Les entreprises doivent développer et gérer leurs infrastructures informatiques mondiales rapidement et efficacement tout en optimisant et en gérant les coûts et les dépenses d'investissement. Les services de calcul et de stockage Amazon Web Services (AWS) et Elastic Compute Cloud (EC2) couvrent les besoins des applications les plus exigeantes basées sur Caché en fournissant une infrastructure informatique mondiale très robuste. L'infrastructure Amazon EC2 permet aux entreprises de provisionner rapidement leur capacité de calcul et/ou d'étendre rapidement et de manière flexible leur infrastructure sur site existante dans le cloud. AWS fournit un riche ensemble de services et des mécanismes robustes, de niveau entreprise, pour la sécurité, la mise en réseau, le calcul et le stockage.
AAmazon EC2 est au cœur d'AWS. Une infrastructure de cloud computing qui prend en charge une variété de systèmes d'exploitation et de configurations de machines (par exemple, CPU, RAM, réseau). AWS fournit des images de machines virtuelles (VM) préconfigurées, appelées Amazon Machine Images ou AMI, avec des systèmes d'exploitation hôtes comprenant diverses distributions et versions de Linux® et de Windows. Ils peuvent avoir des logiciels supplémentaires utilisés comme base pour les instances virtualisées fonctionnant dans AWS. Vous pouvez utiliser ces AMI comme points de départ pour installer ou configurer des logiciels, des données et d'autres éléments supplémentaires afin de créer des AMI spécifiques aux applications ou aux charges de travail.
Comme pour toute plate-forme ou tout modèle de déploiement, il faut veiller à prendre en compte tous les aspects d'un environnement applicatif, tels que les performances, la disponibilité, les opérations et les procédures de gestion.
Ce document traite des spécificités de chacun des domaines suivants.
- • Installation et configuration du réseau. Cette section couvre la configuration du réseau pour les applications basées sur Caché dans AWS, y compris les sous-réseaux pour prendre en charge les groupes de serveurs logiques pour les différentes couches et rôles dans l'architecture de référence.
- • Installation et configuration du serveur. Cette section couvre les services et les ressources impliqués dans la conception des différents serveurs pour chaque couche. Il comprend également l'architecture pour la haute disponibilité à travers les zones de disponibilité.
- • Sécurité. Cette section aborde les mécanismes de sécurité dans AWS, notamment la manière de configurer l'instance et la sécurité du réseau pour permettre un accès autorisé à la solution globale ainsi qu'entre les couches et les instances.
- • Déploiement et gestion. Cette section fournit des détails sur la décompression, le déploiement, la surveillance et la gestion.
Ce document présente plusieurs architectures de référence au sein d'AWS à titre d'exemples pour fournir des applications robustes, performantes et hautement disponibles basées sur les technologies InterSystems, notamment Caché, Ensemble, HealthShare, TrakCare, et les technologies embarquées associées telles que DeepSee, iKnow, CSP, Zen et Zen Mojo.
Pour comprendre comment Caché et les composants associés peuvent être hébergés sur AWS, examinons d'abord l'architecture et les composants d'un déploiement typique de Caché et explorons quelques scénarios et topologies courants.
La plate-forme de données d'InterSystems évolue en permanence pour fournir un système de gestion de base de données avancé et un environnement de développement rapide d'applications permettant de réaliser des percées dans le traitement et l'analyse de modèles de données complexes et de développer des applications Web et mobiles.
Il s'agit d'une nouvelle génération de technologie de base de données qui offre de multiples modes d'accès aux données. Les données sont uniquement décrites dans un dictionnaire de données intégré unique et sont instantanément disponibles en utilisant l'accès aux objets, le SQL ¬haute performance et l'accès multidimensionnel puissant - qui peuvent tous accéder simultanément aux mêmes données.
La Figure-1 présente les niveaux de composants et les services disponibles dans l'architecture de haut niveau Caché. Ces niveaux généraux s'appliquent également aux produits InterSystems TrakCare et HealthShare.
Figure 1 : Niveaux de composants de haut niveau

There are numerous combinations possible for deployment, however in this document two scenarios will be covered; a hybrid model and complete cloud hosted model.
Dans ce scénario, une entreprise souhaite exploiter à la fois les ressources d'entreprise sur site et les ressources AWS EC2 pour la reprise après sinistre, les imprévus de maintenance interne, les initiatives de replatformage ou l'augmentation de la capacité à court ou à long terme, le cas échéant. Ce modèle peut offrir un niveau élevé de disponibilité pour la continuité des activités et la reprise après sinistre pour un ensemble de membres miroir de basculement sur site.
La connectivité pour ce modèle dans ce scénario est basée sur un tunnel VPN entre le déploiement sur site et la ou les zones de disponibilité AWS pour présenter les ressources AWS comme une extension du centre de données de l'entreprise. Il existe d'autres méthodes de connectivité telles que AWS Direct Connect. Cependant, cela n'est pas couvert dans le cadre de ce document. Vous trouverez plus de détails sur AWS Direct Connect ici.
Les détails de la configuration de cet exemple d'Amazon Virtual Private Cloud (VPC) pour soutenir la reprise après sinistre de votre centre de données sur¬ site peuvent être trouvés ici.
Figure 2 : Modèle hybride utilisant AWS VPC pour la reprise après sinistre sur site

L'exemple ci-dessus montre une paire de miroirs de basculement fonctionnant dans votre centre de données sur site avec une connexion VPN à votre VPC AWS. Le VPC illustré fournit plusieurs sous-réseaux dans des zones de disponibilité doubles dans une région AWS donnée. Il existe deux membres miroirs asynchrones de reprise après sinistre (DR) (un dans chaque zone de disponibilité) pour assurer la résilience.
Dans ce scénario, votre application basée sur le Cache, y compris les couches de données et de présentation, est entièrement conservée dans le cloud AWS en utilisant plusieurs zones de disponibilité au sein d'une même région AWS. Les mêmes modèles de tunnel VPN, AWS Direct Connect et même de connectivité Internet pure sont disponibles.
Figure 3 : Modèle hébergé dans le cloud prenant en charge la totalité de la charge de travail de production

L'exemple de la Figure-3 ci-dessus présente un modèle de déploiement permettant de prendre en charge un déploiement de production complet de votre application dans votre VPC. Ce modèle s'appuie sur des zones de disponibilité doubles avec une mise en miroir de basculement synchrone entre les zones de disponibilité, ainsi que sur des serveurs Web à charge équilibrée et des serveurs d'applications associés en tant que clients ECP. Chaque niveau est isolé dans un groupe de sécurité distinct pour les contrôles de sécurité du réseau. Les adresses IP et les plages de ports ne sont ouvertes que selon les besoins de votre application.
