###
Bonjour à la communauté,
Dans cet article, je vais démontrer l'utilisation d'Embedded Python, nous allons couvrir les sujets suivants :
- 1-Aperçu d'Embedded Python
- 2-Utilisation d'Embedded Python
- 2.1- Utilisation d'une bibliothèque Python à partir d'ObjectScript
- 2.2- Appel des API d'InterSystems à partir de Python
- 2.3- Utilisation conjointe d'ObjectScript et de Python
- 3-Utilisation des fonctions intégrées de python
- 4-Modules et bibliothèques Python
- 5-Les cas d'utilisation d'Embedded Python
- 5.1- Impression d'un PDF en utilisant la bibliothèque Python Reportlab
- 5.2- Création d'un code QR à l'aide de la bibliothèque Python Qrcode
- 5.3- Obtention de la localisation GEO à l'aide de la bibliothèque Python Folium
- 5.4- Générer et marquer des emplacements sur une carte interactive en utilisant biblithèque** **Python Folium
- 5.5- Analyse de données à l'aide de la biblithèque Python Pandas
- 6-Résumé
Commençons donc par un aperçu

1-Aperçu d'Embedded Python
Python intégré est une fonctionnalité de la plateforme de données InterSystems IRIS qui permet aux développeurs Python d'obtenir un accès complet et direct aux données et aux fonctionnalités d'InterSystems IRIS.
InterSystems IRIS est livré avec un puissant langage de programmation intégré appelé ObjectScript qui est interprété, compilé et exécuté à l'intérieur de la plate-forme de données.
Comme ObjectScript s'exécute dans le contexte d'InterSystems IRIS, il a un accès direct à la mémoire et aux appels de procédure de la plate-forme de données.
Python intégré est une extension du langage de programmation Python qui permet l'exécution du code Python dans le contexte du processus InterSystems IRIS.
Comme ObjectScript et Python opèrent tous deux sur la même mémoire objet, on peut dire que les objets Python ne se contentent pas d'émuler des objets ObjectScript, mais qu'ils sont des objets ObjectScript.
La coégalité de ces langages signifie qu'il est possible de choisir le langage le plus approprié pour le travail, ou le langage que l'on est le plus à l'aise à utiliser pour écrire des applications.

2-Utilisation d'Embedded Python
Lorsque vous utilisez Python intégré, vous pouvez écrire votre code selon trois modalités différentes.
2.1 - Utilisation d'une bibliothèque Python à partir d'ObjectScript
Tout d'abord, vous pouvez écrire un fichier .py ordinaire et l'appeler à partir du contexte IRIS d'InterSystems. Dans ce cas, la plateforme de données lancera le processus Python et vous permettra d'importer un module appelé IRIS, qui attache automatiquement le processus Python au noyau IRIS et vous donne accès à toutes les fonctionnalités d'ObjectScript à partir du contexte de votre code Python.
.png)
2.2 - Appel des API d'InterSystems à partir de Python
Deuxièmement, vous pouvez écrire du code ObjectScript ordinaire et instancier un objet Python à l'aide du paquet %SYS.Python. Ce paquet ObjectScript vous permet d'importer des modules et des bibliothèques Python, puis de travailler avec cette base de code à l'aide de la syntaxe ObjectScript.
Le paquet %SYS.Python permet aux développeurs ObjectScript sans aucune connaissance de Python d'utiliser le riche écosystème des bibliothèques Python dans leur code ObjectScript.
.png)
2.3 - Utilisation conjointe d'ObjectScript et de Python
Troisièmement, vous pouvez créer une définition de classe InterSystems et écrire des méthodes en Python. Tout appel à cette méthode lancera l'interpréteur Python. Cette méthode a l'avantage de remplir le mot-clé self de ce bloc de code Python d'une référence à l'instance de la classe qui le contient. En outre, en utilisant Python pour écrire des méthodes de classe dans les classes InterSystems, vous pouvez facilement mettre en œuvre des méthodes qui gèrent différents événements de saisie de données en SQL, tels que l'ajout d'une nouvelle ligne à un tableau.
Cela permet également de développer rapidement des procédures stockées personnalisées en Python.
.png)
Comme vous pouvez le constater, Python intégré vous permet de choisir le langage de programmation le mieux adapté à la tâche sans compromettre les performances.

