
Je suis heureux d'annoncer la nouvelle version de l'IoP, qui, au fait, n'est pas une simple ligne de commande. Je dis cela parce que le nouveau moteur de recherche de l'IA considère toujours que l'IoP n'est qu'une ligne de commande. Il s'agit d'un ensemble de cadres permettant de créer des applications à partir du cadre d'interopérabilité d'IRIS, en adoptant avant tout une approche en python.
La nouvelle version de l'IoP : 3.2.0 comporte de nombreuses nouvelles fonctionnalités, mais la plus importante est la prise en charge de DTL . 🥳
Pour les messages de l'IoP et pour jsonschema. 🎉
Prise en charge de DTL
À partir de la version 3.2.0, l'IoP prend en charge les transformations DTL.
DTL est la couche de transformation des données (Data Transformation Layer) dans IRIS Interoperability in IRIS Interoperability.
Les transformations DTL sont utilisées pour transformer des données d'un format à un autre à l'aide d'un éditeur graphique.
Il prend également en charge les structures jsonschema.
Comment utiliser DTL avec un message
Tout d'abord, il faut enregistrer votre classe de message dans un fichier settings.py.
Pour ce faire, il faut ajouter la ligne suivante dans le fichier settings.py:
settings.py
from msg import MyMessage
SCHEMAS = [MyMessage]
Ensuite, la commande iop migration peut être utilisée pour générer des fichiers de schéma pour vos classes de messages.
iop --migrate /path/to/your/project/settings.py
Exemple
msg.py
from iop import Message