Plusieurs types d'options de stockage sont disponibles. Aux fins de cette architecture de référence, les volumes Amazon Elastic Block Store (Amazon EBS) et Amazon EC2 Instance Store (également appelés drives éphémères) sont examinés pour plusieurs cas d'utilisation possibles. Des détails supplémentaires sur les différentes options de stockage peuvent être trouvés ici et ici.
EBS fournit un stockage durable au niveau des blocs à utiliser avec les instances Amazon EC2 (machines virtuelles) qui peuvent être formatées et montées comme des systèmes de fichiers traditionnels sous Linux ou Windows. Plus important encore, les volumes constituent un stockage hors instance qui persiste indépendamment de la durée de vie d'une seule instance Amazon EC2, ce qui est important pour les systèmes de base de données.
En outre, Amazon EBS offre la possibilité de créer des instantanés ponctuels des volumes, qui sont conservés dans Amazon S3. Ces instantanés peuvent être utilisés comme point de départ pour de nouveaux volumes Amazon EBS, et pour protéger les données pour une durabilité à long terme. Le même instantané peut être utilisé pour instancier autant de volumes que vous le souhaitez. Ces instantanés peuvent être copiés entre les régions AWS, ce qui facilite l'exploitation de plusieurs régions AWS pour l'expansion géographique, la migration des centres de données et la reprise après sinistre. Les tailles des volumes Amazon EBS vont de 1 Go à 16 To, et sont alloués par incréments de 1 Go.
Au sein d'Amazon EBS, il existe trois types différents : Volumes magnétiques, Usage général (SSD) et IOPS provisionnés (SSD). Les sous-sections suivantes fournissent une brève description de chaque type.
Les volumes magnétiques offrent un stockage rentable pour les applications dont les exigences d'I/O sont modérées ou en rafale. Les volumes magnétiques sont conçus pour fournir une centaine d'opérations d'entrée/sortie par seconde (IOPS) en moyenne, avec une capacité optimale à atteindre des centaines d'IOPS. Les volumes magnétiques sont également bien adaptés à une utilisation en tant que volumes de démarrage, où la capacité d'éclatement permet des temps de démarrage d'instance rapides.
Les volumes à usage général (SSD) offrent un stockage rentable, idéal pour un large gamme de charges de travail. Ces volumes fournissent des latences inférieures à 10 millisecondes, avec la capacité d'émettre en rafale jusqu'à 3 000 IOPS pendant de longues périodes, et une performance de base de 3 IOPS/Go jusqu'à un maximum de 10 000 IOPS (à 3 334 Go). Levolumes à usage général (SSD) peuvent varier de 1 Go à 16 To.
Les volumes IOPS provisionnés (SSD) sont conçus pour offrir des performances élevées et prévisibles pour les charges de travail à forte intensité d'I/O, telles que les charges de travail de base de données qui sont sensibles aux performances de stockage et à la cohérence du débit d'I/O à accès aléatoire. Vous spécifiez un taux d'IOPS lors de la création d'un volume, et Amazon EBS fournit alors des performances à moins de 10 % de l'IOPS provisionné pendant 99,9 % du temps sur une année donnée. Un volume IOPS provisionné (SSD) peut avoir une taille comprise entre 4 Go et 16 To, et vous pouvez provisionner jusqu'à 20 000 IOPS par volume. Le rapport entre les IOPS provisionnés et la taille du volume demandé peut être de 30 maximum ; par exemple, un volume de 3 000 IOPS doit avoir une taille d'au moins 100 Go. Les volumes provisionnés IOPS (SSD) ont une limite de débit de 256 KB pour chaque IOPS provisionné, jusqu'à un maximum de 320 MB/seconde (à 1 280 IOPS).
Les architectures présentées dans ce document utilisent des volumes EBS, car ils sont mieux adaptés aux charges de travail de production qui nécessitent des opérations d'entrée/sortie par seconde (IOPS) et un débit prévisibles à faible latence. Il faut faire attention lors de la sélection d'un type de VM particulier car tous les types d'instance EC2 ne peuvent pas avoir accès au stockage EBS.
Note: Les volumes Amazon EBS étant des périphériques connectés au réseau, les autres I/O réseau effectuées par une instance Amazon EC2, ainsi que la charge totale sur le réseau partagé, peuvent affecter les performances des volumes Amazon EBS individuels. Pour permettre à vos instances Amazon EC2 d'utiliser pleinement les IOPS provisionnées sur un volume Amazon EBS, vous pouvez lancer certains types d'instances Amazon EC2 en tant qu'instances optimisées Amazon EBS.
Des détails sur les volumes EBS peuvent être trouvés ici.
Le stockage d'une instance EC2 consiste en un bloc de stockage sur un disque préconfiguré et préattaché sur le même serveur physique qui héberge votre instance Amazon EC2 en fonctionnement. La taille du stockage sur disque fourni varie selon le type d'instance Amazon EC2. Dans les familles d'instances Amazon EC2 qui fournissent le stockage d'instance, les instances plus grandes ont tendance à fournir des volumes de stockage d'instance à la fois plus nombreux et plus importants.
Il existe des familles d'instances Amazon EC2 optimisées pour le stockage (I2) et le stockage dense (D2) qui fournissent ¬un stockage d'instance à usage spécial, destiné à des cas d'utilisation spécifiques. Par exemple, les instances I2 fournissent un stockage d'instance très rapide sauvegardé par SSD, capable de prendre en charge plus de 365 000 IOPS en lecture aléatoire et 315 000 IOPS en écriture, et offrent des modèles de tarification économiquement intéressants.
Contrairement aux volumes EBS, le stockage n'est pas permanent et ne peut être utilisé que pendant la durée de vie de l'instance, et ne peut être détaché ou attaché à une autre instance. Le stockage d'instance est destiné au stockage temporaire d'informations qui changent continuellement. Dans le domaine des technologies et des produits InterSystems; des éléments tels que l'utilisation d'Ensemble ou de Health Connect en tant qu' Enterprise Service Bus (ESB), les serveurs d'applications utilisant le protocole ECP (Enterprise Cache Protocol) ou les serveurs Web avec CSP Gateway seraient d'excellents cas d'utilisation pour ce type de stockage et les types d'instances optimisées pour le stockage, ainsi que l'utilisation d'outils de provisionnement et d'automatisation pour rationaliser leur efficacité et soutenir l'élasticité.
Les détails sur les volumes de l'Instance store sont disponibles ici.
Il existe de nombreux types d'instances disponibles qui sont optimisés pour divers cas d'utilisation. Les types d'instance comprennent des combinaisons variables de CPU, de mémoire, de stockage et de capacités réseau, ce qui permet d'innombrables combinaisons pour adapter les ressources nécessaires à votre application.