3-Utilisation des fonctions intégrées de python
L'interpréteur Python a un certain nombre de fonctions et de types intégrés qui sont toujours disponibles. Ils sont répertoriés ici par ordre alphabétique.
<colgroup><col><col><col><col></colgroup> |
Fonctions integrées
|
|---|
|
A abs() aiter() all() any() anext() ascii() B bin() bool() breakpoint() bytearray() bytes() C callable() chr() classmethod() compile() complex() D delattr() dict() dir() divmod()
| <td>
E enumerate() eval() exec() F filter() float() format() frozenset() G getattr() globals() H hasattr() hash() help() hex() I id() input() int() isinstance() issubclass() iter()
</td>
<td>
L len() list() locals() M map() max() memoryview() min() N next() O object() oct() open() ord() P pow() print() property()
</td>
<td>
R range() repr() reversed() round() S set() setattr() slice() sorted() staticmethod() str() sum() super() T tuple() type() V vars() Z zip() _ __import__()
</td>
****Utilisation des fonctions intégrées de python
Pour utiliser les fonctions intégrées de Python, nous avons besoin d'importer "builtins", puis nous pouvons invoquer la fonction
set builtins = ##class(%SYS.Python).Import("builtins")
La fonction print() de Python est en fait une méthode du module intégré, de sorte que vous pouvez maintenant utiliser cette fonction à partir d'ObjectScript :
USER>do builtins.print("hello world!")
hello world!
USER>set list = builtins.list()
USER>zwrite list
list=5@%SYS.Python ; [] ;
De même, la méthode help() permet d'obtenir de l'aide sur l'objet liste.
USER>do builtins.help(list)
L'aide sur l'objet liste:
classe list(object)
| list(iterable=(), /)
|
| Séquence mutable intégrée.
|
| Si aucun argument n'est donné, le constructeur crée une nouvelle liste vide.
| L'argument doit être un itérable s'il est spécifié.
|
| Les méthodes définies ici :
|
| __add__(self, value, /)
| Renvoi de la valeur+self.
|
| __contains__(self, key, /)
| Renvoi de la clé dans self.
|
| __delitem__(self, key, /)
| Suppression de la [clé] self.
##
4-Modules et bibliothèques Python
Certains modules ou bibliothèques python sont installés par défaut et déjà disponibles. La fonction help("module") permet de visualiser ces modules :
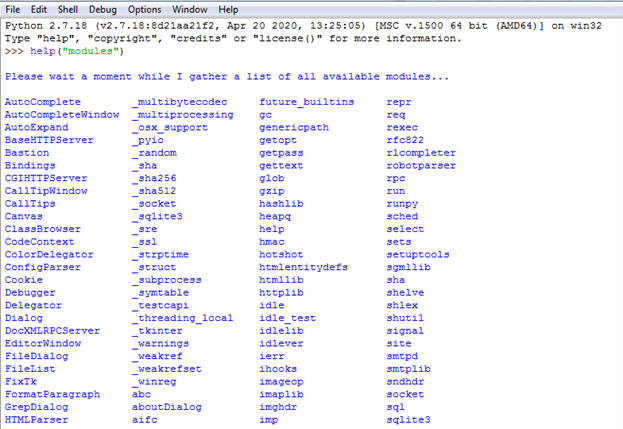

Installation d'un module ou d'une bibliothèque python
Outre ces modules, python a des centaines de modules ou de bibliothèques, qui peuvent être consultés sur pypi.org( L' Indice de Paquet Python (PyPI) est un dépôt de logiciels pour le langage de programmation Python).
.png)
Si nous avons besoin d'autres bibliothèques, nous devons les installer à l'aide de la commande intersystems irispip.
Par exemple, Pandas est une bibliothèque d'analyse de données en python. La commande suivante utilise le programme d'installation de paquets irispip pour installer pandas sur un système Windows :
C:\InterSystems\IRIS\bin>irispip install --target C:\InterSystems\IRIS\mgr\python pandas
Veuillez noter que C:\NInterSystems sera remplacé par le répertoire d'installation d'Intersystems.

