Considérations supplémentaires
Le cadre UnitTest_RuleSet peut être adapté aux tests unitaires du CCDA. Les tests de routage sont relativement semblables à l'exemple HL7. Pour répondre aux exigences de mappage, il faut mettre en œuvre la classe de test unitaire pour gérer XSLT et XPaths.
Les responsables de l'assurance qualité peuvent recueillir des exigences et des échantillons de données pour configurer la classe de test unitaire avant le début de la mise en œuvre.
Les tests unitaires pour toutes les interfaces peuvent être regroupés dans le gestionnaire de tests unitaires (Unit Test Manager), de sorte que l'ensemble des tests peut être exécuté en une seule fois pour valider la configuration et le code existants.









.png)
.png)