Dans le cadre de ce document, les types d'instances Usage Général M4 d'Amazon EC2 seront référencés comme des moyens de dimensionner un environnement. Ces instances offrent des capacités de volume EBS et des optimisations. Des alternatives sont possibles en fonction des besoins en capacité et des modèles de tarification de votre application.
Les instances M4 sont la dernière génération d'instances Usage Général: Cette famille offre un équilibre entre les ressources de calcul, de mémoire et de réseau, et constitue un bon choix pour de nombreuses applications. Les capacités vont de 2 à 64 CPU virtuels et de 8 à 256 Go de mémoire avec une bande passante EBS dédiée correspondante.
En plus des types d'instances individuelles, il existe également des classifications à plusieurs niveaux telles que les Hôtes dédiés, les Instances ponctuelles, les Instances réservées et les Instances dédiées, chacune avec des degrés variables de prix, de performance et d'isolation.
Confirmer la disponibilité et les détails des instances actuellement disponibles ici.
Des serveurs web externes et internes à charge équilibrée peuvent être nécessaires pour votre application basée sur Caché. Les équilibreurs de charge externes sont utilisés pour l'accès par Internet ou WAN (VPN ou Direct Connect) et les équilibreurs de charge internes sont potentiellement utilisés pour le trafic interne. AWS Elastic Load Balancing fournit deux types d'équilibreurs de charge : l'équilibreur de charge Application load balancer et l'équilibreur de charge Classic Load balancer.
L'Équilibreur de charge Classic Load Balancer achemine le trafic en fonction des informations au niveau de l'application ou du réseau et est idéal pour un équilibrage de charge simple du trafic sur plusieurs instances EC2 nécessitant une haute disponibilité, une mise à l'échelle automatique et une sécurité robuste. Les détails et caractéristiques spécifiques sont disponibles ici.
Un équilibreur de charge Application Load Balancer est une option d'équilibrage de charge pour le service Elastic Load Balancing qui fonctionne au niveau de la couche applicative et vous permet de définir des règles de routage basées sur le content entre plusieurs services ou conteneurs fonctionnant sur une ou plusieurs instances Amazon EC2. De plus, il existe un support pour WebSockets et HTTP/2. Les détails et caractéristiques spécifiques sont disponibles ici.
L'exemple suivant définit un ensemble de trois serveurs web, chacun d'entre eux se trouvant dans une zone de disponibilité distincte afin de fournir les niveaux de disponibilité les plus élevés. Les équilibreurs de charge des serveurs Web doivent être configurés avec Sticky Sessions pour prendre en charge la possibilité d'attribuer les sessions des utilisateurs à des instances EC2 spécifiques à l'aide de cookies. Le trafic sera acheminé vers les mêmes instances à mesure que l'utilisateur continue d'accéder à votre application.
Le schéma suivant de la Figure-4 présente un exemple simple de l'équilibreur de charge Classic Load Balancer dans AWS.
Figure 4 : Exemple d'équilibreur de charge Classic Load Balancer

Lors du déploiement d'applications basées sur Caché sur AWS, la fourniture d'une haute disponibilité pour le serveur de base de données Caché nécessite l'utilisation d'une mise en miroir synchrone de la base de données afin de fournir une haute disponibilité dans une région AWS primaire donnée et potentiellement d'une mise en miroir asynchrone de la base de données pour répliquer les données vers une mise en veille prolongée dans une région AWS secondaire pour la reprise après sinistre en fonction de vos exigences en matière de contrats de niveau de service de disponibilité.
Un miroir de base de données est un regroupement logique de deux systèmes de base de données, appelés membres de basculement, qui sont des systèmes physiquement indépendants reliés uniquement par un réseau. Après avoir arbitré entre les deux systèmes, le miroir désigne automatiquement l'un d'entre eux comme système primaire ; l'autre membre devient automatiquement le système de sauveguarde. Les postes de travail clients externes ou d'autres ordinateurs se connectent au miroir par l'intermédiaire de l'IP virtuelle (VIP) du miroir, qui est spécifiée lors de la configuration de la mise en miroir. Le miroir VIP est automatiquement lié à une interface sur le système principal du miroir.
Note: Dans AWS, il n'est pas possible de configurer le VIP miroir de manière traditionnelle, une solution alternative a donc été conçue. Cependant, la mise en miroir est prise en charge sur tous les sous-réseaux.
La recommandation actuelle pour le déploiement d'un miroir de base de données dans AWS consiste à configurer trois instances (primaire, de sauvegarde, arbitre) dans le même VPC à travers trois zones de disponibilité différentes. Ainsi, à tout moment, AWS garantit la connectivité externe d'au moins deux de ces VM avec un SLA de 99,95 %. Cela permet une isolation et une redondance adéquates des données de la base de données elle-même. Les détails sur les accords de niveau de service AWS EC2 sont disponibles ici.
Il n'y a pas de limite supérieure rigide sur la latence du réseau entre les membres de basculement. L'impact de l'augmentation de la latence dépend de l'application. Si le temps aller-retour entre les membres de basculement est similaire au temps de service d'écriture au disque, aucun impact n'est attendu. La durée d'aller-retour peut toutefois poser problème lorsque l'application doit attendre que les données deviennent durables (ce que l'on appelle parfois la synchronisation du journal). Les détails de la mise en miroir de la base de données et de la latence du réseau sont disponibles ici.
La plupart des fournisseurs de cloud IaaS n'ont pas la capacité de fournir une adresse IP virtuelle (VIP) généralement utilisée dans les conceptions de basculement de base de données. Pour y remédier, plusieurs des méthodes de connectivité les plus couramment utilisées, notamment les clients ECP et les passerelles CSP Gateways, ont été améliorées dans Caché, Ensemble et HealthShare afin de ne plus dépendre des capacités VIP, ce qui les rend compatibles avec les miroirs.
Les méthodes de connectivité telles que xDBC, les sockets TCP/IP directs, ou d'autres protocoles de connexion directe, nécessitent toujours l'utilisation d'un VIP. Pour y remédier, la technologie de mise en miroir des bases de données d'InterSystems permet de fournir un basculement automatique pour ces méthodes de connectivité au sein d'AWS en utilisant des API pour interagir avec un équilibreur de charge élastique (ELB) d'AWS afin d'obtenir une fonctionnalité de type VIP, offrant ainsi une conception de haute disponibilité complète et robuste au sein d'AWS.
En outre, AWS a récemment introduit un nouveau type d'ELB appelé "Application Load Balancer". Ce type d'équilibreur de charge s'exécute à la Couche 7 et prend en charge le routage basé sur le contenu et les applications qui s'exécutent dans des conteneurs. Le routage basé sur le contenu est particulièrement utile pour les projets de type Big Data qui utilisent un déploiement de données partitionnées ou de partage de données.