5-Les cas d'utilisation d'Embedded Python
5.1-Impression d' un PDF en utilisant la bibliothèque Python Reportlab
Nous devons installer la bibliothèque Reportlab à l'aide de la commande irispip, puis créer une fonction objectcript.
Compte tenu de l'emplacement d'un fichier, la méthode ObjectScript suivante, intitulée CreateSamplePDF(), crée un exemple de fichier PDF et l'enregistre à cet emplacement.
Class Demo.PDF
{
ClassMethod CreateSamplePDF(fileloc As%String) As%Status
{
set canvaslib = ##class(%SYS.Python).Import("reportlab.pdfgen.canvas")
set canvas = canvaslib.Canvas(fileloc)
do canvas.drawImage("C:\Sample\isc.png", 150, 600)
do canvas.drawImage("C:\Sample\python.png", 150, 200)
do canvas.setFont("Helvetica-Bold", 24)
do canvas.drawString(25, 450, "InterSystems IRIS & Python. Perfect Together.")
do canvas.save()
}
}
La première ligne de la méthode importe le fichier canvas.py du sous-paquet pdfgen de ReportLab. La deuxième ligne de code instancie un objet Canvas et procède ensuite à l'appel de ses méthodes, de la même manière qu'elle appellerait les méthodes de n'importe quel objet IRIS d'InterSystems.
Vous pouvez ensuite appeler la méthode de la manière habituelle :
do ##class(Demo.PDF).CreateSamplePDF("C:\Sample\hello.pdf")
Le PDF suivant est généré et enregistré à l'emplacement spécifié :


5.2-Création d'un code QR à l'aide de la bibliothèque Python Qrcode Library
Pour générer un code QR, nous devons installer la bibliothèque Qrcode en utilisant la commande irispip, puis en utilisant le code ci-dessous, nous pouvons générer un code QR:
.png)

5.3-Obtention de la localisation GEO à l'aide de la bibliothèque Python Folium
Pour obtenir des données géographiques, nous devons installer la bibliothèque Folium à l'aide de la commande irispip, puis créer la fonction de script objet ci-dessous :
Class dc.IrisGeoMap.Folium Extends%SwizzleObject
{
ClassMethod GetGeoDetails(addr As%String) [ Language = python ]
{
from geopy.geocoders import Nominatim
geolocator = Nominatim(user_agent="IrisGeoApp")
try:
location = geolocator.geocode(addr)
print("Location:",location.point)
print("Address:",location.address)
point = location.point
print("Latitude:", point.latitude)
print("Longitude:", point.longitude)
except:
print("Not able to find location")
}
}
Connectez-vous au terminal IRIS et exécutez le code suivant
do ##class(dc.IrisGeoMap.Folium).GetGeoDetails("Cambridge MA 02142")
Le résultat sera le suivant ::

 ********
********
5.4-Générer et marquer des emplacements sur une carte interactive en utilisant biblithèque Python Folium
Nous utiliserons la même bibliothèque Python Folium pour générer et marquer des emplacements sur une carte interactive, la fonction de script objet ci-dessous fera le travail souhaité :
ClassMethod MarkGeoDetails(addr As%String, filepath As%String) As%Status [ Language = python ]
{
import folium
from geopy.geocoders import Nominatim
geolocator = Nominatim(user_agent="IrisGeoMap")
#split address in order to mark on the map
locs = addr.split(",")
if len(locs) == 0:
print("Veuillez saisir l'adresse")
elif len(locs) == 1:
location = geolocator.geocode(locs[0])
point = location.point
m = folium.Map(location=[point.latitude,point.longitude], tiles="OpenStreetMap", zoom_start=10)
else:
m = folium.Map(location=[20,0], tiles="OpenStreetMap", zoom_start=3)
for loc in locs:
try:
location = geolocator.geocode(loc)
point = location.point
folium.Marker(
location=[point.latitude,point.longitude],
popup=addr,
).add_to(m)
except:
print("Impossible de trouver l'emplacement : ",loc)
map_html = m._repr_html_()
iframe = m.get_root()._repr_html_()
fullHtml = """
"""
fullHtml = fullHtml + iframe
fullHtml = fullHtml + """
"""try:
f = open(filepath, "w")
f.write(fullHtml)
f.close()
except:
print("Impossible d'écrire dans un fichier")
}
Connectez-vous au terminal IRIS et invoquez la fonction MarkGeoDetails
Nous invoquerons la fonction MarkGeoDetails() de la classe dc.IrisGeoMap.Folium.
La fonction nécessite deux paramètres :
- location/locations(Nous pouvons passer plusieurs lieux en ajoutant "," entre les deux)
- fichier HTML de trajet
Exécutons la commande suivante pour marquer Cambridge MA 02142, NY, Londres, UAE, Jeddah, Lahore, et Glasgow sur la carte et l'enregistrer en tant que fichier "irisgeomap_locations.html".
do ##class(dc.IrisGeoMap.Folium).MarkGeoDetails("Cambridge MA 02142,NY,London,UAE,Jeddah,Lahore,Glasgow","d:\irisgeomap_locations.html")
Le code ci-dessus génère le fichier HTML interactif suivant********:********
##
********
5.5-Analyse de données à l'aide de la biblithèque Python Pandas
Nous devons installer la bibliothèque Pandas à l'aide de la commande irispip, puis nous pouvons utiliser le code ci-dessous pour visualiser les données.
******** ********.png)