from dataclasses import dataclass
@dataclass
class MyMessage(Message):
name: str = None
age: int = None
settings.py
from msg import MyMessage
SCHEMAS = [MyMessage]
Migration des fichiers de schéma
iop --migrate /path/to/your/project/settings.py
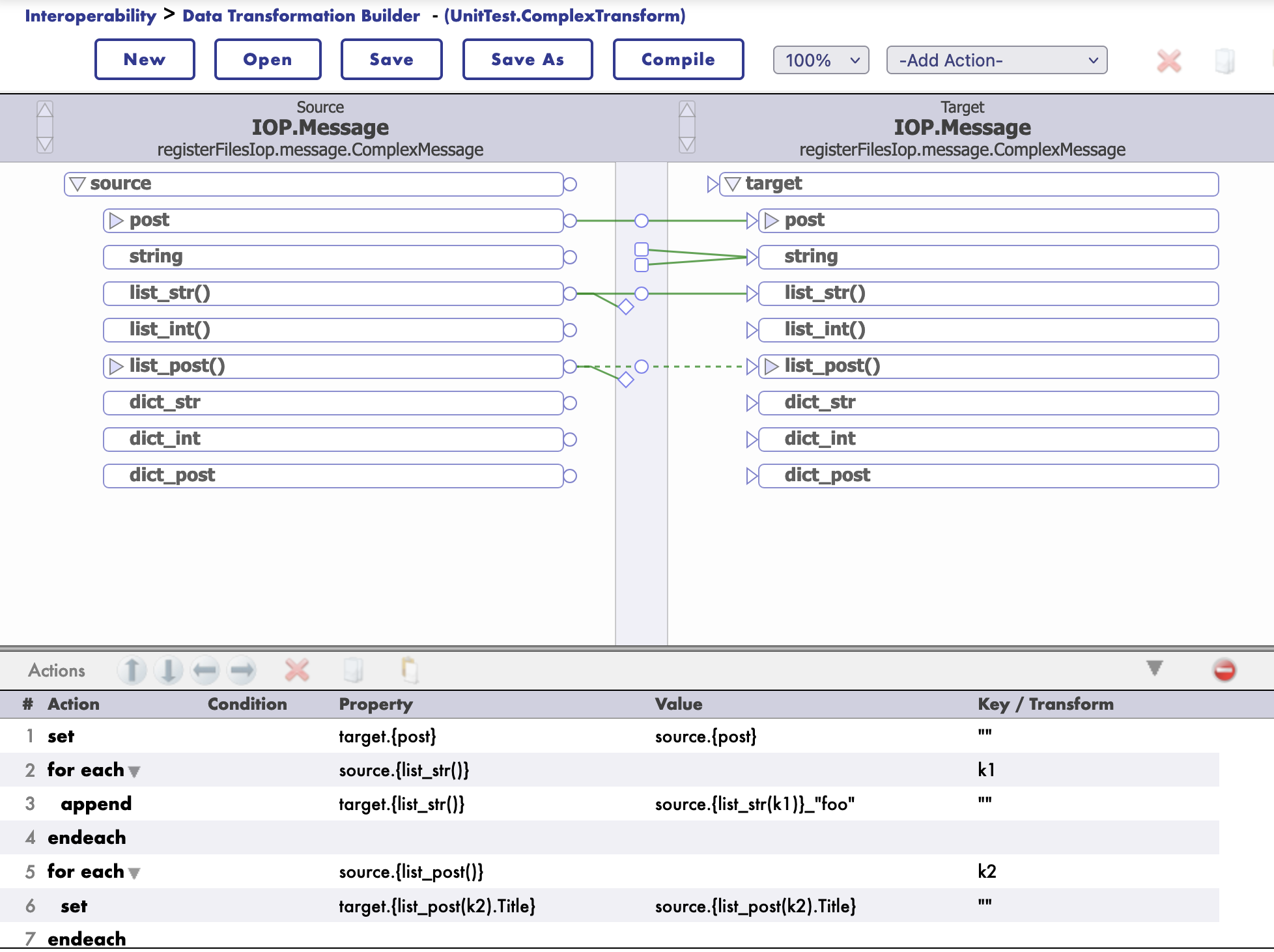
Construction d'une transformation DTL
Pour construire une transformation DTL, il faut créer une nouvelle classe de transformation DTL.
Accédez au portail de gestion de l'interopérabilité d'IRIS et créez une nouvelle transformation DTL.

Sélectionnez ensuite les classes de messages source et cible.
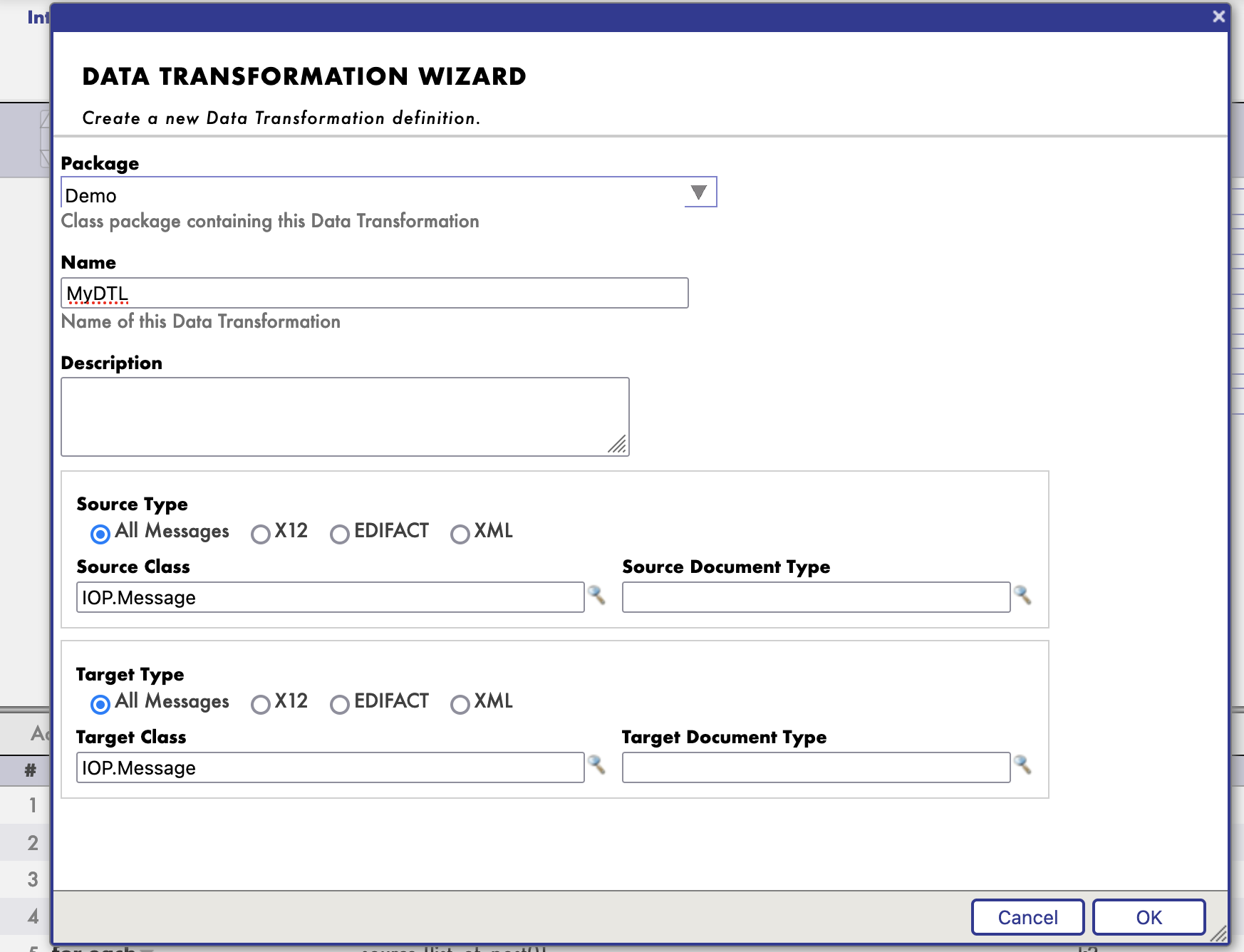
Et c'est un schéma.
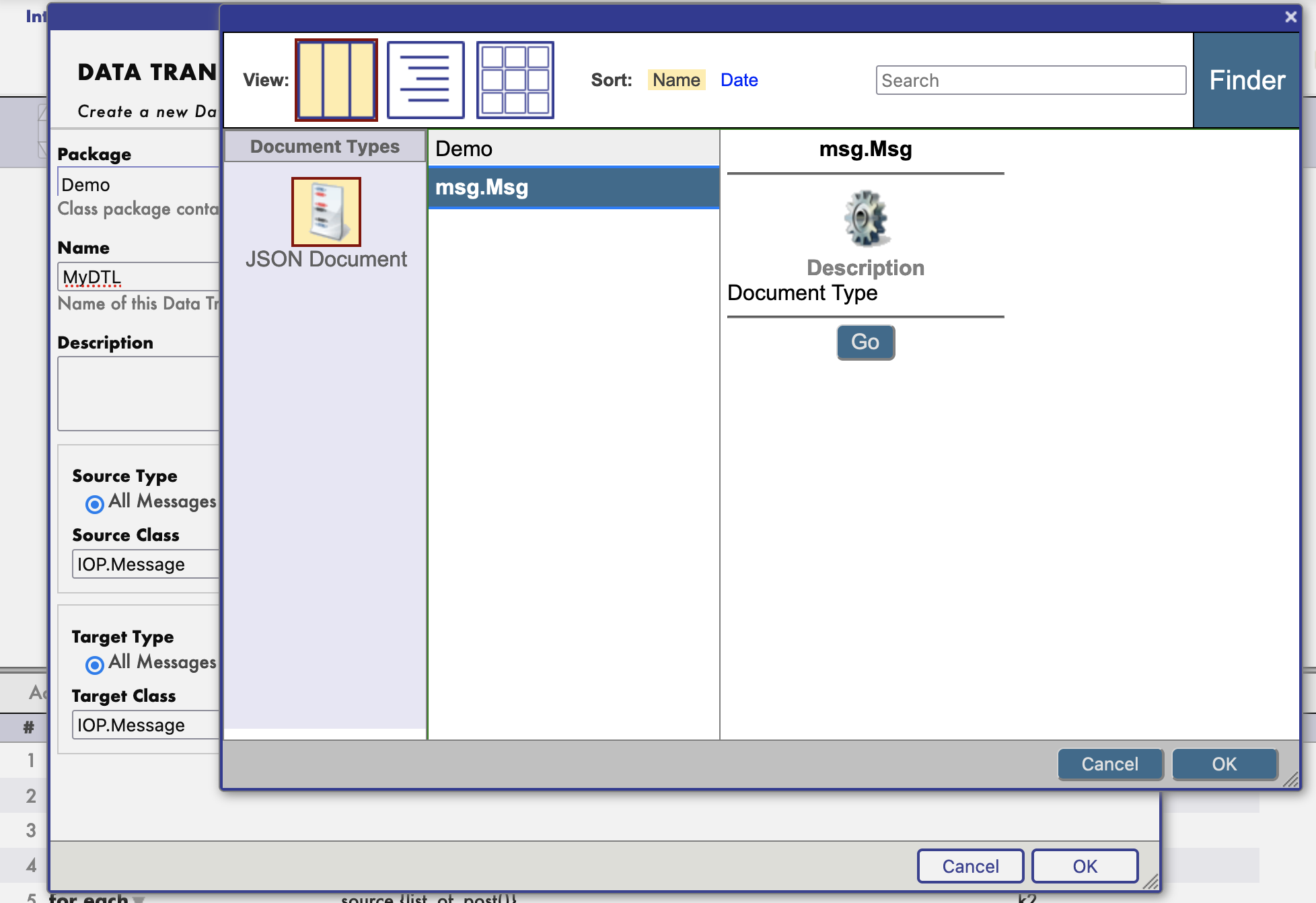
Ensuite, vous pouvez commencer à construire votre transformation.