Tout comme avec Virtual IP, il s'agit d'un changement brusque de la configuration du réseau et n'implique aucune logique applicative pour informer les clients existants connectés au membre miroir primaire défaillant qu'un basculement a lieu. Selon la nature de la défaillance, ces connexions peuvent être interrompues à cause de la défaillance elle-même, à cause d'un dépassement de délai ou d'une erreur de l'application, à cause du nouveau primaire qui force l'ancienne instance primaire à s'arrêter, ou à cause de l'expiration du timer TCP utilisé par le client.
Par conséquent, les utilisateurs peuvent être amenés à se reconnecter et à se loguer. Le comportement de votre application déterminerait ce comportement. Des détails sur les différents types d'ELB disponibles sont disponibles ici.
Méthode d'appel d'une instance AWS EC2 vers AWS Elastic Load Balancer
Dans ce modèle, l'ELB peut avoir un pool de serveurs défini avec des membres miroir de basculement et potentiellement des membres miroir asynchrones DR avec une seule des entrées actives qui est le membre miroir primaire actuel, ou seulement un pool de serveurs avec une seule entrée du membre miroir actif.
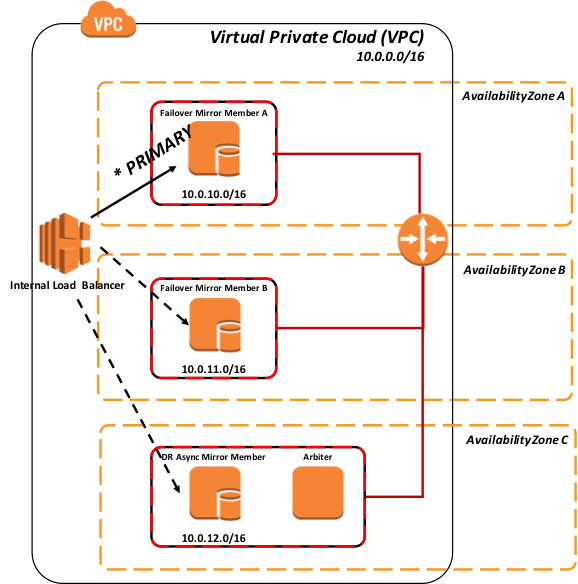
Figure 5 : Méthode API pour interagir avec Elastic Load Balancer (interne)

Lorsqu'un membre miroir devient le membre miroir primaire, un appel API est émis depuis votre instance EC2 vers l'AWS ELB pour ajuster/instruire l'ELB du nouveau membre miroir primaire.
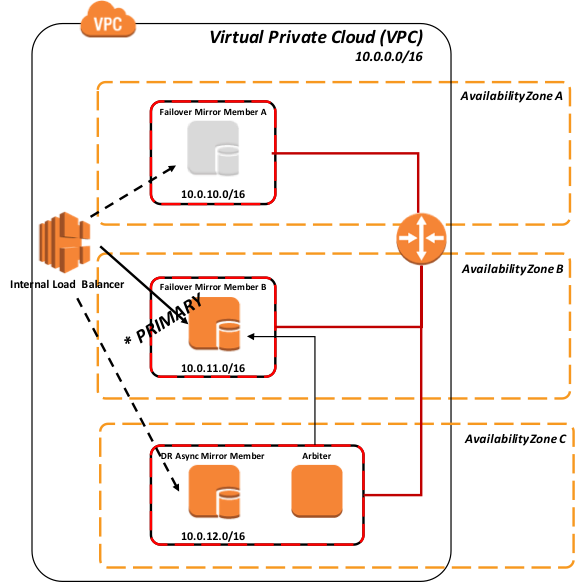
Figure 6 : Basculement vers le membre miroir B à l'aide de l'API pour l'équilibreur de charge

Le même modèle s'applique à la promotion d'un membre miroir asynchrone DR dans le cas où les membres miroirs primaire et de sauveguarde deviennent indisponibles.
Figure-7: Promotion du miroir asynchrone du DR vers le primaire en utilisant l'API vers l'équilibreur de charge
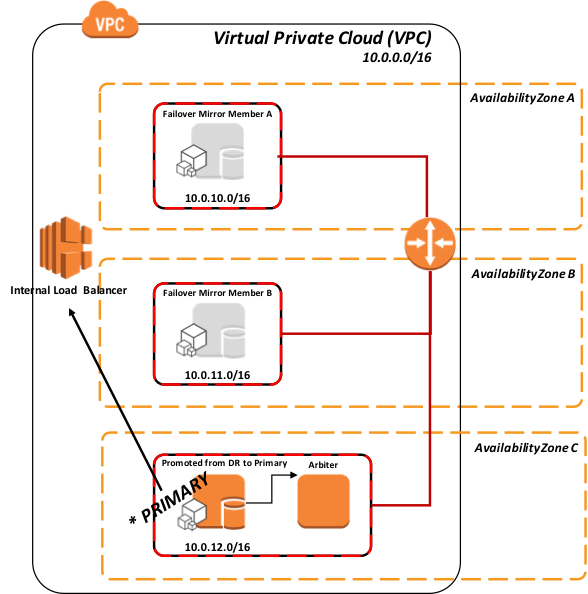
Conformément à la procédure DR standard recommandée, dans la Figure-6 ci-dessus, la promotion du membre DR implique une décision humaine en raison de la possibilité de perte de données due à la réplication asynchrone. Cependant, une fois cette mesure prise, aucune mesure administrative n'est requise sur ELB. Il achemine automatiquement le trafic une fois que l'API est appelée pendant la promotion.
Détails de l'API
Cette API pour appeler la ressource AWS load balancer est définie dans AZMIRROR routine spécifiquement dans le cadre de l'appel de procédure:
<strong><em>$$CheckBecomePrimaryOK^ZMIRROR()</em></strong>
Dans cette procédure, insérez la logique ou les méthodes API que vous avez choisi d'utiliser à partir d' AWS ELB REST API, de Command Line Interface, etc. Un moyen efficace et sécurisé d'interagir avec ELB est de recourir aux rôles AWS Identity and Access Management (IAM) afin de ne pas avoir à distribuer des informations d'identification à long terme à une instance EC2. Le rôle IAM fournit des autorisations temporaires que Caché peut utiliser pour interagir avec AWS ELB. Des détails sur l'utilisation des rôles IAM attribués à vos instances EC2 sont disponibles ici.
Méthode de sondage de l'équilibreur de charge AWS Elastic Load Balancer
Une méthode de sondage utilisant la page CSP Gateway mirror_status.cxw disponible en 2017.1 peut être utilisée comme méthode de sondage dans le moniteur de santé ELB pour chaque membre miroir ajouté au pool de serveurs ELB. Seul le miroir primaire répondra 'SUCCESS', dirigeant ainsi le trafic réseau uniquement vers le membre primaire actif du miroir.