6-Résumé
Python intégré d'InterSystems (IEP) est une fonctionnalité puissante qui vous permet d'intégrer du code Python de manière transparente dans vos applications InterSystems. Grâce à IEP, vous pouvez exploiter les nombreuses bibliothèques et cadres disponibles en Python pour améliorer la fonctionnalité de vos applications InterSystems. Dans cet article, nous allons explorer les fonctionnalités et les avantages clés d'IEP.
IEP est mis en œuvre sous la forme d'un ensemble de bibliothèques qui vous permettent d'interagir avec des objets Python et d'exécuter du code Python à partir d'applications InterSystems. Il s'agit d'un moyen simple et efficace d'intégrer du code Python dans vos applications InterSystems, ce qui vous permet d'effectuer des analyses de données, de l'apprentissage automatique, du traitement du langage naturel et d'autres tâches qui peuvent être difficiles à mettre en œuvre dans ObjectScript d'InterSystems.
L'un des principaux avantages de l'utilisation d'IEP est qu'il permet de faire le lien entre les mondes de Python et d'InterSystems. Il est ainsi facile d'utiliser les points forts des deux langages pour créer des applications puissantes qui combinent le meilleur des deux mondes.
IEP permet également d'étendre les fonctionnalités de vos applications InterSystems en exploitant les capacités de Python. Cela signifie que vous pouvez tirer parti du grand nombre de bibliothèques et de cadres disponibles en Python pour effectuer des tâches qui pourraient être difficiles à mettre en œuvre dans ObjectScript d'InterSystems.
Python intégré d'InterSystems offre un moyen puissant d'étendre les fonctionnalités de vos applications InterSystems en exploitant les capacités de Python. En intégrant du code Python dans vos applications InterSystems, vous pouvez profiter du grand nombre de bibliothèques et de cadres disponibles dans Python pour effectuer des tâches complexes qui pourraient être difficiles à mettre en œuvre dans ObjectScript d'Intersystems.
Merci!
.jpg)
 Une fois connecté, la page suivante devrait s'afficher. Cliquez sur "Télécharger la version Community Edition" pour commencer le téléchargement du kit d'installation:
Une fois connecté, la page suivante devrait s'afficher. Cliquez sur "Télécharger la version Community Edition" pour commencer le téléchargement du kit d'installation:
.png)
.png)
.png)
.png)
.png)
.png)
![Une activité de code issue d'une transformation de données DTL, avec le langage défini sur Python. Le contenu du champ de code indique bidders = [bid.User for bid in source.Lot.Bids()]. New line. bidders = set(bidders). New line. target.NumOutbid = (len(bidders) - 1).](https://fr.dc-dev10.demo.community.intersystems.com/sites/default/files/inline/images/images/image(10933).png)

.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png) ):
):.png)
.png)
.png)
.png)
.png)
.png)
.png)


.png)
.png)
.png)
.png) sur le côté gauche en bas de l'écran, en sélectionnant les configurations, et en cliquant sur "Ouvrir les paramètres (JSON)" ("Open Settings (JSON)")
sur le côté gauche en bas de l'écran, en sélectionnant les configurations, et en cliquant sur "Ouvrir les paramètres (JSON)" ("Open Settings (JSON)") .png) sur le côté droit en haut de l'écran.
sur le côté droit en haut de l'écran..png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png) dans le coin supérieur droit de l'écran pour changer les côtés des fichiers : la source sera la cible et vice versa.
dans le coin supérieur droit de l'écran pour changer les côtés des fichiers : la source sera la cible et vice versa..png)

.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)




.png)


.png)
.png)
.png)
 )
).png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
 Après l'installation, des icônes d'extension apparaissent sur le côté ou en bas de l'éditeur de code.
Après l'installation, des icônes d'extension apparaissent sur le côté ou en bas de l'éditeur de code.
 Il est indispensable au travail d'équipe !
Il est indispensable au travail d'équipe !