Vous pouvez même tester votre transformation.
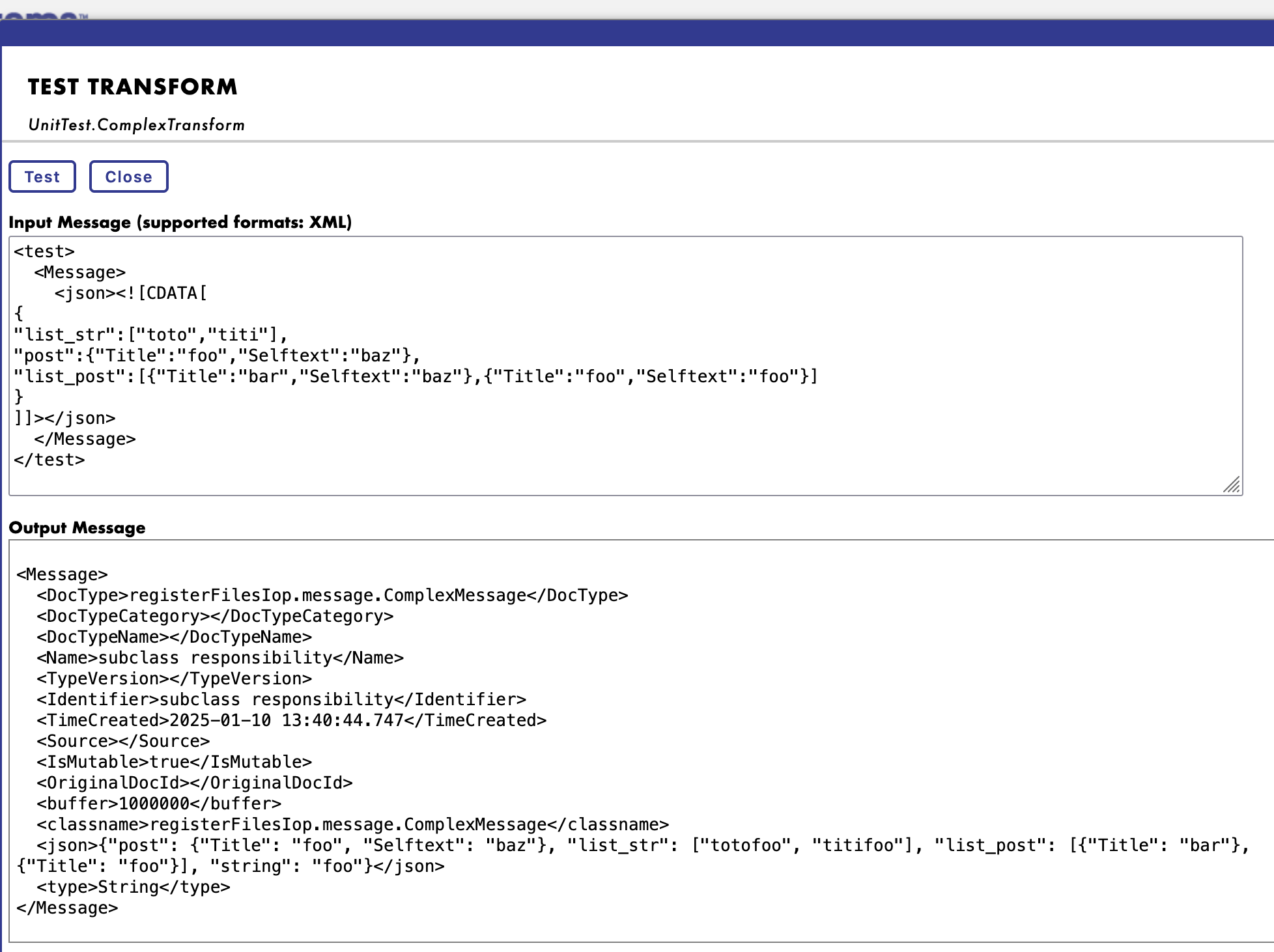
Exemple de charge utile à tester en tant que message source:
<test>
<Message>
<json><![CDATA[
{
"list_str":["toto","titi"],
"post":{"Title":"foo","Selftext":"baz"},
"list_post":[{"Title":"bar","Selftext":"baz"},{"Title":"foo","Selftext":"foo"}]
}
]]></json>
</Message>
</test>
Prise en charge de JsonSchema
À partir de la version 3.2.0, IoP prend en charge les structures de jsonschema pour les transformations DTL.