Pour être ajoutée à AZMIROIR; cette méthode ne nécessite aucune logique . Veuillez noter que la plupart des dispositifs de réseau d'équilibrage de charge ont une limite sur la fréquence d'exécution de la vérification de l'état. En général, la fréquence la plus élevée n'est pas inférieure à 5 secondes, ce qui est généralement acceptable pour prendre en charge la plupart des accords de niveau de service en matière de disponibilité.
Une requête HTTP pour la ressource suivante testera l'état de membre miroir de la configuration LOCAL Cache.
_ /csp/bin/mirror_status.cxw_
Dans tous les autres cas, le chemin d'accès à ces demandes d'état miroir doit mener au serveur de cache et à l'espace de noms appropriés en utilisant le même mécanisme hiérarchique que celui utilisé pour demander des pages CSP réelles.
Exemple : Pour tester l'état du miroir de la configuration desservant les applications dans le chemin /csp/user/ path:
_ /csp/user/mirror_status.cxw_
Note: Une licence CSP n'est pas consommée en invoqueant une vérification de l'état du miroir.
Selon que l'instance cible est le membre primaire actif ou non, le Gateway renvoie l'une des réponses CSP suivantes:
**** Succès (Est le membre primaire)**
===============================
HTTP/1.1 200 OK
Content-Type: text/plain
Connection: close
Content-Length: 7
SUCCESS
**** Échec (N'est pas le membre primaire)**
===============================
HTTP/1.1 503 Service Unavailable
Content-Type: text/plain
Connection: close
Content-Length: 6
FAILED
**** Échec (Le serveur cache ne prend pas en charge la requête Mirror_Status.cxw)**
===============================
HTTP/1.1 500 Internal Server Error
Content-Type: text/plain
Connection: close
Content-Length: 6
FAILED
Les figures suivantes présentent les différents scénarios d'utilisation de la méthode de sondage.
Figure 8 : Sondage auprès de tous les membres du miroir
Comme le montre la Figure-8 ci-dessus, tous les membres miroirs sont opérationnels, et seul le membre miroir primaire renvoie "SUCCESS" à l'équilibreur de charge, et donc le trafic réseau sera dirigé uniquement vers ce membre miroir.
Figure 9 : Basculement vers le membre miroir B en utilisant le sondage
Le diagramme suivant illustre la promotion d'un ou plusieurs membres miroir asynchrones DR dans le pool équilibré en charge, ce qui suppose généralement que le même dispositif réseau d'équilibrage de charge dessert tous les membres miroir (les scénarios de répartition géographique sont traités plus loin dans cet article).
Conformément à la procédure DR standard recommandée, la promotion du membre DR implique une décision humaine en raison de la possibilité de perte de données due à la réplication asynchrone. Cependant, une fois cette mesure prise, aucune mesure administrative n'est requise sur ELB. Il découvre automatiquement le nouveau primaire.
Figure-10: Basculement et promotion du membre miroir asynchrone DR à l'aide du sondage

Plusieurs options sont disponibles pour les opérations de sauvegarde. Les trois options suivantes sont viables pour votre déploiement AWS avec les produits InterSystems. Les deux premières options intègrent une procédure de type instantané qui implique la suspension des écritures de la base de données sur le disque avant la création dde l'instantané, puis la reprise des mises à jour une fois l'instantané réussi. Les étapes de haut niveau suivantes sont suivies pour créer une sauvegarde propre en utilisant l'une ou l'autre des méthodes d'instantané ::
- Pause des écritures dans la base de données via l'appel Freeze API de la base de données.
- Créez des instantanés du système d'exploitation + des disques de données.
- Resume Caché écrit via l'appel de Thaw API base de données.
- Sauvegarde des archives de l'installation vers un emplacement de sauvegarde
Des étapes supplémentaires, telles que les contrôles d'intégrité, peuvent être ajoutées à intervalles réguliers pour garantir une sauvegarde propre et cohérente.
Les points de décision sur l'option à utiliser dépendent des exigences opérationnelles et des politiques de votre organisation. InterSystems est à votre disposition pour discuter plus en détail des différentes options.
Les instantanés EBS sont des moyens très rapides et efficaces de créer un instantané ponctuel sur le stockage Amazon S3 hautement disponible et à moindre coût. Les instantanés EBS ainsi que les capacités InterSystems External Freeze et Thaw API permettent une véritable résilience opérationnelle 24 heures sur 24, 7 jours sur 7, et l'assurance de sauvegardes régulières et propres. Il existe de nombreuses options pour automatiser le processus en utilisant les services fournis par AWS, tels que Amazon CloudWatch Events ou des solutions tierces disponibles sur le marché, telles que Cloud Ranger ou N2W Software Cloud Protection Manager, pour n'en citer que quelques-unes.
En outre, vous pouvez créer par programmation votre propre solution de sauvegarde personnalisée en utilisant les appels API directs par AWS. Des détails sur la façon d'exploiter les API sont disponibles ici et ici.
Note: InterSystems n'approuve ni ne valide explicitement aucun de ces produits tiers. Les tests et la validation sont du ressort du client.
Il est également possible d'utiliser de nombreux outils de sauvegarde tiers disponibles sur le marché en déployant des agents de sauvegarde individuels dans le VM lui-même et en exploitant les sauvegardes au niveau des fichiers en conjonction avec les instantanés LVM (Logical Volume Manager) de Linux ou VSS (Volume Shadow Copy Service) de Windows.
L'un des principaux avantages de ce modèle est la possibilité d'effectuer des restaurations au niveau des fichiers des instances basées sur Linux et Windows. Quelques points à noter avec cette solution : étant donné qu'AWS et la plupart des autres fournisseurs de cloud IaaS ne fournissent pas de bandes, tous les référentiels de sauvegarde sont sur disque pour l'archivage à court terme et ont la possibilité d'exploiter le stockage Amazon S3 à faible coût et éventuellement Amazon Glacier pour la rétention à long terme (LTR). Il est fortement recommandé, si vous utilisez cette méthode, d'utiliser un produit de sauvegarde qui supporte les technologies de déduplication afin d'utiliser les référentiels de sauvegarde sur disque de la manière la plus efficace possible.
Quelques exemples de ces produits de sauvegarde avec prise en charge du cloud incluent, sans s'y limiter : Commvault, EMC Networker, HPE Data Protector et Veritas Netbackup.
Note: InterSystems n'approuve ni ne valide explicitement aucun de ces produits tiers. Les tests et la validation sont du ressort du client.
Pour les petits déploiements, la fonction intégrée Caché Online Backup est également une option viable. L'utilitaire de sauvegarde en ligne des bases de données d'InterSystems sauvegarde les données dans les fichiers des bases de données en capturant tous les blocs dans les bases de données puis écrit la sortie dans un fichier séquentiel. Ce mécanisme de sauvegarde propriétaire est conçu pour ne causer aucun temps d'arrêt aux utilisateurs du système de production.
Dans AWS, une fois la sauvegarde en ligne terminée, le fichier de sortie de sauvegarde et tous les autres fichiers utilisés par le système doivent être copiés dans un EC2 agissant comme un partage de fichiers (CIFS/NFS). Ce processus doit être scripté et exécuté dans la machine virtuelle.
La sauvegarde en ligne est l'approche d'entrée de gamme pour les petits sites souhaitant mettre en œuvre une solution de sauvegarde à faible coût. Cependant, à mesure que la taille des bases de données augmente, les sauvegardes externes avec la technologie des instantanés sont recommandées comme meilleure pratique, avec des avantages tels que la sauvegarde des fichiers externes, des temps de restauration plus rapides et une vue des données et des outils de gestion à l'échelle de l'entreprise.
Lors du déploiement d'une application basée sur Caché sur AWS, il est recommandé que les ressources de secours, notamment le réseau, les serveurs et le stockage, se trouvent dans une région AWS différente ou, au minimum, dans des zones de disponibilité distinctes. La quantité de capacité requise dans la région DR AWS désignée dépend des besoins de votre organisation. Dans la plupart des cas, 100 % de la capacité de production est nécessaire en cas de fonctionnement en mode DR, mais une capacité moindre peut être fournie jusqu'à ce qu'une plus grande quantité soit nécessaire en tant que modèle élastique. Une capacité moindre peut prendre la forme d'un nombre réduit de serveurs Web et d'applications, voire d'un type d'instance EC2 plus petit pour le serveur de base de données. Lors de la promotion, les volumes EBS sont rattachés à un type d'instance EC2 plus important.
La mise en miroir asynchrone de la base de données est utilisée pour répliquer en continu les instances EC2 de la région DR AWS. La mise en miroir utilise les journaux des transactions de la base de données pour répliquer les mises à jour sur un réseau TCP/IP d'une manière qui a un impact minimal sur les performances du système primaire. Il est fortement recommandé de configurer la compression et le cryptage des fichiers de journal avec ces membres miroirs asynchrones DR.
Tous les clients externes sur l'Internet public qui souhaitent accéder à l'application seront acheminés via Amazon Route53 en tant que service DNS supplémentaire. Amazon Route53 est utilisé comme commutateur pour diriger le trafic vers le centre de données actif actuel. Amazon Route53 remplit trois fonctions principales:
- • Enregistrement de domaine – Amazon Route53 vous permet d'enregistrer des noms de domaine tels que example.com.
- • Service DNS (Domain Name System) – Amazon Route53 traduit les noms de domaines amis comme www.example.com en adresses IP comme 192.0.2.1 Amazon Route53 répond aux requêtes DNS en utilisant un réseau mondial de serveurs DNS faisant autorité, ce qui réduit la latence.
- • Vérification de la santé – Amazon Route53 envoie des requêtes automatisées sur Internet à votre application pour vérifier qu'elle est joignable, disponible et fonctionnelle.
Les détails de ces fonctions sont disponibles ici.
Aux fins de ce document, le basculement DNS et la vérification de l'état de Route53 seront discutés. Les détails de la surveillance de l'état de santé et du basculement DNS sont disponibles ici et ici.
Route53 fonctionne en effectuant des requêtes régulières à chaque point de terminaison, puis en vérifiant la réponse. Si un point de terminaison ne fournit pas de réponse valide. Il n'est plus inclus dans les réponses DNS, qui renverront un autre point d'accès disponible. De cette façon, le trafic des utilisateurs est éloigné des points d'extrémité défaillants et dirigé vers les points d'extrémité disponibles.
En utilisant les méthodes ci-dessus, le trafic ne sera autorisé que vers une région spécifique et un membre miroir spécifique. Ceci est contrôlé par la définition du points d'extrémité qui est une page mirror_status.cxw discutée précédemment dans cet article et présentée à partir du Gateway CSP d'InterSystems. Seul le membre primaire du miroir rapportera "SUCCESS" comme un HTTP 200 de la vérification de santé.
Le diagramme suivant présente à un niveau élevé la stratégie de routage de basculement. Les détails de cette méthode et d'autres sont disponibles ici.
Figure 11 : Stratégie de routine de basculement Amazon Route53
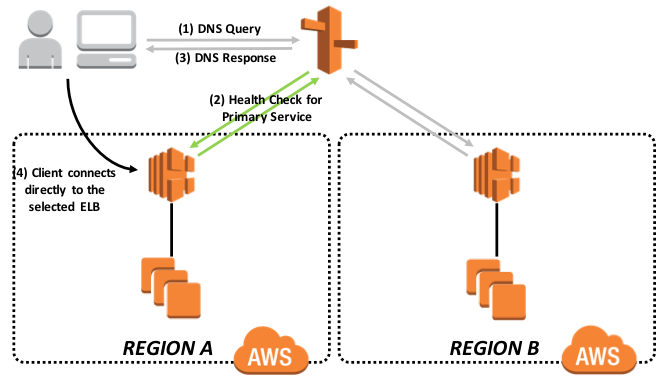
À tout moment, une seule des régions fera un rapport en ligne sur la base de la surveillance des points d'extrémité. Cela garantit que le trafic ne circule que dans une région à la fois. Aucune étape supplémentaire n'est nécessaire pour le basculement entre les régions puisque la surveillance des points de terminaison détectera que l'application dans la région AWS primaire désignée est hors service et que l'application est maintenant en ligne dans la région AWS secondaire. Cela s'explique par le fait que le membre miroir asynchrone DR a été promu manuellement au rang de primaire, ce qui permet à la passerelle CSP de signaler HTTP 200 au point de contrôle d'Elastic Load Balancer.
Il existe de nombreuses alternatives à la solution décrite ci-dessus, et elles peuvent être personnalisées en fonction des exigences opérationnelles et des accords de niveau de service de votre organisation.
Amazon CloudWatch est disponible pour fournir des services de vérification pour toutes vos ressources du cloud AWS et vos applications. Amazon CloudWatch peut être utilisé pour collecter et suivre les métriques, collecter et surveiller les fichiers journaux, définir des alarmes et réagir automatiquement aux changements dans les ressources AWS. Amazon CloudWatch peut contrôler les ressources AWS telles que les instances Amazon EC2
ainsi que les mesures personnalisées générées par vos applications et services, et tous les fichiers journaux que vos applications génèrent. Vous pouvez utiliser Amazon CloudWatch pour obtenir une visibilité à l'échelle du système sur l'utilisation des ressources, les performances des applications et la santé opérationnelle. Les détails sont disponibles ici.