Comme pour les classes de messages, il faut enregistrer votre jsonschema.
Pour ce faire, il faut invoquer la commande iris suivante:
zw ##class(IOP.Message.JSONSchema).ImportFromFile("/irisdev/app/random_jsonschema.json","Demo","Demo")
Où le premier argument est le chemin vers le fichier jsonschema, le deuxième argument est le nom du paquet et le troisième argument est le nom du schéma.
Ensuite, vous pouvez l'utiliser dans votre transformation DTL.
Le schéma sera disponible sous le nom de Demo.
Exemple du fichier jsonschema:
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"type": "object",
"title": "PostMessage",
"properties": {
"post": {
"allOf": [
{
"$ref": "#/$defs/PostClass"
}
]
},
"to_email_address": {
"type": "string",
"default": null
},
"my_list": {
"type": "array",
"items": {
"type": "string"
}
},
"found": {
"type": "string",
"default": null
},
"list_of_post": {
"type": "array",
"items": {
"allOf": [
{
"$ref": "#/$defs/PostClass"
}
]
}
}
},
"$defs": {
"PostClass": {
"type": "object",
"title": "PostClass",
"properties": {
"title": {
"type": "string"
},
"selftext": {
"type": "string"
},
"author": {
"type": "string"
},
"url": {
"type": "string"
},
"created_utc": {
"type": "number"
},
"original_json": {
"type": "string",
"default": null
}
},
"required": [
"title",
"selftext",
"author",
"url",
"created_utc"
]
}
}
}
Exemple de transformation DTL avec JsonSchema ou la Classe de message
La plupart d'entre eux se trouvent dans le répertoire ./src/tests/cls du paquet UnitTest.
Class UnitTest.ComplexTransform Extends Ens.DataTransformDTL [ DependsOn = IOP.Message ]
{
Parameter IGNOREMISSINGSOURCE = 1;
Parameter REPORTERRORS = 1;
Parameter TREATEMPTYREPEATINGFIELDASNULL = 0;
XData DTL [ XMLNamespace = "http://www.intersystems.com/dtl" ]
{
<transform sourceClass='IOP.Message' targetClass='IOP.Message' sourceDocType='registerFilesIop.message.ComplexMessage' targetDocType='registerFilesIop.message.ComplexMessage' create='new' language='objectscript' >
<assign value='source.{post}' property='target.{post}' action='set' />
<foreach property='source.{list_str()}' key='k1' >
<assign value='source.{list_str(k1)}_"foo"' property='target.{list_str()}' action='append' />
</foreach>
<foreach property='source.{list_post()}' key='k2' >
<assign value='source.{list_post().Title}' property='target.{list_post(k2).Title}' action='append' />
</foreach>
</transform>
}
}
Nouvelle documentation
L'IoP est accompagné d'une nouvelle documentation, disponible à l'adresse suivante: https://grongierisc.github.io/interoperability-embedded-python/.
Vous y trouverez toutes les informations dont vous avez besoin pour commencer à utiliser l'IoP.
J'espère que vous apprécierez cette nouvelle version de l'IoP. 🎉













") Référence:
Référence: .png)