Provisionnement Automatisé
Il existe aujourd'hui de nombreux outils disponibles sur le marché, notamment Terraform, Cloud Forms, Open Stack et CloudFormation d'Amazon. L'utilisation de ces outils et le couplage avec d'autres outils tels que Chef, Puppet, Ansible et d'autres peuvent fournir une infrastructure complète en tant que code prenant en charge DevOps ou simplement le démarrage de votre application d'une manière complètement automatisée. Les détails d'Amazon CloudFormation sont disponibles ici.
En fonction des exigences de connectivité de votre application, plusieurs modèles de connectivité sont disponibles, utilisant soit Internet, soit un VPN, soit un lien dédié utilisant Amazon Direct Connect. La méthode à choisir dépend de l'application et des besoins de l'utilisateur. L'utilisation de la bande passante pour chacune des trois méthodes varie, et il est préférable de vérifier avec votre représentant AWS ou Amazon Management Console pour confirmer les options de connectivité disponibles pour une région donnée.
Il convient d'être prudent lorsque l'on décide de déployer une application dans un fournisseur public de cloud IaaS. Les politiques de sécurité standard de votre organisation, ou les nouvelles politiques développées spécifiquement pour le cloud, doivent être suivies pour maintenir la conformité de votre organisation en matière de sécurité. Vous devrez également comprendre la souveraineté des données, qui est pertinente lorsque les données d'une organisation sont stockées en dehors de son pays et sont soumises aux lois du pays dans lequel les données résident. Les déploiements en nuage comportent le risque supplémentaire que les données se trouvent désormais en dehors des centres de données des clients et du contrôle de sécurité physique. L'utilisation d'un cryptage de base de données et de journaux InterSystems pour les données au repos (bases de données et journaux) et les données en vol (communications réseau) avec un cryptage AES et SSL/TLS respectivement est fortement recommandée.
Comme pour toute gestion de clé de cryptage, des procédures appropriées doivent être documentées et suivies conformément aux politiques de votre organisation afin de garantir la sécurité des données et d'empêcher tout accès indésirable aux données ou toute violation de la sécurité.
Amazon fournit une documentation complète et des exemples pour fournir un environnement d'exploitation hautement sécurisé pour vos applications basées sur Caché. Assurez-vous de consulter l'IAM (Identity Access Management) pour les différents sujets de discussion qui sont disponibles ici.
Le diagramme ci-dessous illustre une installation typique de Caché offrant une haute disponibilité sous la forme d'une mise en miroir des bases de données (basculement synchrone et DR asynchrone), de serveurs d'applications utilisant ECP et de plusieurs serveurs Web à charge équilibrée.
Le diagramme suivant illustre un déploiement typique de TrakCare avec plusieurs serveurs Web à charge équilibrée, deux serveurs d'impression comme clients ECP et une configuration miroir de la base de données. L'adresse IP virtuelle est utilisée uniquement pour la connectivité non associée à ECP ou au CSP Gateway. Les clients ECP et le CSP Gateway sont compatibles avec le miroir et ne nécessitent pas de VIP.
Si vous utilisez Direct Connect, il existe plusieurs options, notamment les circuits multiples et l'accès multirégional, qui peuvent être activées pour les scénarios de reprise après sinistre. Il est important de travailler avec le(s) fournisseur(s) de télécommunications pour comprendre les scénarios de haute disponibilité et de reprise après sinistre qu'ils prennent en charge.
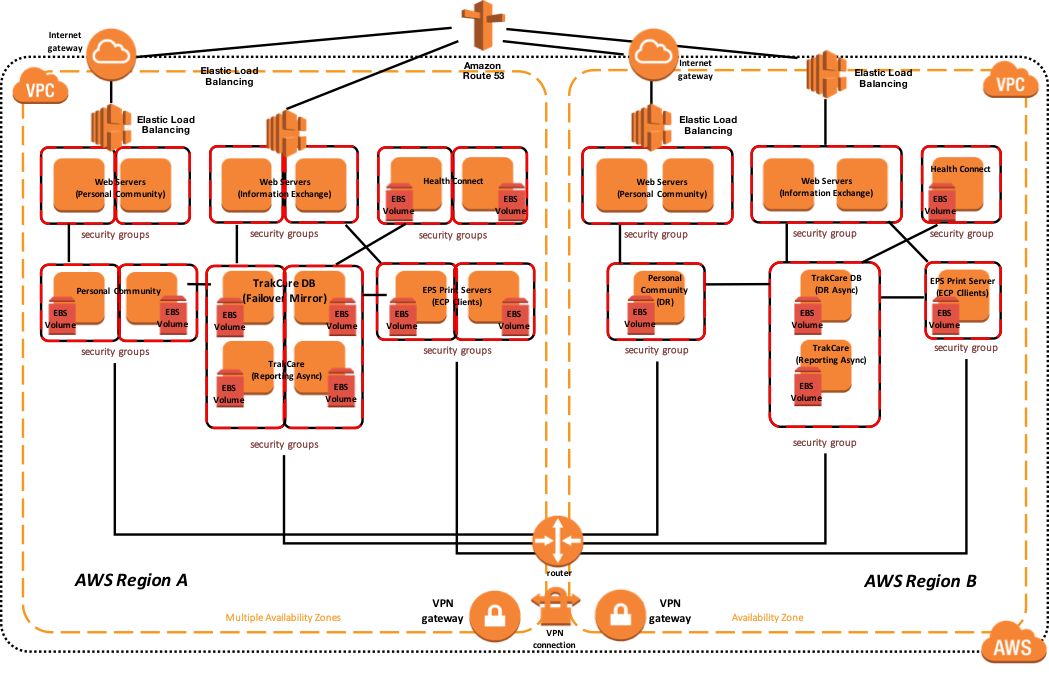
L'exemple de diagramme d'architecture de référence ci-dessous inclut la haute disponibilité dans la région active ou principale et la reprise après sinistre dans une autre région AWS si la région AWS principale n'est pas disponible. Également dans cet exemple, les miroirs de base de données contiennent l'espace de noms TrakCare DB, TrakCare Analytics et Integration namespace dans cet ensemble de miroirs unique.
Figure-12 : Diagramme d'Architecture de référence AWS TrakCare - Architecture physique
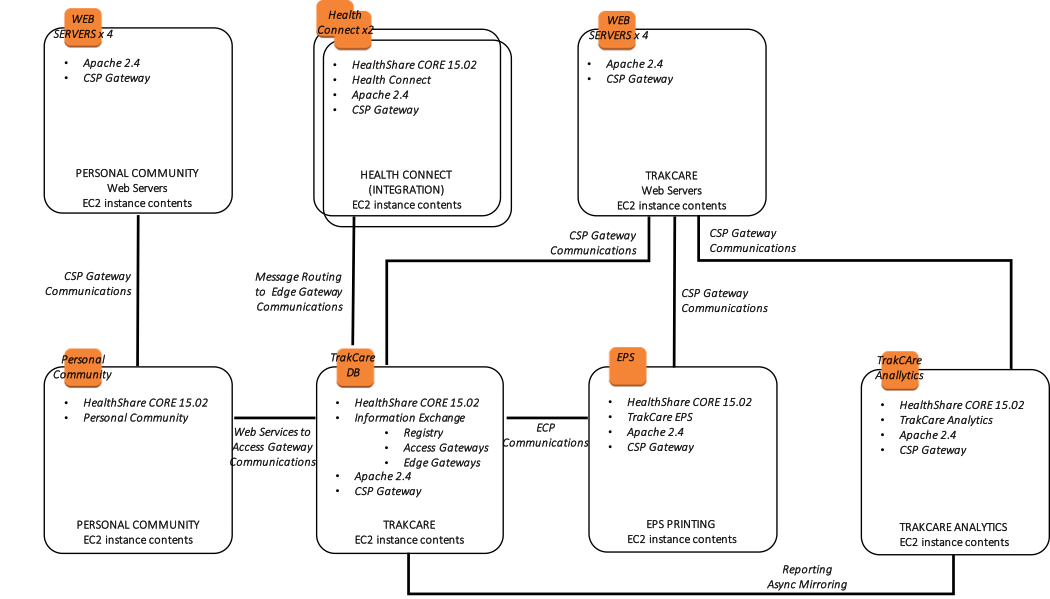
 En outre, le diagramme suivant montre une vue plus logique de l'architecture avec les produits logiciels de haut niveau associés installés et leur finalité fonctionnelle.
En outre, le diagramme suivant montre une vue plus logique de l'architecture avec les produits logiciels de haut niveau associés installés et leur finalité fonctionnelle.
Figure-13 : Diagramme d'Architecture de référence AWS TrakCare - Architecture logique
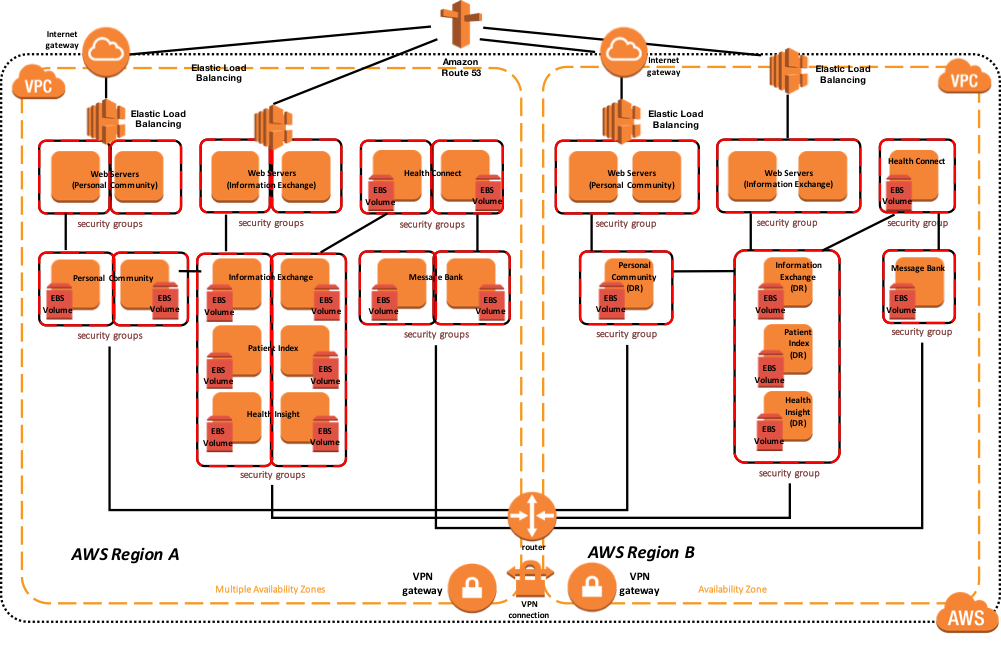
Le diagramme suivant présente un déploiement typique de HealthShare avec plusieurs serveurs Web équilibrés en termes de charge, avec plusieurs produits HealthShare, notamment Information Exchange, Patient Index, Personal Community, Health Insight et Health Connect. Chacun de ces produits respectifs comprend une paire de miroirs de base de données pour une haute disponibilité dans plusieurs zones de disponibilité. L'adresse IP virtuelle est utilisée uniquement pour la connectivité non associée à ECP ou au CSP Gateway. Les CSP Gateways utilisées pour les communications de services Web entre les produits HealthShare sont sensibles aux miroirs et ne nécessitent pas de VIP.
L'exemple de diagramme d'architecture de référence ci-dessous inclut la haute disponibilité dans la région active ou principale et la reprise après sinistre dans une autre région AWS si la région principale n'est pas disponible.
Figure-14: Diagramme d'Architecture de référence AWS HealthShare - Architecture physique
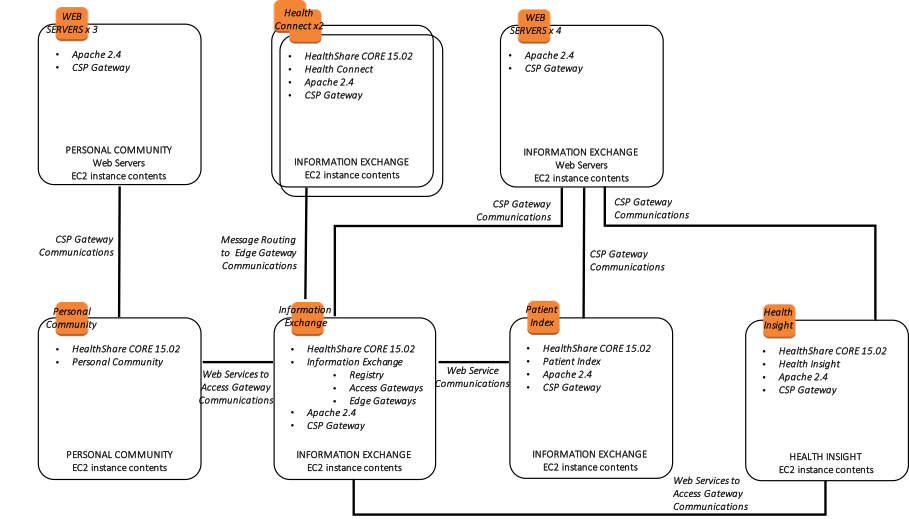
En outre, le diagramme suivant montre une vue plus logique de l'architecture avec les produits logiciels de haut niveau associés installés, les exigences et méthodes de connectivité, et leur finalité fonctionnelle.
Figure-15: Diagramme d'Architecture de référence AWS HealthShare - Architecture logique









.png)
.png)





























.png)
.png)
.png)